검색결과 리스트
프로그래밍 팁에 해당되는 글 26건
-
2025.02.20
Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법

- 2025.01.02 VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법
- 2024.12.28 Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법
- 2024.08.31 MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 2
- 2024.02.25 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg
- 2023.10.31 Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++)
- 2023.04.08 인공지능 모델 최적화 배포 라이브러리 - MMDeploy
- 2023.03.27 MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기)
- 2022.10.09 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 1
- 2022.08.04 VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기
- 2022.07.27 Anaconda 사설 로컬 저장소 채널 만들기 9
- 2016.11.09 IP 주소를 통해 위치 정보 얻기(IP-API.com)
글
Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법
Torchscript에 대해 검색을 하는 과정에서 제 글을 찾기까지 여러분께서는 Torchscript에 대해 많은 내용들을 배우셨으리라 생각합니다.
그럼에도 수많은 Torchscript에 다룬 글들을 끊임없이 찾다 제 블로그를 발견하신 여러분들이라면 아마도 이러한 고민을 하셨을 것으로 어림 짐작해봅니다.
"간단한 예제들을 보면서 Torchscript에 대해 이해할 수 있었습니다. 하지만 내가 학습한 AI 모델을 Torchscript로 변환하려면 어떻게 해야하죠?
저 또한 지금까지 Torchscript 이론 및 예제들을 익혀보았지만, 실무에 바로 적용하기엔 뭔가 부족한 느낌을 많이 받았습니다. 카메라 영상 데이터를 사용하여 AI모델을 만들고 있는 저에게 있어 영상 데이터를 입력값으로 하는 Torchscript 예제를 찾기가 상당히 어려웠습니다. 다행히도 수없이 많은 구글링과 ChatGPT의 도움 덕에 Torchscript모델을 현업에 적용하는데 간신히 성공하였습니다.
이 포스팅에서는 컬러 이미지를 입력으로 받는 AI모델을 Torchscript로 변환한 후 활용하는 과정들을 기록하였습니다. 혹시나 Torchscript에 대해 이론적인 지식을 필요로 하시는 분들께서는 아래의 자료를 참조해주셨으면 합니다.
https://velog.io/@dev_junseok_22/TorchScript-%EC%86%8C%EA%B0%9C
TorchScript 소개
TorchSciprt는 PyTorch 모델을 프로덕션 환경에서 쉽게 사용할 수 있도록 설계된 언어 및 컴파일러입니다. PyTorch는 주로 연구 및 개발에 사용되는 파이썬 기반의 딥러닝 프레임워크이지만, 프로덕션
velog.io
아래 코드를 통해 Vision AI모델을 TorchScript로 변환하고 실행하는 예제를 확인하실 수 있습니다.
먼저, Pytorch로 학습한 AI모델을 TorchScript로 변환합니다 여기서는 TorchVision에서 제공되는 Pretrained Model을 변환해보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import torch
import torchvision
# TorchVision에서 제공하는 모델을 로드
model = torchvision.models.resnet18(pretrained=True)
# 모델을 평가 모드로 전환
model.eval()
# Trace 방식으로 TorchScript 변환
example_input - torch.randn(1, 3, 512, 512)
traced_model = torch.jit.trace(model, example_input)
# TorchScript 모델 저장
traced_model.save('end2end.pt')
|
cs |
다음은 TorchScript로 변환된 AI모델을 Inference 하는 방법입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import cv2
