검색결과 리스트
공대생의 팁에 해당되는 글 123건
- 2020.09.12 Chernoff bound(체르노프 유계)
- 2020.09.11 wget 사용시 증명서(certificate) 관련 문제가 발생하였을 때 해결방법
- 2020.09.10 WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법 1
- 2020.08.15 모션 증폭(Motion Magnification)
- 2020.07.05 VMware 가상머신에서 실제 프린터를 연결하는 방법
- 2020.06.03 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 35
- 2020.05.16 Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 4
- 2020.04.30 VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) 2
- 2020.03.01 Winsorization(윈저화)
- 2020.02.10 ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법
- 2020.01.03 Generalized Estimating Equations(일반화 추정 방정식)
- 2019.11.06 Surrogate model(대체 모델)
글
Chernoff bound(체르노프 유계)
체르노프 유계(Chernoff bound)는 마르코프 부등식(Markov's Inequality)과 체비쇼프 부등식(Chebyshyov's Inequality)과 같이 확률분포의 평균만 주어진 경우 또는 평균값과 분산값만 주어졌을때 확률의 상한(Upperbound)을 구할수 있게 하는 것을 목표로 합니다. 다시 말해, 평균이 특정 구간 내에 포함될 확률에 대한 정보를 제공하는 것을 목표로 합니다.
먼저 정의를 보인 후 간단한 증명을 한 다음 예제를 통해 체르노프 유계를 이해해보도록 합시다.
정의
\(X\)가 \(1\leq i\leq n\) 구간에서 \(X_i\in\{0,1\}\)이고 \(P(X_i=1)=p_i\)일 때 \(E[X_i]=p_i\)라고 합시다.
\(X\)가 독립 랜덤변수, 즉 \(X=\sum^n_{i=1}X_i\)일 때 \(\mu\)는 \(X\)의 평균이라 하였을때
$$When\;\delta>0\;\begin{cases}P(X>(1+\delta)\mu) <(\frac{e^\delta}{(1+\delta)^{(1+\delta)}})^{\mu}\\P(X<(1-\delta)\mu) < (\frac{e^{-\delta}}{(1-\delta)^{(1-\delta)}})^\mu\end{cases}$$
이를 그림으로 나타내면 다음과 같습니다.
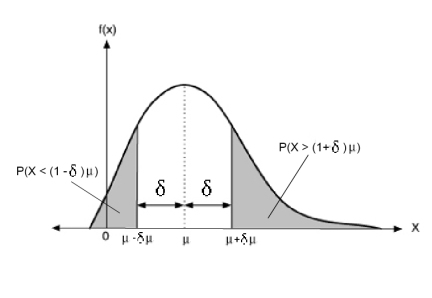
위 그래프를 보면 아시듯이 체르노프 유계는 평균을 중심으로 하여 \(\delta\)만큼 떨어진 구간에서부터 끝부분 까지의 꼬리 분포(Tail distribution)확률을 나타낸 것입니다. 이를 통해 평균을 기준으로 확률의 상한 및 하한을 알 수 있습니다.
지금부터는 체르노프 유계를 증명하고자 합니다. 증명에 어려움을 느끼시는 분이라면 증명 부분을 건너뛰고 응용 사례를 먼저 보고 오시는 것을 추천 드립니다.
증명
먼저 마르코프 부등식(Marcov's Inequality)에 대한 이해가 필요합니다. 여기서는 체르노프 유계를 이해하기 위한 중요한 부분만을 보여드리고자 하오니 마르코프 부등식에 대해 좀 더 자세하게 알아보고자 하시는 분은 아래의 링크를 통해 확인해주시길 바랍니다.
m.blog.naver.com/PostView.nhn?blogId=mykepzzang&logNo=220838855204
[확률과 통계] 28. 마르코프 부등식과 체비쇼프 부등식, Markov's Inequality & Chebyshev's Inequality
이번 포스팅에서는 확률이론에서 유명한 부등식 두 가지를 설명하려 합니다. 우선 첫 번째 '마르코프 부등...
blog.naver.com
마르코프 부등식에서 랜덤 변수 X가 주어졌을 때
$$For\:any\:random\:variable\:X\geq0$$
$$P(X>\lambda)<\frac{E[X]}{\lambda}$$
$$P(f(X)>f(\lambda))<\frac{E[f(X)]}{f(\lambda)}$$
만약 \(f\)가 감소하지 않는 함수일 때 다음과 같은 공식이 성립됩니다.
$$P(X>\lambda)=P(f(X)>f(\lambda))<\frac{E[f(X)]}{f(\lambda)}$$
다음으로 적률생성함수(Moment Generating Function)을 통해 체르노프 유계를 이해해보도록 하겠습니다. 여기서는 체르노프 유계를 증명하기 위한 방법만 소개드리고자 하오니 적률생성함수에 대해 자세히 알고 싶으신 분은 아래의 자료를 참조해주시기 바랍니다.
m.blog.naver.com/mykepzzang/220846464280
[확률과 통계] 45. 적률과 적률생성함수, Moment & Moment-Generating Function
이번 포스팅에서는 '적률생성함수'를 알아보려고 합니다. 적률생성함수는 확률통계학에서 매우 중요하게 다...
blog.naver.com
적률생성함수를 통해 상한값을 구할 때 다음과 같은 식을 유도할 수 있습니다. 만약 확률변수 X가 베르누이 분포라 가정하였을 때 다음과 같은 식을 유도할 수 있습니다.
$$\begin{split}
E[e^{tX}]&= E[e^{t\sum X_{i}}] \\
&=\sum^n_{x=0}e^{tx}\left(\begin{array}{c}n\\ x\end{array}\right)p^x(1-p)^{n-x}\\
&=\sum^n_{x=0}\left(\begin{array}{c}n\\x\end{array}\right)(pe^t)^x(1-p)^{n-x}\\
&\leq\prod_ie^{p_i(e^t-1)}\\
&=e^{\sum_ip_i(e^t-1)}\\
&=e^{(e^t-1)\mu}
\end{split}$$
※증명
이제 본격적으로 체르노프 유계를 증명해보도록 하겠습니다. 위에서 보여드렸던 마르코프 부등식에 \(\lambda\)를 \((1+\delta)\mu\)로 대입하면 다음과 같은 식이 구해집니다.
$$\begin{split}
P(X>(1+\delta)\mu)&=P(e^{tX}>e^{t(1+\delta)\mu})\\
&\leq\frac{E[e^{tX}]}{e^{t(1+\delta)\mu}}\\
&\leq\frac{e^{(e^t-1)\mu}}{e^{t(1+\delta)\mu}}
\end{split}$$
위의 식을 최소화시키기 위해 t에 다음과 같은 값을 대입합니다.
$$t=ln(1+\delta)$$
이를 식에 넣어 정리하면 다음과 같습니다.
$$\begin{split}
P(X>(1+\delta)\mu)
&\leq\frac{e^{(e^{ln(1+\delta)}-1)\mu}}{e^{(1+\delta)ln(1+\delta)\mu}}\\
&=\left(\frac{e^{(e^{ln(1+\delta)}-1)}}{e^{(1+\delta)ln(1+\delta)}}\right)^\mu\\
&=\left(\frac{e^\delta}{(1+\delta)^{1+\delta}}\right)^\mu
\end{split}$$
위 식을 통해 체르노프 유계의 한쪽 끝부분인 상한을 증명하였습니다. 하한 또한 위의 식으로 갈음할 수 있으므로 주어진 체르노프 유계의 정의는 증명되었음을 확인하였습니다.
응용
지금까지 체르노프 유계의 정의와 증명과정을 살펴보았습니다. 이번에는 체르노프 유계가 어떻게 적용될 수 있는지 살펴보도록 하겠습니다.
아래의 그림은 하나의 집단에서 야구와 축구를 좋아하는 사람들을 나타낸 것입니다.