import numpy as np
import torch
import os
import glob
from torchvision import transforms
# AI모델을 학습하였을 때 사용한 이미지 Dataset의 정보
mean=[95.5142,114.2475,112.4564]
std=[40.0954,43.8636,38.223]
input_size=(512,512)
# 입력 데이터로 사용할 이미지 불러오기
image_path = "input_image.jpg"
img = cv2.imread(image_path)
height, width, c = img.shape
# AI모델의 Input 양식으로 변환
inputs = cv2.resize(img, input_size)
inputs = (inputs - mean) / std
# 이미지 데이터를 PyTorch 텐서로 변환
toTensor = transforms.ToTensor()
input_tensor = toTensor(inputs.astype(np.float32))
# 입력 이미지의 Tensor 차원을 추가함
# RGB 이미지 기준으로 Tensor가 (3,512,512)에서 (1,3,512,512)로 차원이 증가함
# Batch Size가 1인 입력으로 만들어 AI모델에 입력하는 것임
# to('cuda')로 Tensor값을 GPU메모리에 올림
input_batch = input_tensor.unsqueeze(0).to('cuda:1')
# 저장된 TorchScript 모델 로드
script_model = torch.jit.load('end2end.pt')
# 모델을 GPU로 이동
script_model.to('cuda:1')
# 모델을 추론 모드로 설정
script_model.eval()
# 모델 추론
with torch.no_grad():
output = script_model(input_batch)
# 추론 결과를 GPU에서 CPU 메모리로 불러옴
inference_result = output.squeeze().cpu().numpy()
# 추론 결과를 이미지의 원본 크기로 Resize하여 결과 출력
seg = cv2.resize(inference_result, (width, height), interpolation=cv2.INTER_NEAREST)
|
cs |
이번 포스팅을 작성하면서 딥러닝 AI모델을 가공하는 과정들에 대해 다시 한 번 복습할 수 있었습니다.
실무자 입장에서 오픈소스로 공개된 라이브러리들이 이미지 전처리를 포함한 전반적인 학습 과정들을 포함해 잘 갖추어져 있어 가공되지 않은 원본 이미지를 입력으로 하면 곧바로 결과를 확인할 수 있다보니 Vision AI를 연구하는 입장으로서 AI모델의 학습과정에 필요한 기초적인 내용들에 대해 어렴풋이만 알고 있었다가 Torchscript로 변환된 모델을 다루게 되면서 Low 데이터로부터 학습데이터를 가공하는 기술의 중요성을 깨닫게 되었습니다.
최신 AI 기술들의 경향을 따라가는 것은 중요하지만, 가끔은 AI의 기초를 다시 한 번 되짚어보는 것도 좋을것같습니다.
'프로그래밍 팁' 카테고리의 다른 글
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
|---|---|
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
설정
트랙백
댓글
글
VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법
매번 Ubuntu의 새로운 버전이 나올 때마다 평소대로 Virtualbox에 설치하여 체험을 해왔습니다만 이번 버전에서는 미묘한 변화로 인해 기존의 방식대로 설치가 되지 않는 문제가 발생하여 혹시나 저와 같은 문제가 있으신 분들을 위해 제가 설치했던 방법을 여러분들께 전달드리고자 합니다.
1. VirtualBox에 Ubuntu 24.04를 설치한 후 장치→ 게스트 확장 CD 이미지 삽입... 을 클릭하여 게스트 확장 CD를 가상머신에 삽입합니다.
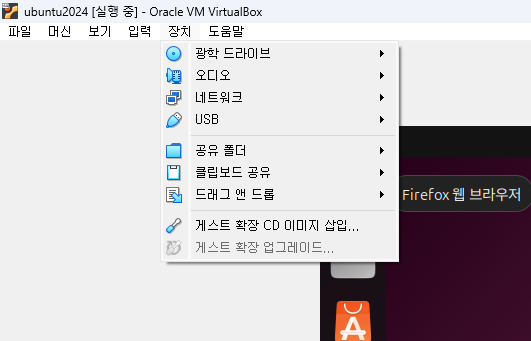
2. 바탕화면에서 CD 아이콘이 생성되는 것을 확인하실 수 있습니다. 해당 아이콘을 클릭합니다.

3. 게스트 확장 설치 폴더가 열립니다. '프로그램 실행' 버튼을 눌러 설치를 진행합니다.

4. 관리자 권한 획득을 위한 비밀번호 입력 후 설치가 진행됩니다. 혹시 아래와 같은 화면이 나올 경우 Terminal에서 다음과 같은 명령어를 입력하여 bzip2를 설치합니다.
$ sudo apt install bzip2
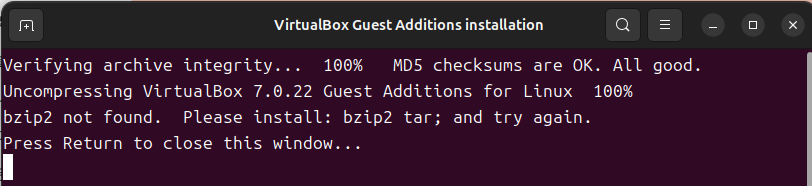
아래와 같은 화면이 나온다면 VirtualBox Guest Addition이 정상적으로 설치되고 있는 것입니다.
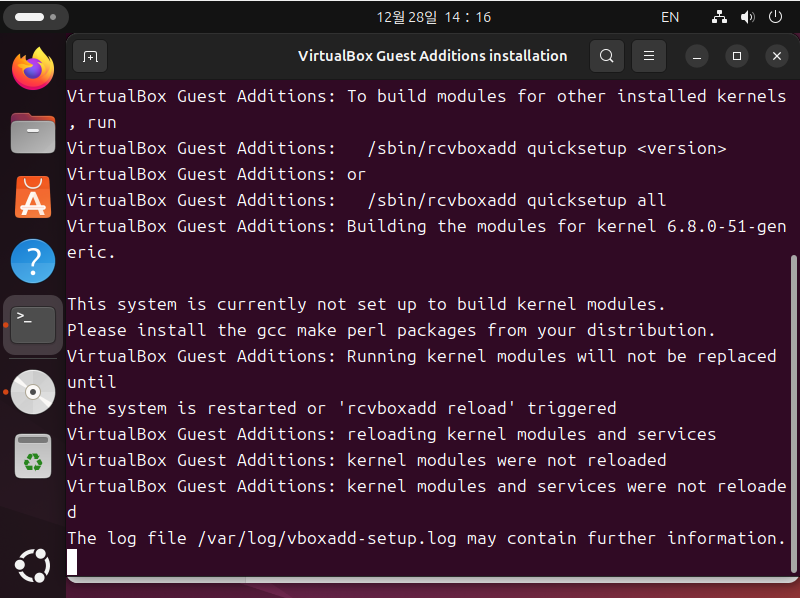
이제 Ubuntu 가상머신을 껏다 키면 아래와 같이 해상도가 VirtualBox의 창 크기에 맞추어 변경되는 것을 확인하실 수 있습니다.

'프로그래밍 팁' 카테고리의 다른 글
| Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법 (0) | 2025.02.20 |
|---|---|
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
설정
트랙백
댓글
글
Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법
지금까지 Ubuntu를 사용할 때 마다 apt를 사용시 다운로드 속도를 빠르게 하기 위해 mirror.kakao.com을 사용하고 있었습니다. 이번에 24.04에서도 미러사이트를 변경하려 하였는데 기존처럼 vi로 /etc/apt/sources.list 파일을 수정하려 했더니 이번 버전부터는 구조가 변경되어 아래 폴더에서 설정하는 것으로 변경되었습니다.
/etc/apt/sources.list.d/ubuntu.sources
위 폴더 내에 있는 파일 내에 설정된 kr.archive.ubuntu.com을 mirror.kakao.com으로 변경해주면 기존처럼 카카오 미러를 통해 apt를 설치할 수 있게 됩니다.
Ubuntu 데스크탑 버전을 사용하는 경우 아래와 같은 방법으로 좀 더 쉽게 apt저장소 사이트를 변경할 수 있습니다.
1. 데스크탑 왼쪽 윗부분을 마우스로 클릭합니다.