위 집단에서 좋아하는 운동에 대해 물어보았을 때 축구를 좋아할 확률을 \(p\)라고 하였을 때, 몇명이 축구를 좋아할까요?
그림상으로는 총 인원수가 적기 때문에 금방 알아낼 수 있지만 만약 1만명 이상의 인원을 대상으로 한 사람씩 물어보는 것은 상당히 많은 시간이 소요되기 때문에 사실상 불가능합니다.
최대한 균등하고 독립적으로 임의의 표본으로 n명을 뽑은 다음 \(X=\widetilde{p}n\)으로 계산하여 축구를 좋아하는 인원수를 구할 수 있을 것입니다. 즉, \(\widetilde{p}=\frac{X}{n}\)을 통해 확률 \(p\)를 예측할 수 있을 것으로 기대됩니다.
X가 이항 랜덤 변수로 n회의 베르누이 수행을 하였고 성공확률이 p라고 예상하였을 때 모집단이 표본집단의 크기 n보다 충분히 클 때 다음이 성립됨을 알 수 있습니다.
$$E[X]=np$$
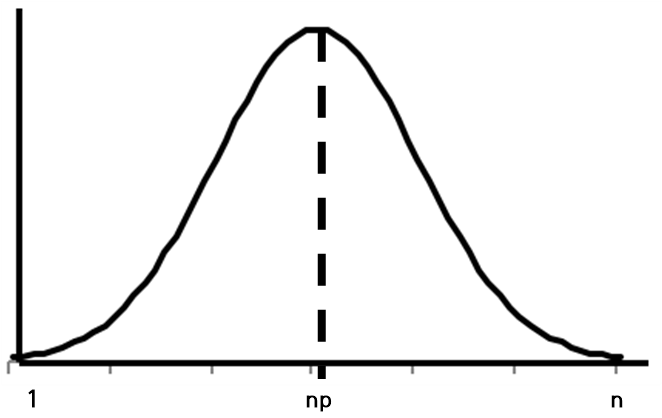
다음과 같이 분포에서 평균 np의 위치를 쉽게 알 수 있습니다. 그렇다면 우리가 예상한 \(p\)가 실제 확률 \(\tilde{p}\)에 얼마나 근접한지 알 수 있을까요?
\(p\)의 신뢰구간 \(1-\gamma\)을 \([\widetilde{p}-\delta,\tilde{p}+\delta]\)라 하였을 때 \(\gamma>0,\:\delta>0\)의 조건에서 다음과 같이 나타낼 수 있습니다.
$$P(p\in[\tilde{p}-\delta,\tilde{p}+\delta])\geq1-\gamma$$
즉 위의 식을 \(\gamma\)에 대해 다음과 같이 나타낼 수 있습니다.
$$P(p<\tilde{p}-\delta)+P(p>\tilde{p}+\delta)<\gamma$$
이번에는 위에서 정의한 \(\gamma\)값에 대해 알아보도록 하겠습니다. 먼저 하한 구간에 대해 다음과 같이 구할 수 있습니다.
$$\begin{split}
P(p<\tilde{p}-\delta) &= P(\tilde{p}>p+\delta)\\
&= P(X>n(p+\delta)) \\
&= P(X>E[X](1+\frac{\delta}{p}))\\
&< e^{-\frac{np(\frac{\delta}{p})^2}{3}}\\
&= e^{-\frac{n\delta^2}{3p}}\\
&\leq e^{-\frac{n\delta^2}{3}}
\end{split}$$
다음으로 상한 구간에 대해 다음과 같이 구할 수 있습니다.
\begin{split}
P(p>\tilde{p}+\delta) &= P(\tilde{p}<p-\delta)\\
&= P(X<n(p-\delta)) \\
&= P(X<E[X](1-\frac{\delta}{p}))\\
&< e^{-\frac{np(\frac{\delta}{p})^2}{2}}\\
&= e^{-\frac{n\delta^2}{2p}}\\
&\leq e^{-\frac{n\delta^2}{2}}
\end{split}
위의 식을 통해 우리는 \(\gamma\)값을 다음과 같이 알아낼 수 있습니다.
$$\gamma=e^{-\frac{n\delta^2}{2}}+e^{-\frac{n\delta^2}{3}}$$
위의 식을 보았을 때 갑자기 자연상수 e의 지수의 분모가 뜬금없이 2 혹은 3이 되어있는 것을 확인하실 수 있습니다. 앞에서 말씀드렸듯이 \(\delta\)는 매우 작은 값이고 위의 부등식을 통해 2 혹은 3을 대입하였을 때 \(\gamma\)의 값이 약간 넓어지면서 예측값 p의 범위가 더욱 타이트해졌음을 보실 수 있습니다. 즉, 편의상 간단하게 2 혹은 3을 대입하여 범위를 한정시킬 수 있어 2 혹은 3으로 대체해도 무방하다는 의미입니다.
즉, 예측값 p를 구하기 위해 우리는 \(\gamma\), \(\delta\)와 n의 값을 조절함으로서 신뢰구간을 조정하여 범위를 한정함으로서 궁극적인 목표인 평균의 특정 구간을 한정함으로서 원하는 결과를 얻을 수 있음을 확인할 수 있습니다.
'공대생의 팁' 카테고리의 다른 글
| MobaXterm에서 X server 사용시 전체화면 모드 화면이 안나올때 해결방법 (1) | 2020.10.25 |
|---|---|
| 여분기여도(Marginal Contribution) (0) | 2020.09.13 |
| wget 사용시 증명서(certificate) 관련 문제가 발생하였을 때 해결방법 (0) | 2020.09.11 |
| WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법 (1) | 2020.09.10 |
| 모션 증폭(Motion Magnification) (0) | 2020.08.15 |
설정
트랙백
댓글
글
wget 사용시 증명서(certificate) 관련 문제가 발생하였을 때 해결방법
github에서 자료를 가져오려 하는 도중 다음과 같은 오류를 맞닥트리게 되었습니다.
ERROR: cannot verify github.com's certificate
Self-signed certificate encountered.
To connect to github..com insecurely, use `--no-check-certificate'.
이 경우는 주로 프록시 보안이 되어있는 네트워크 환경에서 종종 발생하는 경우로서 이는 아래와 같이 증명서를 확인하는 과정을 생략하도록 설정해주시면 되겠습니다.
$ echo "check_certificate = off" >> ~/.wgetrc
위와 같이 wgetrc를 설정한 이후 wget를 실행하면 다운로드가 제대로 진행됨을 확인하실 수 있습니다.
'공대생의 팁' 카테고리의 다른 글
| 여분기여도(Marginal Contribution) (0) | 2020.09.13 |
|---|---|
| Chernoff bound(체르노프 유계) (0) | 2020.09.12 |
| WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법 (1) | 2020.09.10 |
| 모션 증폭(Motion Magnification) (0) | 2020.08.15 |
| VMware 가상머신에서 실제 프린터를 연결하는 방법 (0) | 2020.07.05 |
설정
트랙백
댓글
글
WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법
Windows10에 Ubuntu 20.04 버전을 설치하고 이것 저것 기능들을 다루는 과정에서 다음과 같은 명령어를 접하게 되는 경험을 하였습니다.
qt.qpa.xcb: could not connect to display
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
혹은
Error: Can't open display: :0.0
WSL에 설치된 Ubuntu는 서버컴퓨터에 설치되는 GUI 개념이 없는 버전과 같다고 보시면 됩니다. 단지 CLI(Command-Line Interface) 즉, MS-DOS에서 처럼 명령어를 한 줄 씩 입력해서 처리하는 방식대로 진행된다고 생각하시면 되겠습니다.
흔히 Windows처럼 GUI환경이 제공되는 Ubuntu를 주로 접하셨던 분들께는 Windows10 환경에서 사용하게 되셨을때 마치 Ubuntu 데스크탑버전에서 처럼 Terminal을 켜고 사용하던 습관이 있어 위와 같은 에러가 발생하였을 때 상당히 당황하실거라고 생각됩니다.
해결방법은 매우 간단합니다. Windows10에서도 Ubuntu의 GUI 기능이 동작할 수 있도록 해주는 X11 지원 프로그램을 설치해줌으로서 해결할 수 있습니다.
이를 Windows에서 지원해줄 수 있는 프로그램으로 Xming이 있습니다. Xming 설치 프로그램은 아래의 사이트를 통해 다운받으신 다음 설치하실 수 있습니다.
https://sourceforge.net/projects/xming/
만약 자신의 WSL에 X11 관련 패키지가 설치되셨다면 바로 화면을 불러오실 수 있습니다. 만약 Xming을 설치하고 나서도 화면에 창이 나타나지 않으시는 분들께서는 아래의 사이트를 참조하시길 바랍니다.
[WSL] Windows Subsystem for Linux - 디스플레이 서버 설정 및 GUI 사용하기 - ECE - TUWLAB
WSL에는 기본적으로 디스플레이 관련 기능이 포함되어 있지 않아서 GUI 기반 어플리케이션은 사용할 수 없다. 하지만, GUI 관련 기능이 서버-클라이언트 구조로 확실하게 분리되어 구현된 리눅스��
www.tuwlab.com
'공대생의 팁' 카테고리의 다른 글
| Chernoff bound(체르노프 유계) (0) | 2020.09.12 |
|---|---|
| wget 사용시 증명서(certificate) 관련 문제가 발생하였을 때 해결방법 (0) | 2020.09.11 |
| 모션 증폭(Motion Magnification) (0) | 2020.08.15 |
| VMware 가상머신에서 실제 프린터를 연결하는 방법 (0) | 2020.07.05 |
| 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 (35) | 2020.06.03 |
설정
트랙백
댓글
글
모션 증폭(Motion Magnification)
사람들은 훌륭한 눈을 갖고 있습니다. 특정한 물체의 변화를 감지하고 이를 감지할 수 있는 능력을 충분히 갖고 있습니다. 그럼에도 바람에 의한 건물의 흔들림 혹은 사람의 표정과 같이 미세한 변화를 탐지하는 것은 상당히 어렵고 실제로 이를 맨눈으로 분별하는 사람은 거의 손에 꼽을 정도로 없으리라 생각합니다.