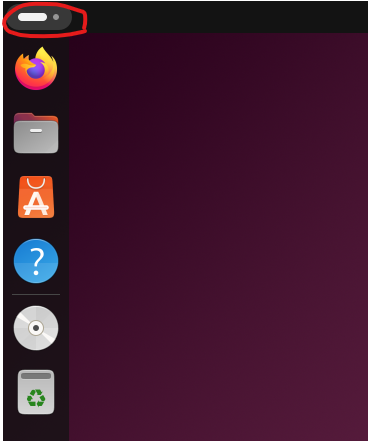
1. 검색창에 영어로 'soft'를 입력해주면 아래와 같은 화면이 나옵니다. '소프트웨어 및 업데이트'를 클릭합니다.
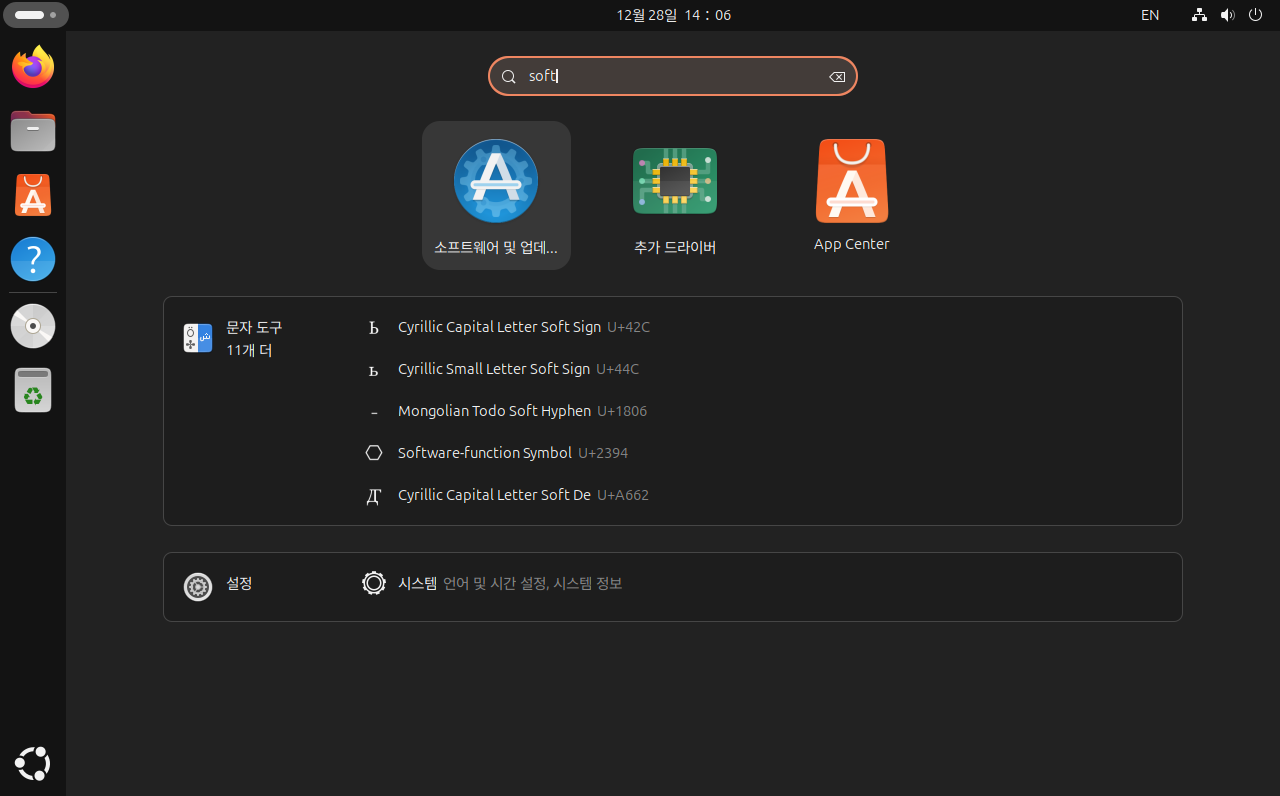
2. 설정 화면에서 '다운로드 위치' 클릭 후 '기타...'를 클릭합니다.