위 사진을 보았을 때 여러분께서는 그네를 타고 움직이는 모습을 확실하게 확인하실 수 있습니다. 다음에는 사진을 한 번 볼까요?

혹시 이전 사진과의 차이점을 발견하셨나요? 만약 차이점을 찾지 못하셨더라도 걱정하지 않으셔도 됩니다. 이전의 사진에 익숙해져 차이를 찾는 것이 상당히 어려우실 수 있습니다.
위의 사진들에서 보신바와 같이 그네를 탄 사람처럼 움직임에 큰 변화가 있을 경우 우리는 이를 쉽게 파악할 수 있습니다. 그러나 그네를 지탱하는 부분과 같이 움직임이 매우 작을 때엔 이를 인지하는 것 조차 어렵습니다. 이번 포스팅에서 소개해드릴 모션 증폭(Motion Magnification)은 미세한 움직임을 말 그대로 증폭시켜 그네를 지탱하는 부분이 움직였음을 사진을 통해 파악할 수 있게 해주는 기술입니다. 그렇다면 이러한 모션 증폭 기술은 어떻게 해당 부분의 변화를 파악하고 이를 나타낼 수 있는 것일까요?
연구 배경
노후화된 설비를 점검할 때 문제를 분석하기 위해 진동감지 센서를 부착하거나 초음파를 측정 하는 등의 방법으로 정밀하게 분석하는 방법들이 있습니다. 이러한 방법을 사용할 경우 원인을 직접적으로 분석하므로 매우 좋은 방법이라 할 수 있습니다. 그러나 크기가 큰 건물과 같은 거대한 설비를 분석하기 위해서는 상당히 많은 양의 센서가 필요하며 초음파 측정 또한 각 위치별로 수행하에는 물리적, 시간적 비용이 발생하기 마련입니다.
모션 증폭은 이러한 각종 장비를 사용하지 않고도 카메라 기반이 시각 정보를 통해 촬영된 영상에서 이미지의 미세한 변화를 분석하고 이를 이미지에 표시함으로서 사람의 눈으로 변화를 확인할 수 있도록 하는 것을 목표로 하고 있습니다.
동작 원리
영상에서 작은 모션을 찾아낸 후 이를 증폭시키기 위해 기준 프레임(Reference frame)으로부터 관측된 픽셀 강도의 변화로부터 입력 영상의 궤적(Trajectory)을 찾아내 이를 이미지에 반영하는 것을 목표로 합니다. 이를 위해 다음과 같은 5가지 과정이 적용됩니다.
1. 영상 준비

모션 증폭 알고리즘을 적용하기 위해서는 영상을 촬영하는 카메라가 특정 시점에 지속적으로 고정되어 있어야 합니다. 만약 카메라가 진동하거나 움직이게 된다면 카메라에 촬영된 물체가 아닌 카메라의 떨림이 적용될 수 있기 때문이지요.
영상의 노출 변화에 의해 발생되는 밝기의 변화를 보정하고 움직임을 완벽하게 고정시킨다면 모션 분석의 준비는 끝납니다.
2. 특징점 궤적 클러스터 분석

입력된 영상의 이미지를 비교하여 미묘한 변화가 발생한 부분을 분석하여 특징점의 궤도를 분석하고 이동 경향이 같은 특징점을 하나의 클러스터로 분석합니다,
3. 분할(레이어 배정)

클러스터 단위로 분류된 특징점 궤적으로부터 기준 프레임의 각 픽셀 정보에서 모션 궤적을 얻는 과정을 진행합니다. 특징점 클러스터에 해당되는 부분을 별개의 독립된 레이어로 적용하면 다음과 같은 레이어들로 분류됨을 확인할 수 있습니다.
4. 선택된 클러스터의 움직임을 증폭

레이어가 결정되었다면 모션 증폭을 적용하기 위한 레이어를 정의합니다.
각 레이어에서 미세한 변화를 감지한 클러스터의 궤적 변화가 있던 부분들이 검게 나타납니다 해당 부분에 대해 보간법(Interpolate)을 활용하여 해당 부분을 메꿉니다.
5. 영상에 적용

위의 과정을 통해 적용된 모션 증폭을 영상에 적용합니다. 배경 레이어는 모든 프레임에 대해 변경되는 부분은 없으므로 해당 픽셀들을 우선 적용한 다음 이상치(Outlier)에 적용된 픽셀들을 적용합니다. 끝으로 선택되지 않은 나머지 레이어에 대해 적용을 하면 아래와 같이 모션 증폭이 적용된 이미지를 얻을 수 있습니다.
위와 같은 방법을 통해 특정 영상에서 직접 확인하기 어려웠던 미세한 변화를 감지하고 이를 이미지에 나타냄으로서 영상 증폭 기술이 적용될 수 있었습니다. 다음으로 이러한 모션 증폭 알고리즘이 적용된 사례에 대하여 소개해 드리도록 하겠습니다.
오일러 영상 증폭(Eulerian Video Magnification)
영상에 나오는 사람의 얼굴을 통해 맥박수를 측정할 수 있다고 하면 믿어지시는지요? 먼저 아래의 영상을 보도록 합시다.
영상에서 보시는 바와 같이 심장이 뛸 때 마다 피가 얼굴로 전달되는 모습이 맨눈으로는 거의 보이지 않지만 영상 증폭 기술을 통해 색 변화가 나타남을 분명하게 파악하실 수 있습니다. 또한 자고 있는 아기의 호흡 장면을 증폭하여 아이가 숨을 제대로 쉬고 있는지도 확인할 수 있습니다.

이 그림은 위의 영상에서 확인하셨던 영상 증폭 기술에서 사용된 프레임워크의 구조도입니다. 입력된 이미지를 분리한 다음 시간 처리(Temporal Processing)과정에서 특정한 필터를 적용한 다음 분리된 이미지를 다시 합쳤을 때 모션 증폭이 적용된 영상을 확인할 수 있습니다.
이 기술에 적용되는 필터는 사용자가 직접 설정할 수 있으며 영상에 따라 적합한 주피수를 찾는다면 미세한 움직임을 더 정확하게 확인할 수 있을 것으로 기대됩니다.
학습 기반 영상 모션 증폭(Learning-based Video Motion Magnification)
위에서 말씀드린 바와 같이 특정 영상에 가장 적합한 필터를 적용하였을 때 모션이 잘 포착되는 것을 확인하실 수 있었습니다. 그렇다면 이러한 필터를 가장 적합하게 찾을 수 있는 방법은 무엇일까요? 직접 해당 주파수를 일일히 찾아서 하는 방법밖에 없는걸까요?
포스텍 전자공학과 오태현 교수님이 제안한 학습 기반의 영상 모션증폭 알고리즘은 사람이 직접 최적화된 필터를 찾는 과정을 인공신경망 기반의 CNN 알고리즘으로 이미지를 학습하여 최적화된 모션 증폭 영상을 얻을 수 있도록 하는 알고리즘을 구상하였습니다.

위의 그림에서 보시는 바와 같이 위의 원본 이미지에서 아래쪽은 증폭 영상의 이미지를 나타냅니다. 왼쪽의 경우 기존의 모션증폭 알고리즘으로 아기 옷의 주변에 잔상같은 것이 남아 있는 것을 볼 수 있습니다. 반면 오른쪽의 경우 주변 잔상이 제거된 깔끔한 모습을 보실 수 있습니다.
지금까지 보신 바와 같이 모션 증폭 기능을 적용하여 사람의 눈으로 확인하기 어려웠던 미세한 변화를 쉽게 확인할 수 있으며 인공지능을 적용하여 원하는 부분만 증폭할 수 있던 것을 확인하였습니다. 이 기술을 실제 적용하게 된다면 별도의 감지 센서 설치 없이 카메라만으로 미세한 변화를 감지할 수 있을 것으로 기대됩니다.
- 참고자료
LIU, Ce, et al. Motion magnification. ACM transactions on graphics (TOG), 2005, 24.3: 519-526.
Motion Magnification
people.csail.mit.edu
Eulerian Video Magnification
SIGGRAPH 2012 Eulerian Video Magnification for Revealing Subtle Changes in the World An example of using our Eulerian Video Magnification framework for visualizing the human pulse. (a) Four frames from the original video sequence. (b) The same four frames
people.csail.mit.edu
Learning-based Video Motion Magnification
Motion Magnification While our model learns spatial decomposition filters from synthetically generated inputs, it performs well on real videos with results showing less ringing artifacts and noise. [Left] the crane sequence magnified 75× with the same tem
people.csail.mit.edu
'공대생의 팁' 카테고리의 다른 글
| wget 사용시 증명서(certificate) 관련 문제가 발생하였을 때 해결방법 (0) | 2020.09.11 |
|---|---|
| WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법 (1) | 2020.09.10 |
| VMware 가상머신에서 실제 프린터를 연결하는 방법 (0) | 2020.07.05 |
| 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 (35) | 2020.06.03 |
| Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 (4) | 2020.05.16 |
설정
트랙백
댓글
글
VMware 가상머신에서 실제 프린터를 연결하는 방법
가상머신에서 작업하였던 내용을 출력하고자 할 때 이를 PDF로 변환하여 클라우드 등을 통해 호스트 운영체제에 연결된 프린터를 통해 자료를 출력할 수 있기에 굳이 가상머신에서 프린터를 바로 사용하는 경우는 흔치 않습니다.
그런데 저의 경우 등본이나 가족관계증명서와 같이 각종 프로그램을 설치해서 접속해야 하는 경우가 있는데 이전에 ActiveX 시절과 같이 평소 쓸데없는 프로그램들이 설치되는 것을 원치 않아 가상머신을 통해 일을 처리하는 경우가 많습니다.