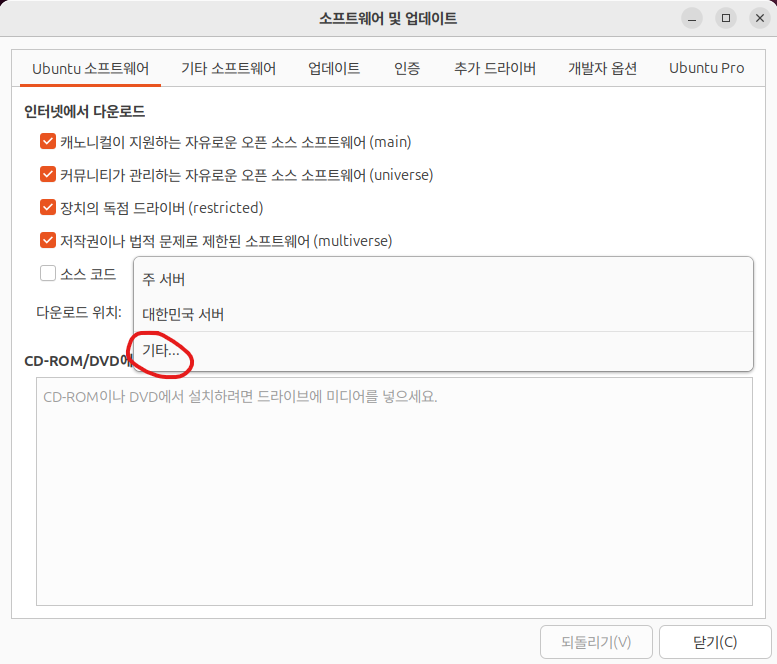
3. 아래와 같은 화면이 나왔다면 '대한민국→mirror.kakao.com'을 선택한 후 '서버 선택'을 클릭합니다.
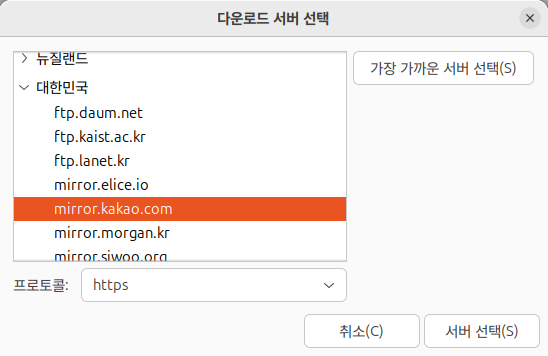
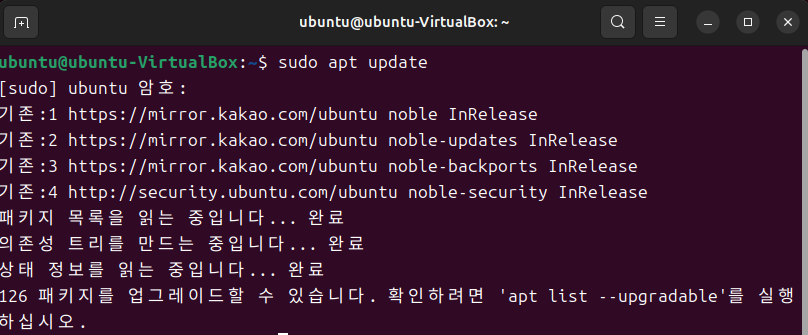
4. Terminal에서 'sudo apt update' 명령어 입력시 apt가 미러사이트에 접속되는 것을 확인할 수 있습니다.
'프로그래밍 팁' 카테고리의 다른 글
| Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법 (0) | 2025.02.20 |
|---|---|
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
설정
트랙백
댓글
글
MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기
Pytorch는 Meta AI(구 페이스북 AI연구소)에서 만든 딥러닝 라이브러리로, 오늘날 AI 관련 논문등에서 많이 사용되고 있으며 Github를 통해 오픈소스로 공개되는 AI모델 다수가 Pytorch를 사용하고 있습니다. 과거 Google의 TensorFlow가 산업용 AI분야에 주로 사용되고 있다고 알려져 있으나 대학원에서 Pytorch를 접했던 연구원들이 산업 현장에서 Pytorch 사용을 이어가게 되면서 산업용 AI분야에서도 Pytorch의 점유율이 높아져가고 있습니다.
TensorFlow에 비해 Pytorch가 갖는 강점으로 모델 설계가 직관적이고 수정이 쉽다는 점입니다. 다만, Pytorch로 자신이 원하는 모델을 만들 수 있다 하더라도 지금까지 공개된 수많은 모델들을 일일히 공부하고 이를 이해하고 설계를 하는 과정은 개발시간이 소요되며, 개발자별 소스코드의 구조에 차이가 있을 경우 모델 설계를 처음부터 하는 것이 나을 정도로 복잡한 과정이 필요할 수 있습니다. 심지어 같은 구조의 AI모델임에도 소스코드 구조가 달라지게 되면 각각의 모델들이 파편화되어 모델 구조 관리에 더 큰 어려움이 생기게 되기 마련입니다.
OpenMMLab에서 공개한 오픈소스 라이브러리인 MMCV는 자주 사용되는 기능들을 단일화하고, 기본에 공개된 AI모델들을 MMCV 라이브러리로 설계하여 모델들의 구조를 단일화하여 개발자 입장에서 간단하게 소스코드 일부 수정만으로 AI모델을 쉽게 변경할 수 있어 개발이 쉽습니다.
이번 포스팅에서는 MMCV라이브러리에 자신이 직접 모델을 만들어 적용하는 방법을 소개시켜드리고자 합니다.
본 포스팅에서는 MMSegmentation을 기준으로 설명드리도록 하겠습니다. MMSegmentation 라이브러리에서 FCN모델은 Backbone으로 ResNet과 HRNet이 기본으로 적용되어 있는데, 저는 여기에 VGG 백본을 추가해보고자 합니다.
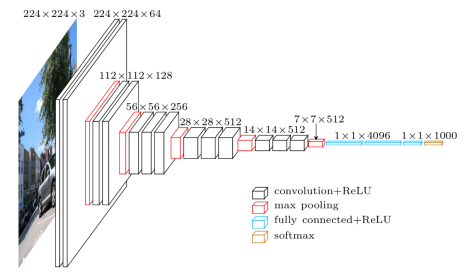
VGG는 2014년 공개된 AI분야 입장에서 보았을 땐 고전 CNN 구조의 모델입니다. 지금 시점에서 보았을 땐 단순한 구조로서 CNN, max pooling, Relu, softmax 등으로 Layer가 구성되어 있어, AI에 입문하시는 분들께서 자신이 직접 AI모델을 만드는 실습자료로 훌륭한 모델 중 하나입니다.
MMCV 라이브러리에서 VGG 모델이 기본으로 제공되고 있어, MMSegmentation에서는 VGG모델을 상속하는 방법으로 Backbone 모델을 추가해보겠습니다. 아래와 같은 경로에 소스코드를 추가해줍니다.