심지어 어떤 경우는 가상프린터를 통한 증명서 발급을 금지하고 있어 실제 프린터가 연결되어야만 발급되는 경우가 있습니다. 이를 해결하기 위해 가상머신에서도 프린터를 사용할 수 있도록 설정하는 과정에 대해 여러분들께 설명을 드리고자 합니다.
1. 가상머신에서 프린터를 사용할 수 있도록 설정한다.
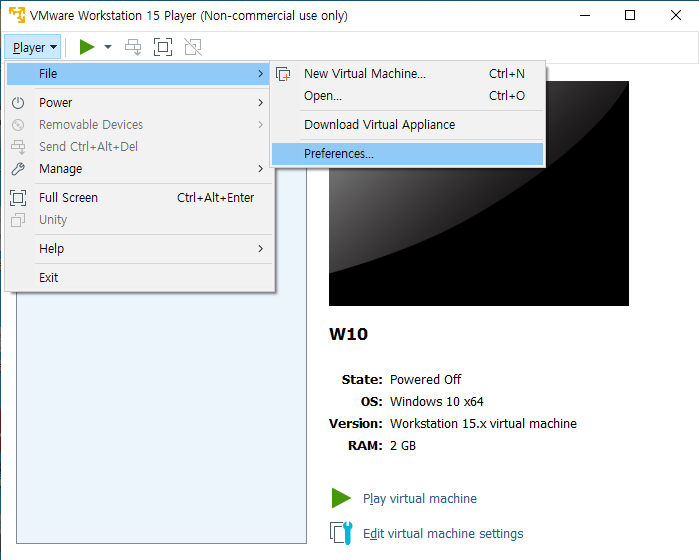



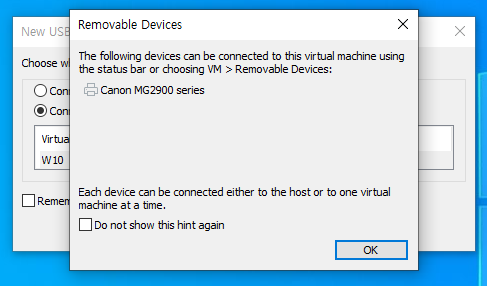
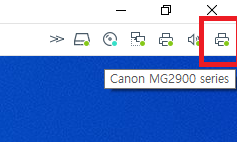

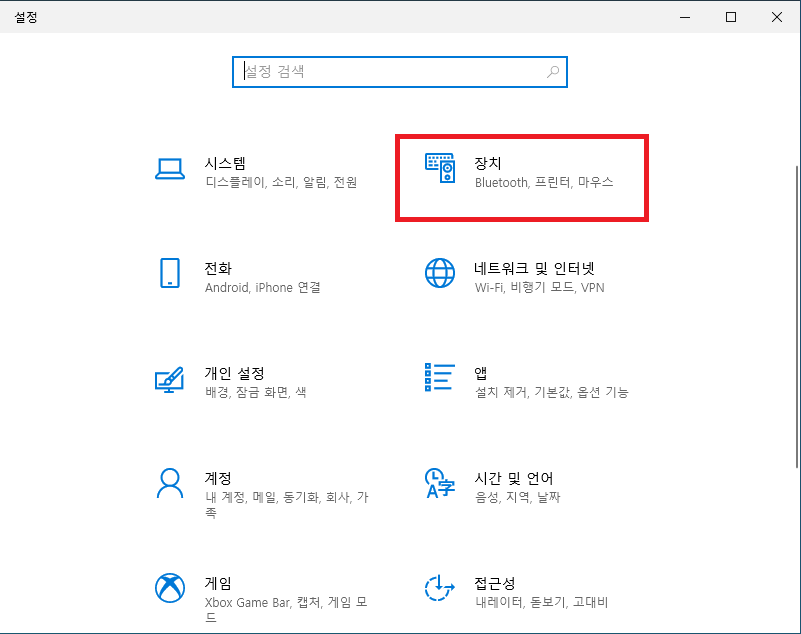

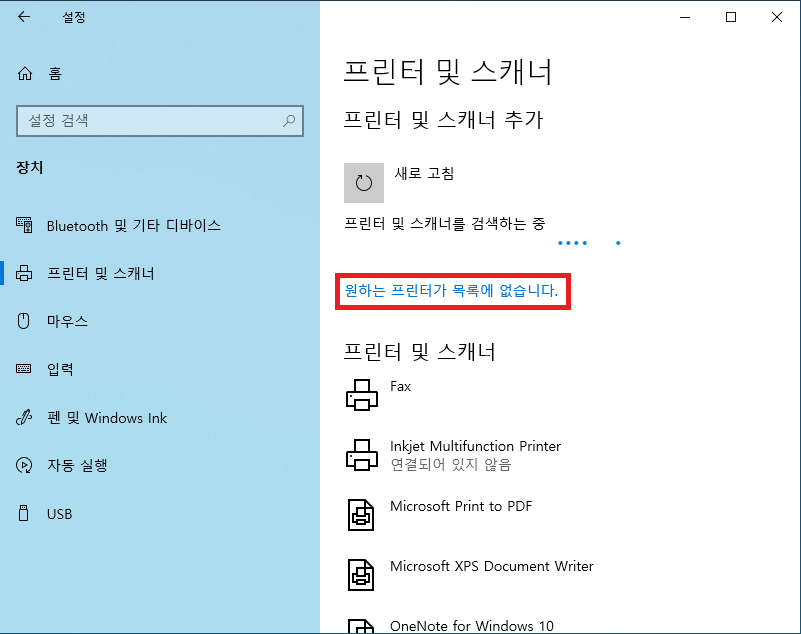

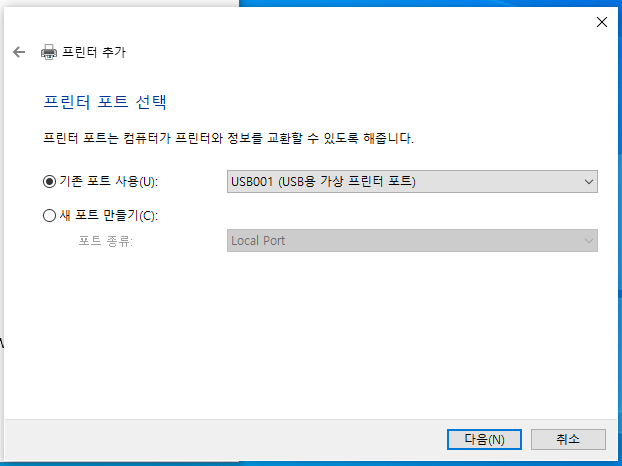
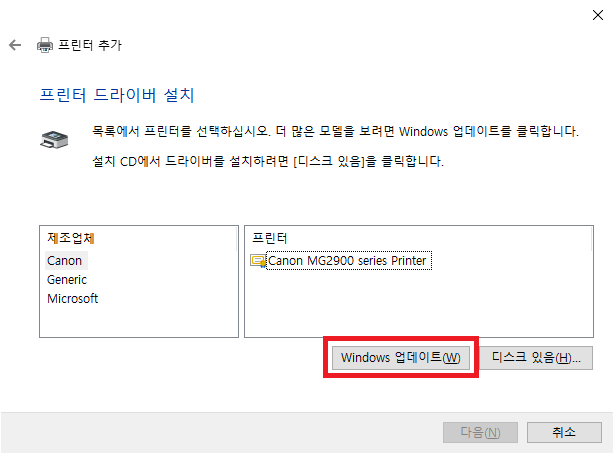