mmseg/models/backbones/FCNVGG.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
import warnings
import torch.nn as nn
from typing import List, Optional, Sequence, Tuple, Union
from mmcv.cnn Import VGG
from mmseg.registry import MODELS
@MODELS.register_module()
class FCNVGG(VGG):
def __init__(self,
depth: int,
with_bn: bool = False,
num_classes: int = -1,
num_stages: int = 5,
dilations: Sequence[int] = (1, 1, 1, 1, 1),
out_indices: Sequence[int] = (0, 1, 2, 3, 4),
frozen_stages: int = -1,
bn_eval: bool = True,
bn_frozen: bool = False,
ceil_mode: bool = False,
with_label_pool: bool = True,
pretrained = None,
init_cfg = None):
super().__init__(
depth,
with_bn,
num_classes,
dilations,
out_indies,
frozem_stages,
bn_eval,
bn_frozen,
ceil_mode,
with_last_pool)
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be specified at the same time'
if init_cfg is not None:
self.init_cfg = init_cfg
elif isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is None:
self.init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(type='Constant', val=1, layer='BatchNorm2d'),
dict(type='Normal', std=0.01, layer='Linear'),
]
else:
raise TypeError('pretrained must e a str or None')
def init_weights(self, pretrained=None):
super().init_weights(pretrained)
def forward(self, x): # should return a tuple
result = super().forward(x)
return result
|
cs |
추가한 Backbone 모델이 mmsegmentation 라이브러리 import시 불러오도록 설정합니다.
mmseg/models/backbones/__init__.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# Copyright (c) OpenMMLab. All rights reserved.
from .beit import BEiT
from .bisenetv1 import BiSeNetV1
from .bisenetv2 import BiSeNetV2
from .cgnet import CGNet
from .ddrnet import DDRNet
from .erfnet import ERFNet
from .fast_scnn import FastSCNN
from .hrnet import HRNet
from .icnet import ICNet
from .mae import MAE
from .mit import MixVisionTransformer
from .mobilenet_v2 import MobileNetV2
from .mobilenet_v3 import MobileNetV3
from .mscan import MSCAN
from .pidnet import PIDNet
from .resnest import ResNeSt
from .resnet import ResNet, ResNetV1c, ResNetV1d
from .resnext import ResNeXt
from .stdc import STDCContextPathNet, STDCNet
from .swin import SwinTransformer
from .timm_backbone import TIMMBackbone
from .twins import PCPVT, SVT
from .unet import UNet
from .vit import VisionTransformer
from .vpd import VPD
__all__ = [
'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT',
'SVT', 'STDCNet', 'STDCContextPathNet', 'BEiT', 'MAE', 'PIDNet', 'MSCAN',
'DDRNet', 'VPD', 'FCNVGG'
]
|
cs |
끝으로, VGG를 Backbone으로 하는 FCN모델을 Config로 구성해줍니다.
fcn_vgg16.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
_base_ = [
'configs/_base_/datasets/cityscapes.py',
'configs/_base_/default_runtime.py',
'configs/_base_/schedules/schedule_40k.py'
]
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
data_preprocessor = dict(
type='SegDataPreProcessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_val=0,
size=(512,512),
seg_pad_val=255)
model = dict(
type='EncoderDecoder',
data_preprocessor=data_preprocessor,
backbone=dict(
type='FCNVGG',
depth=16,
with_last_pool=False,
ceil_mode=True,
init_cfg=dict(
type='Pretrained',
checkpoint='open-mmlab://vgg16_caffe'),
decode_head=dict(
type='FCNHead',
in_channels=512, # VGG모델의 출력 채널수와 일치시킬것
in_index=4, # VGG모델의 출력 Layer중 선택(5개의 Layer중 5번째)
channels=512,
num_convs=2,
concat_input=True,
dropout_ratio=0.1,
num_classes=80,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=512, # VGG모델의 출력 채널수와 일치시킬것
in_index=3, # VGG모델의 출력 Layer중 선택(5개의 Layer중 4번째)
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=80,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg = dict()
test_cfg = dict(mode='whole'))
|
cs |
위와 같이 설정해주신 다음 아래의 명령어를 실행하시면 VGG Backbone이 적용된 AI모델이 학습되는 것을 확인하실 수 있습니다.