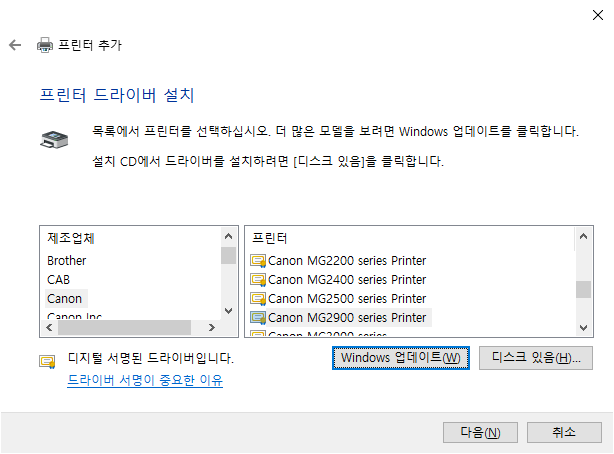
위와 같은 과정을 통해 여러분의 가상머신 환경에서도 실제 프린터를 통해 문서를 출력할 수 있게 됩니다!
'공대생의 팁' 카테고리의 다른 글
| WSL(Windows Subsystem for Linux )에서 'Can't open display: :0.0' 오류 발생시 해결방법 (1) | 2020.09.10 |
|---|---|
| 모션 증폭(Motion Magnification) (0) | 2020.08.15 |
| 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 (35) | 2020.06.03 |
| Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 (4) | 2020.05.16 |
| VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) (2) | 2020.04.30 |
설정
트랙백
댓글
글
컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기
스마트폰이 등장하기 전까지만 해도 휴대전화로 인터넷을 한다는 것은 매우 느린 환경의 통신사의 망을 통해 인터넷을 할 수 있지만 잠시만 사용해도 엄청난 요금울 부과했기 때문에 데이터를 사용하는 것 자체가 상당히 부담스러웠던 시절이 있었습니다. 그러나 아이폰의 도래로부터 스마트폰이 보급되면서 통신사는 무제한 요금제를 출시하면서 이제는 데이터를 부담 없이 쓸 수 있게 되었습니다. 또한 지하철 및 공공장소에 설치된 통신사의 와이파이를 통해 인터넷을 맘껏 즐길 수도 있지요.
그러나 태블릿이나 노트북의 경우는 이야기가 다릅니다. 통신사의 와이파이는 해당 통신사의 USIM이 기기에 삽입되어 있어야 인터넷을 사용할 수 있습니다. 물론 몇몇 제품의 경우 USIM을 삽입할 수 있는 공간이 마련되어 있어 무선 환경에서 인터넷을 즐길 수 있지만 이전에 나온 물건들에서 이를 사용하는데 어려움이 있습니다.
그 때 마다 생각해 보았던 것이 있었습니다. 혹시 USB를 통해 USIM을 삽입하여 인터넷을 사용할 수 있지 않을까 하는 생각이었죠. 물론 스마트폰의 테더링 기능을 통해 인터넷을 사용할 수 있지만 해외 및 국내의 몇몇 통신사의 경우 테더링을 사용할 시 추가 요금을 부과하는 정책이 있는 경우도 있습니다.
혹시나 하는 마음에 인터넷을 찾아보니 역시 제 생각처럼 USB 모뎀이 판매되고 있던 것입니다!

중국 선전에 위치한 TIANJIE라는 회사에서 제작한 LTE USB 모뎀을 보니 제가 원하던 그 기능을 지원함을 확인할 수 있었습니다. 화웨이에서도 이와 비슷한 상품을 판매하고 있었지만 화웨이의 안 좋은 소식들을 들어왔던 저에게 비록 중국산이지만 해당 회사의 제품을 구매해 보았습니다.

주문한지 약 2주일만에 배송되었습니다. 가장 느린 배송을 선택해서 늦어도 1달내로 배송된다고 되있었는데 생각보다 빨리 왔더군요.
그리고 사진만으로 봐소 몰랐는데 이 USB 모뎀으 크기가 생각보다 큽니다. 크기를 비교해보기 위해 LG X4와 같이 나란히 두어보았는데 확실히 큽니다.

LTE USB 모뎀의 뒷면입니다. 이 부분을 통해서 USIM을 삽입할 수 있는 것으로 보입니다.

뒷면을 개봉한 모습입니다. USIM 뿐 아니라 SD카드로 사용할 수 있는 것으로 보입니다.

USIM을 삽입해 보았습니다. 가장 큰 USIM을 사용하기 때문에 표준 USIM 어댑터를 사용해서 꽃아줍니다. 이제 제 노트북에 USB 모뎀을 꽃아보았습니다.

꽃자마자 다음과 같은 알림이 나타납니다. 생각보다 인식은 잘 되는듯 합니다.

노트북에 꽃힌 LTE USB모뎀의 모습입니다. 통신사와 연결이 되지 않았을 경우 보시는 바와 같이 빨간색으로 뜹니다.

USB를 열면 다음과 같은 파일들이 들어있습니다. Setup를 실행합니다.

설치 과정은 매우 심플합니다. Install 버튼을 클릭합니다.

Install 버튼을 누르시면 설치가 진행됩니다. 차분하게 기다리시면

다음과 같이 설치가 완료됩니다. Finish 버튼을 눌러 설치를 완료합니다.

설치 종료 후 프로그램을 실행하면 다음과 같은 창이 뜨면서 설정 초기화가 진행됩니다.


프로그램 초기화가 되면 다음과 같은 화면이 나타납니다. 제 유심이 제대로 인식되지 않았는지 바로 연결되지는 않더군요. 톱니바퀴 버튼을 눌러 설정으로 넘어갑니다.

Setting → Network connection → Network search 메뉴로 들어간 다음 'Manual search'를 선택하신 후 약 5분정도 기다리시면 다음과 같은 메뉴가 나타납니다.

제가 사용하는 통신사가 KT 알뜰폰이다 보니 KT만 Available 상태가 되어있습니다. LTE는 4G, UMTS는 3G를 의미합니다.

설정 메뉴에서 자신이 사용하고자 하는 통신 방식(LTE 혹은 3G)을 선택후 이름과 APN 주소를 입력합니다. Profile name은 자신이 식별할 수 있는 이름으로, APN은 자신이 이용하는 통신사에서 제공하는 APN주소를 입력합니다. 자신이 사용하는 통신사의 APN 주소에 대해서는 아래의 블로그를 통해 확인해주시기 바랍니다.
안드로이드 스마트폰 통신사별 APN 설정 방법
https://nemos.tistory.com/763
안드로이드 스마트폰 통신사별 APN 설정 방법 (SKT 3G, SKT LTE, KT 3G, KT LTE, U+ LTE)
안드로이드 스마트폰 통신사별 APN 설정 방법 (SKT 3G, SKT LTE, KT 3G, KT LTE, U+ LTE) 해외에서 구입한 안드로이드 스마트폰의 경우 국내에서 사용하기 위해 유심을 꼽아도 APN 정보가 제대로 입력되지 않
nemos.tistory.com

설정하신 후 첫 페이지로 돌아오시면 앞에서 설정하였던 각 메뉴들이 등장합니다. Connect 버튼을 누르면 연결됩니다.

접속이 되는 순간 문자가 한 통 들어옵니다. 해당 프로그램을 통해 문제 송수신이 가능한 것으로 보입니다.

그래서 한 번 이 매니저 프로그램을 통해 문자 한 통을 전송해 보았습니다.

놀랍게도 메시지가 정상적으로 수신되는 것을 확인할 수 있었습니다. 노트북에서도 인터넷을 확실하게 즐길 수 있는지도 확인해볼까요?

연결 상태를 확인하니 다음과 같이 전화기 모양의 이모티콘이 나타는 것을 확인할 수 있었습니다. 운영체제 자체적으로 무선통신 환경을 제공해주는 것으로 보입니다.

3G가 연결되어 있을 때 초록색으로 점등되고

LTE가 연결될 때는 파란색으로 불이 점등됩니다.
※후기
본연의 기능이 충실해서 자신의 노트북에 유심을 꽃아 인터넷을 사용하고자 하시는 분들께 추천드립니다. 다만 좀 더 좋은 성능의 강력한 기능을 원하신다면 돈 더 주고 화웨이와 같은 제품을 구매하시길 추천드립니다.
혹시 리눅스(우분투) 혹은 USIM칩을 사용할 수 없는 Wifi 기반 안드로이드 기기에서 USB 모뎀을 사용해보고자 하시는 분들께서는 아래의 글을 참조해주시길 바랍니다.
Linux에 USIM을 꽂아 통신사 데이터를 써보자! 우분투에서 LTE USB 모뎀 사용방법
작년 모종의 사유로 인해 인터넷이 설치되지 않은 환경에서 인터넷을 사용해야 했었는데 사용하고 있는 요금제에서 테더링을 허용하지 않아서 처음부터 컴퓨터에서 USIM을 꽃아 컴퓨터에서 데
elecs.tistory.com
안드로이드 기기에 LTE USB 모뎀을 연결해서 무선 데이터를 사용하는 방법 [PPP widget 3]
우연한 기회로 작년에 컴퓨터로 LTE 데이터를 사용할 수 있는 방법에 대해 포스팅을 하였던 적이 있었는데 지금까지도 이 글을 보러 와주시는 분들이 많았습니다. 저와 같은 고민을 하시던 분
elecs.tistory.com
'공대생의 팁' 카테고리의 다른 글
| 모션 증폭(Motion Magnification) (0) | 2020.08.15 |
|---|---|
| VMware 가상머신에서 실제 프린터를 연결하는 방법 (0) | 2020.07.05 |
| Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 (4) | 2020.05.16 |
| VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) (2) | 2020.04.30 |
| Winsorization(윈저화) (0) | 2020.03.01 |
설정
트랙백
댓글
글
Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법
인터넷을 통해 원격으로 소스코드를 수정하기 위해 Visual Studio Code에 Remote Development 확정설치를 하여 SSH 접속으로 서버 컴퓨터의 소스코드를 작성할 수 있습니다.
혹시 Visual Studio Code에 SSH 확장 설치에 대해 자세히 알고 싶으신 분들께서는 아래의 포스팅을 통해 기본적인 환경을 구축해줍니다.
VS Code Remote 사용하기 - SSH 방식
https://noooop.tistory.com/entry/VS-Code-Remote-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0-SSH-%EB%B0%A9%EC%8B%9D
이렇게 VS Code에 SSH 방식의 원격 개발환경을 마련하는 과정에서 다음과 같은 문제점이 발생하였습니다.

분명 비밀번호를 입력하였음에도 다음의 화면과 같이 또다시 비밀번호를 요구하는 화면이 나타납니다. 물론 이 상황에서 다시 비밀번호를 입력해도 이러한 현상이 계속 반복되고 있었습니다.
이 현상은 VS Code를 최신 버전으로 업그레이드 후 원격으로 SSH접속을 하는 과정에서 주로 발생하는 것을 확인할 수 있었습니다. 이 경우 서버에 있는 VS Code와 관련된 설정을 모두 지운 다음 다시 설치해야 접속이 원활해집니다.
이를 해결하기 위해서는 서버측의 VS Code 설정 관련 자료가 저장되어 있는 .vscode-server 폴더를 삭제하여야 합니다. 다음과 같은 명령어로 서버에 접속하여 .vscode-server 폴더를 제거합니다.
$ cd ~
$ rm -rf .vscode-server
위와 같이 서버측의 해당 폴더를 삭제한 후 VS Code를 실행한 후 다시 서버에 접속해보시면 10분 이내의 설치 시간이 지난 후 기존처럼 접속하자마자 바로 사용할 수 있게 됩니다.
'공대생의 팁' 카테고리의 다른 글
| VMware 가상머신에서 실제 프린터를 연결하는 방법 (0) | 2020.07.05 |
|---|---|
| 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 (35) | 2020.06.03 |
| VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) (2) | 2020.04.30 |
| Winsorization(윈저화) (0) | 2020.03.01 |
| ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법 (0) | 2020.02.10 |
설정
트랙백
댓글
글
VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04)
2020년 4월이 되면서 우분투 LTS(장기지원)버전인 20.04 이 등장하였습니다. 데스크탑 버전의 디자인은 더욱 세련되어졌고, 설치 ISO도 어느덧 2.5GB에 육박하였습니다. 예전에 CD-ROM을 기준으로 700MB가 넘지 않으려 했다가 끝내 CD에도 담을 수 없는 크기가 되었을 때 설치에 애를 먹었던 때가 있었지만 오늘날처럼 초고속 인터넷이 발전된 시대에 광학매체인 CD도 거의 사용되지 않는 시대가 되었지요.

새로 나온 버전을 사용해보기 위해 가상머신을 사용하곤 하는데 VMware를 사용할 때 마다 한영키가 먹히지 않던 것이 상당히 불편했습니다. 물론 Shift+Space를 통해 변환이 가능하지만 Windows 환경에서 한영키를 적극적으로 사용해왔던 저에겐 여전히 한영키가 중요했습니다.
PC에 직접 설치했을 때엔 잘만 동작하던 한영키가 유독 VMware에 설치된 Windows에서는 한영키가 여전히 동작하는데 왜 Ubuntu에서는 유독 한영키가 먹히지 않는 것인가 찾아보니 VMware에 설치된 Ubuntu에서 한영키에 대한 keycode가 설정이 제대로 되고 있지 않아 발생하는 현상으로 보입니다.
VMware에서 실행중인 Ubuntu에서 한영키 및 한자키를 사용할 수 있는 방법에 대해 단계별로 설명드리도록 하겠습니다.
1. Ubuntu 설치시 한국어로 설정
우분투 최신판인 20.04의 경우 초창기판에서 처음부터 영어로 설치할 때 한국어를 설치하는게 번거로운 점이 있었습니다. 처음부터 한국어를 사용하고자 하시는 분은 설치 첫 단계에서 한국어를 선택해주세요.

2. 키보드 레이아웃 선택시 'Korean-Korean(101/104 key compatible)' 선택

키보드 레이아웃 선택 단계에서 'Korean-Korean(101/104 key compatible)을 선택해주세요. 이 단계에서 한글 키보드를 사용하실 수 있습니다.
3. 우측 상단의 키보드 선택에서 '한국어(Hangul)' 선택

한국어(Hangul)모드에서 Shift+Space로 한영변환이 가능합니다.
4. 한영키 keycode 변환 스크립트 작성
다음과 같은 파일을 생성해줍니다. 제목은 여러분들이 원하시는 대로 작성하셔도 됩니다.
$ vi hangul.sh
1 2 3 | #!/bin/bash setkeycodes 72 122 setkeycodes 71 123 | cs |
5. 스크립트 실행
위에서 작성한 스크립트를 실행하여 한영키가 정상적으로 동작하는지 확인합니다.
$ chmod +x hangul.sh
$ sudo ./hangul.sh
이제 여러분들의 VMware에 설치된 Ubuntu에서 한영키를 사용하실 수 있습니다. 잘 작동되는지 확인해봅니다.
$ xev

6. Systemctl을 통해 Ubuntu 부팅시에도 변경한 설정이 적용될 수 있도록 설정
위에서 설정된 환경이 우분투를 항상 킬 때마다 자동으로 적용될 수 있도록 System의 서비스에 적용될 수 있도록 하겠습니다. 다음과 같이 서비스를 새로 등록해줍니다.
$ cd /etc/systemd/system/
$ sudo vi hangul.service
1 2 3 4 5 6 7 8 | [Unit] Description=Change Hangul keycode [Service] ExecStart=/스크립트가 설정된 경로/hangul.sh [Install] WantedBy=multi-user.target | cs |
이제 위에서 설정한 시스템 서비스를 등록합니다.
$ sudo systemctl enable hangul
$ sudo systemctl start hangul

이제 등록한 서비스가 정상적으로 동작하는지 확인합니다.
$ sudo systemctl status hangul

여기까지 진행하셨다면 이제부터 Ubuntu를 실행하셨을 때 바로 한영키를 사용하실 수 있습니다!
'공대생의 팁' 카테고리의 다른 글
| 컴퓨터에 USIM을 꽂아 통신사 데이터를 써보자! 3G LTE USB 모뎀 사용 후기 (35) | 2020.06.03 |
|---|---|
| Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 (4) | 2020.05.16 |
| Winsorization(윈저화) (0) | 2020.03.01 |
| ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법 (0) | 2020.02.10 |
| Generalized Estimating Equations(일반화 추정 방정식) (0) | 2020.01.03 |
설정
트랙백
댓글
글
Winsorization(윈저화)
데이터를 활용하는 과정에서 다음과 같은 문제를 겪는 경우가 있습니다.
- 상위 극한값(95%) 백분위를 효율적인 방법으로 나타내고자 한다. 약 600개의 변수를 가진 데이터셋을 가지고 있으며, 95% 백분위를 가진 600개의 모든 변수의 극한값을 없애고자 한다.
- 95%와 5%로 "Winsorize"하기 위해 몇 가지 변수가 있다. 95% 백분위보다 큰 값을 가진 모든 관측지가 95% 백분위값을 가져가고, 5% 백분위보다 작은 값을 가진 모든 관측치가 5% 백분위값을 갖기를 원한다.
프로그래머가 수백개의 변수의 극한값을 수정하고자 하는 것은 상당히 어려운 일입니다. 이러한 문제들 중 어느것도 Winsorization의 일반적인 정의를 충족시키지 못합니다. 데이터의 Winsorization은 과연 어떤 점을 말하는 것일까요?
지정된 수의 극한값을 더 작은 데이터값으로 대체하는 과정을 윈저화(Winsorization) 또는 데이터 윈저라이징(Winsorizing)이라 합니다.
윈저화는 극한값에 민감한 표본 평균을 "강화"하는 방법입니다. 원저화된 평균을 얻기 위해 데이터를 정렬하고 (k+1)번째로 가장 작은 값을 k번째로 가장 작은값으로 바꿉니다. 마찬가지로 (k+1)번째로 가장 큰 값을 k번째로 가장 큰 값으로 대체합니다. 이렇게 새로운 데이터셋의 평균을 윈저화된 평균(Winsorized mean)이라고 합니다. 데이터가 대칭 모집단에서 나온 경우 윈저화된 평균은 모집단 평균에 대한 편견이 없는 추청치라 할 수 있습니다.

위 그림에서 위쪽 그래프가 원본 데이터, 아랫쪽이 윈저화된 데이터를 나타냅니다. 원본 데이터의 경우 x값이 -4에서 4 사이의 범위에 분포하여 있음을 보실 수 있습니다. 이 때 x=4일 때의 값은 연속되어 있지 않고 따로 떨어져 있어 outlier처럼 보일 수도 있습니다. 이러한 원본 데이터를 윈저화(Winsorization)하여 최저값을 -2로, 최대값을 2로 설정하고 극한값을 벗어나는 값들은 모두 극한값에 추가함으로서 윈저화된 데이터셋을 만듭니다.
다음으로 윈저화의 특징에 대해 살펴보도록 하겠습니다
윈저화는 대칭입니다. 어떤 사람들은 큰 데이터값만 수정하고자 합니다. 그러나 윈저화는 k번째로 가장 작은 값과 k번째로 가장 큰 값으로 이 극한값을 벗어나는 값들을 해단 k번째 값으로 대체하는 대칭 프로세스입니다.
윈저화는 횟수를 기반으로 합니다. 상위 5%, 95%등 정량형에 근거한 값을 수정하고자 하는 경우가 있습니다. 그러나 정량형을 사용한다고 해서 대칭적인 과정이 되는 것은 아닙니다. \(k_1\)을 하위 5%보다 작은 값의 개수로 하고 \(k_2\)를 상위 5%보다 큰 값의 개수라고 합시다. 데이터에 반복되는 값이 보함되어 있는 경우 \(k_1\)은 \(k_2\)와 같지 않을 수 있으며, 이는 잠재적으로 한 쪽이 다른 쪽보다 더 많은 값으로 바뀜을 의미합니다.
윈저화의 장점
평균과 표준 편차와 같은 기존의 통계는 극단적인 값에 민감합니다. 윈저화의 목적은 극한값의 영향을 줄임으로서 기존의 통계로도 충분히 해석할 수 있게 해주는 것입니다.
윈저화는 각 변수와 모든 변수를 확인하는 것이 불가능할 때 수천개의 변수들을 자동으로 처리하는데 사용되기도 합니다.
윈저화된 통계을 기존 통계와 비교하면 오염된 데이터를 포함하거나 꼬리가 길어 모델에서 특별한 처리가 필요할 수 있는 변수를 확인할 수 있습니다.
참고자료:https://blogs.sas.com/content/iml/2017/02/08/winsorization-good-bad-and-ugly.html
'공대생의 팁' 카테고리의 다른 글
| Visual Studo Code로 SSH 접속시 비밀번호 입력이 반복적으로 나올때 해결방법 (4) | 2020.05.16 |
|---|---|
| VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) (2) | 2020.04.30 |
| ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법 (0) | 2020.02.10 |
| Generalized Estimating Equations(일반화 추정 방정식) (0) | 2020.01.03 |
| Surrogate model(대체 모델) (0) | 2019.11.06 |
설정
트랙백
댓글
글
ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법
기존에 Xtion 카메라를 사용하여 Visual-SLAM을 사용하던 제게 기회가 생겨 Xtion2 카메라를 사용해보게 되었습니다. 바로 USB를 연결하여 사용해보려 하였는데 추가적인 드라이버가 필요한 듯 보입니다.

먼저 아래의 사이트에 접속하셔서 Xtion 2의 드라이브를 다운로드 받습니다.
https://www.asus.com/kr/3D-Sensor/Xtion-2/HelpDesk_Download/

사이트에 접속하신 다음 자신의 운영체제에 해당하는 메뉴를 선택하시면 자신의 운영체제에 맞는 드라이버가 나타납니다. 다운로드를 클릭한 다음 압축을 풀어줍니다.

Linux 64비트를 기준으로 다음과 같은 구성의 파일이 들어있습니다. 다음으로 드라이버를 설치해봅니다.
$ sudo ./install.sh
여기까지 진행하셨다면 거의 대부분의 상황에서는 Xtion2 카메라를 바로 사용하실 수 있습니다. 그러나 컴퓨터의 환경에 따라 드라이버가 인식되지 않는 경우가 발생합니다. 이 경우 다음과 같이 드라이버를 수동으로 설치해줍니다.
$ sudo cp ASUS/Xtion2/lib/libSenDuck.so /usr/lib/openNI2/Drivers/
컴퓨터를 재부팅하신 다음 Xtion2 카메라를 다시 연결해보면 카메라가 정상적으로 동작하는 것을 확인하실 수 있습니다.
참고자료: http://blog.naver.com/rlackd93/221234397375
'공대생의 팁' 카테고리의 다른 글
| VMware에 설치된 Ubuntu에서 한영키 사용방법(20.04) (2) | 2020.04.30 |
|---|---|
| Winsorization(윈저화) (0) | 2020.03.01 |
| Generalized Estimating Equations(일반화 추정 방정식) (0) | 2020.01.03 |
| Surrogate model(대체 모델) (0) | 2019.11.06 |
| VirtualBox에 안드로이드 설치 도중 부팅이 멈출 때 해결방법 (2) | 2019.10.21 |
설정
트랙백
댓글
글
Generalized Estimating Equations(일반화 추정 방정식)
피험자 그룹에서 반복 측정(반응[Response] 및 공변량[Covariate])한 결과를 관찰한다고 가정해봅니다. 이러한 공변량을 기반으로 각각에 대한 예상 반응 모델링을 하고자 할 때 아래와 같은 몇 가지 경우가 있습니다.
■ 몇 가지 통제된 식단 중 하나를 각 사람들 개별로 할당하고 시간이 지남에 따라 콜레스테롤 수치를 측정
■ 시간의 경과에 따라 얻은 값과 어떤 변수의 관계 연구
■ 아이를 갖는 것이 여성의 노동력 참여 가능성에 미치는 영향 결정
위와 같이 (반복해서 측정하여 얻은) 패널 데이터가 갖는 장점은 시간적 차이가 없고 관찰할 수 없는 개인 간의 차이를 제어할 수 있다는 점입니다. 개인당 다중 관측치를 갖는 것은 개인 내 변화를 기초로 추정치를 산출할 수 있게 합니다.
이러한 위의 경우들을 분석하는데 가장 쉬운 방법은 공변량이 결과에 적층 효과(Additive effect)를 미치는 데이터에 선형 모델을 적합화하는 것입니다. 변수가 선형 관계가 아닌 다른 것에 영향을 받는 경우(관심의 반응이 확률인 경우) 일반화 선형 모델(Generalized Linear Model)이 더 적합할 것입니다. GLM에는 다음과 같은 식이 있습니다.
$$Y_i = \mu_i + \varepsilon_i, \qquad g(\mu_i) = X_i'\beta$$
여기서 개별 \(i\)의 경우 \(Y_i\)는 반응, \(X_i\)는 공변량, \(\beta\)는 계수의 벡터, \(\varepsilon_i\)는 임의의 오차, g는 가능한 반응 집합에서 공변량의 선형 함수에 사상되는 연결 함수(Link function) 입니다.
매개변수를 추정하고 GLM을 추론하기 위해서는 오류가 독립적이고 동일하게 분포되어 있다고 가정해야 합니다. 패널 데이터의 경우, 각 개인에 대한 관찰은 상관관계가 존재하기 때문에 이는 명백히 사실이 아닙니다.
한 가지 가능한 해결책은 모델 피팅에 피험자별 임의 효과(Random effect)를 포함하는 것입니다. 이 방법은 GLMM(Generalized Linear Mixed Model)이라고 부릅니다. GLMM은 모수적 가정(Parametric assumption)을 필요로 합니다.
일반화 추정 방정식(Generalized Estimation Equation)은 이를 처리하기 위한 비모수적 방법(Nonparametric assumption)입니다. GEE의 아이디어는 모든 피험자에 대해 평균을 내고 대상 내 공분산 구조를 잘 예측하는 것입니다. 데이터가 특정 분포에서 생성되었다고 가정하는 대신 공변량과 반응 사이의 관계를 설명하기 위해 반복적으로 최선의 \(\beta\)를 선택하기 위해 모멘트 가정을 사용합니다.

주의사항: GLMM과 GEE에 대한 결과물 해석은 다르다는 점을 유의 바랍니다.
피험자별 vs 전인원 평균
GEE는 인구 평균 효과(Population average)를 추정합니다. 아래의 두 시나리오를 생각해봅니다.
● 시나리오2: 당신은 보건소 공무원이고 심장마비 위험에 처한 모든 사람들이 그 스테틴 약을 복용한다면 심장마비 사망자수를 줄일 수 있는지 알고싶다.
첫 번째 시나리오에서는 각 개별 확률을 알자 합니다. 두 번째 시나리오는 전체 인구에 대한 예측에 관심을 두고 있습니다. GEE는 두 번째 시나리오에서 추정할 수 있지만 첫 번째 시나리오에서는 알 수 없습니다.
GEE의 기초
GEE는 인구 평균 모델 매개변수와 이들의 표준 오류를 추정합니다. GEE에 대한 가정은 GLM에 대한 가정과 비슷합니다.
- 1. 응답 \(Y_1, Y_2, ... , Y_n\)은 상관관계가 있거나 무리를 이룬다.
- 2. 연결함수 g에 의해 설명된 공변량과 반응의 변환 사이에는 선형 관계가 있다.
- 3. 피험자 내의 공분산에는 몇 가지 구조("working 공분산")가 있다.
- ● 독립성(시간 경과에 따른 관찰은 독립적)
- ● 교환가능(시간 경과에 따른 모든 관측치에는 동일한 상관 관계가 있음)
- ● 비정형(모든 시점 간의 상관관계는 다를 수 있음)
GEE에 맞추기 위해 이러한 working 공분산 구조 중 하나를 선택해야 합니다. GLM과 마찬가지로 GEE는 반복적으로 최소 가중치를 조정하여 가중치로 작용하는 공분산 행렬을 연결합니다. 가중 최소 제곱 문제는 등식 추정식(Eponymous estimating equation)입니다. 만약 최대 가능성(Maximum likelihood)에 익숙하다면, 이 방정식을 Score function(log-likelihood의 1차 미분값)이라고 생각할 수 있습니다. 이 함수는 \(\beta\)의 최적 선택시 0과 같습니다.
데이터 생성 과정(선형성)에 어떤 구조를 적용하더라도 분포를 완전히 특정하지 않습니다. \(\beta\)추정은 순전히 최적화의 연습입니다.
공분산이 잘못 정의되어 있는 것이 걱정된다면?
β를 추정하기 위해서는 공분산 구조를 선택해야 하지만, 만약 β가 올바르게 나타나지 않는다면 어떻게 해야할까요?
추정 방정식은 실제로 첫 번째 경우를 기준으로 하기 때문에 \(\beta\)는 Working 공분산 구조가 잘못되었다 하더라도 일관되게 추정될 수 있을것입니다. 그러나, 이로부터 계산된 표준 오차는 잘못될 것입니다. 이 문제를 해결하기 위해서는 견고성(Robustness)을 위해Huber-White의 "샌드위치 추정기(Sandwich estimator)"를 사용하여 GEE를 사용합니다. 샌드위치 분산 추정기의 기본 개념은 아이디어는 경험적 공분산을 사용하여 기본 공분산에 근사화하는 것입니다.
그렇다면 왜 Working 공분산을 지정해야할까요?
1. 통계 효율(Statistical efficiency)
2. 샌드위치 견고성(Sandwich robustness)는 표본이 큰 특성값
그렇다면 항상 샌드위치 추정기를 사용해야만 할까요?
아닙니다. 만약 아래와 같은 경우가 생길 경우 그렇지 않습니다.
1. 독립된 피험자의 수가 반복되는 측정치의 수보다 훨씬 적을때
2. 설계의 균형이 맞지 않을때(반복되는 측정치의 수가 개별로 다른 경우)
장점
● 최대우도측정(Maximum Likelihood Estimation)에 비해 계산이 단순합니다.
● 분포에 대한 가정이 없습니다.
● 상관 구조가 잘못 정의되어 있더라도 추정치는 일치합니다.(평균 응답에 대한 모델이 올바르다고 가정하였을 때)
한계
● 우도 기반 방법(Likelihood-based method)은 통상적인 통계적 추론에 사용할 수 없습니다. GEE는 준우도 방법(Quasi-likelihood method)입니다.
● GEE는 단지 추정 절차일 뿐이므로 모델 선택을 수행하는 방법이 명확하지 않습니다. 적합도 측정은 쉽게 구할수가 없습니다.
● 피험체에 특정된 측정을 할 수 없습니다.
GEE의 확장
● GEE2: 2차 연장
○ 여기서 소개한 GEE의 버전은 GEE1입니다.
○ 아이디어: 공분산을 연구하기 위한 더 복잡한 방정식을 사용합니다.
● 대체 로지스틱 회귀(Alternating Logistic Regression) (Carey, Zeger, and Diggle(1993)): 다른 조건으로 결과 모델링
○ 아이디어: 모델 연결에 상관관계 대신 로그 Odd ratio를 사용합니다.
GEE에 대한 심화학습
● 첫 번째 평균 및 공분산(준우도 접근법)
● 샌드위치 추정기(Sandwich estimator)를 사용하여 공분산의 설정 오류(misspecification) 방지
● 인구 평균 효과(Population-averaged effects) 모델링
● 대상 내 의존성이 관찰되지 않거나 알려지지 않은 경우 유용성
● 여전히 대상 독립성을 가정(공변량에 따라 조건화됨)
참고자료: https://rlbarter.github.io/Practical-Statistics/2017/05/10/generalized-estimating-equations-gee/
'공대생의 팁' 카테고리의 다른 글
| Winsorization(윈저화) (0) | 2020.03.01 |
|---|---|
| ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법 (0) | 2020.02.10 |
| Surrogate model(대체 모델) (0) | 2019.11.06 |
| VirtualBox에 안드로이드 설치 도중 부팅이 멈출 때 해결방법 (2) | 2019.10.21 |
| Canon MG2990 시리즈 USB 연결 설치방법 (0) | 2019.10.11 |
설정
트랙백
댓글
글
Surrogate model(대체 모델)
Surrogate model(대체 모델, 근사수학모델)이란 자동차 충돌 실험과 같이 제한된 계산 비용이 많이 드는 시뮬레이션을 기반으로 복잡한 시스템의 수많은 입출력 특성을 실제 모형과 유사하게 만드는 것을 목적으로 하는 소형 확장 분석 모델을 일컫는 말입니다.
Surrogate model은 시뮬레이션 모델의 복잡한 동작을 흉내낼 수 있으며, 이러한 특성은 설계 자동화, 매개변수 분석, 우주 탐사에 관한 설계, 최적화 및 민감도 분석등에 사용될 수 있습니다.
Surrogate model은 또한 meta model(메타 모델), response surface model(RSM, 반응표면분석법), 에뮬레이터, auxiliary model(보조 모델), repro-model(복제 모델)이라고도 부릅니다.

https://www.esteco.com/modefrontier/method-selecting-surrogate-models-crashworthiness-optimization
교통사고와 같이 의도치 않은 상황에서 운전자가 생존할 수 있는 방법을 연구하기 위해서는 차량의 충돌을 분석하여 이를 통해 운전자의 생존률을 높이는 방법을 찾는 것은 매우 중요합니다. 그러나 차량 한 대의 가격은 매우 비싸기 때문에 수많은 차량들을 이용하여 충돌 실험을 하게 될 경우 엄청난 양의 비용이 필요합니다. 만약 Surrogate model을 설계하여 이를 활용한다면 해당 모델로 만들어진 차량을 시뮬레이션으로 반복적으로 사용할 수 있게 되고 실제 차량을 사용하여 발생하는 비용을 최소화 할 수 있습니다. 또한, surrogate model을 사용함으로서 얻게 되는 최적화된 솔루션을 개발하여 실제 차량에 적용한다면 더 좋은 결과를 얻을 수 있을 것입니다.

https://www.oreilly.com/radar/ideas-on-interpreting-machine-learning/
인공지능을 해석함에 있어 surrogate model은 매우 중요한 모델입니다. 2019년 현재 시점에서 인공신경망을 해석하기에는 매우 어렵습니다. 너무나도 많은 매개변수(Parameter)들이 있고 이들의 변화를 사람의 눈으로 파악하기엔 변수가 너무나 많기 때문입니다.
이러한 인공신경망 모델을 해석하기 위해 입력값을 의사결정트리 혹은 선형모델에 대입하여 surrogate model로 만들어 해당 인공신경망 모델의 특성을 최대한 이해하는 용도로 사용할 수 있습니다.
'공대생의 팁' 카테고리의 다른 글
| ROS 환경에서 ASUS Xtion2 설치방법&문제 해결방법 (0) | 2020.02.10 |
|---|---|
| Generalized Estimating Equations(일반화 추정 방정식) (0) | 2020.01.03 |
| VirtualBox에 안드로이드 설치 도중 부팅이 멈출 때 해결방법 (2) | 2019.10.21 |
| Canon MG2990 시리즈 USB 연결 설치방법 (0) | 2019.10.11 |
| Windows 10 Internet Explorer 11 에서 Adobe flash가 실행되지 않을때 해결방법 (1) | 2019.08.26 |