$ python tools/train.py fcn_vgg16.py
'프로그래밍 팁' 카테고리의 다른 글
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
|---|---|
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
설정
트랙백
댓글
글
회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg
최신 인공지능 기술이 고도로 발전하여 뚜렷한 성과들이 눈앞에 펼쳐지고 있지만, 현업에서 최신 기술을 적용하는 것은 결코 쉽지 않습니다. 데이터 별로 각각의 특성이 존재하고, 그 데이터에 적합한 인공지능 기술이 반드시 최신 기술이어야만 하는 것은 아닙니다. 즉, SOTA 모델이 특정 데이터에서 가장 좋은 성능을 내지 못할 수도 있다는 것입니다. 다시 말해, 기업에서 수익을 목적으로 데이터에 AI를 적용하기 위해 가장 좋은 AI 모델을 찾는 것이 매우 중요하다는 것입니다.
현업에서 사용하는 데이터를 가공하다 보니, 회전된 이미지가 어느 정도 기울어져 있는지 확인할 수 있는 방법을 찾아야 하는 상황이 생겼습니다. 관련 연구가 있는지 확인해보니 영상에서 기울어진 Object를 Bounding Box를 기울여서 표시하는 연구들이 진행되고 있는 것을 알게 되었습니다.
AI모델을 찾았으니 이 모델에서 학습할 수 있는 데이터를 만들어야겠지요? 이번 포스팅에서는 기울어진 물체를 Labeling할 수 있는 roLabelImg를 사용하는 방법에 대해 다루어보도록 하겠습니다.
https://github.com/cgvict/roLabelImg
GitHub - cgvict/roLabelImg: Label Rotated Rect On Images for training
Label Rotated Rect On Images for training. Contribute to cgvict/roLabelImg development by creating an account on GitHub.
github.com
1. python을 설치합니다. roLabelImg는 python 3.9 이하의 버전에서 구동이 가능합니다.
> conda create -n python3.9 -c conda-forge python=3.9
2. roLabelImg 프로그램 실행시 필수 패키지인 lxml과 pyqt를 설치합니다.
> conda install -c conda-forge lxml pyqt
2. git으로 roLabelImg를 다운로드합니다.
> git clone https://github.com/cgvict/roLabelImg
3. 설치된 pyqt에 포함된 pyrcc로 roLabelImg를 설정합니다. 자신이 설치한 pyqt버전이 5일 경우 pyrcc5를 실행합니다.
> pyrcc5 -o resources.py resources.qrc
4. roLabelImg를 실행합니다.
> python roLabelImg.py
위 과정대로 진행하셨다면 roLabelImg 프로그램이 실행되는 것을 확인하실 수 있습니다. 자신이 Label을 하고자 하는 이미지룰 불러봅니다.

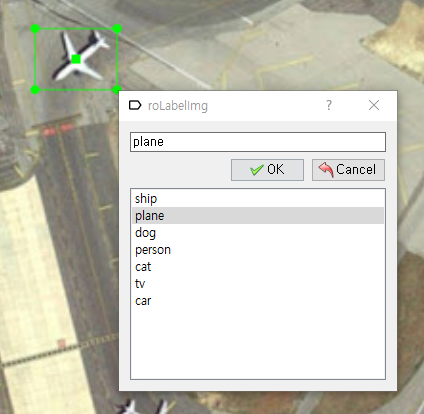
위성으로 찍은 공항 사진에서 비행기가 향하는 방향대로 Label을 진행해보겠습니다. 'Create Rotated RBox'를 클릭하여 아래와 같이 비행기를 전체적으로 Bounding합니다.

마우스를 Drag하여 Bounding Box를 만드는 작업이 완료되면 아래와 같이 방금 만든 Label의 속성을 설정할 수 있습니다.
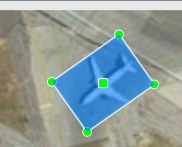
방금 만든 Rotated RBox를 회전시켜 원하는 방향으로 Bounding Box를 돌려보겠습니다. 방금 만든 Bounding Box의 모서리 중 하나에 마우스를 이동시킨 다음 마우스 우측 버튼을 클릭후 드래그를 하면 Bounding Box가 회전하는 것을 확인하실 수 있습니다.

아래 화면과 같이 Bounding Box가 비행기가 향하는 방향으로 회전된 것을 확인하실 수 있습니다.
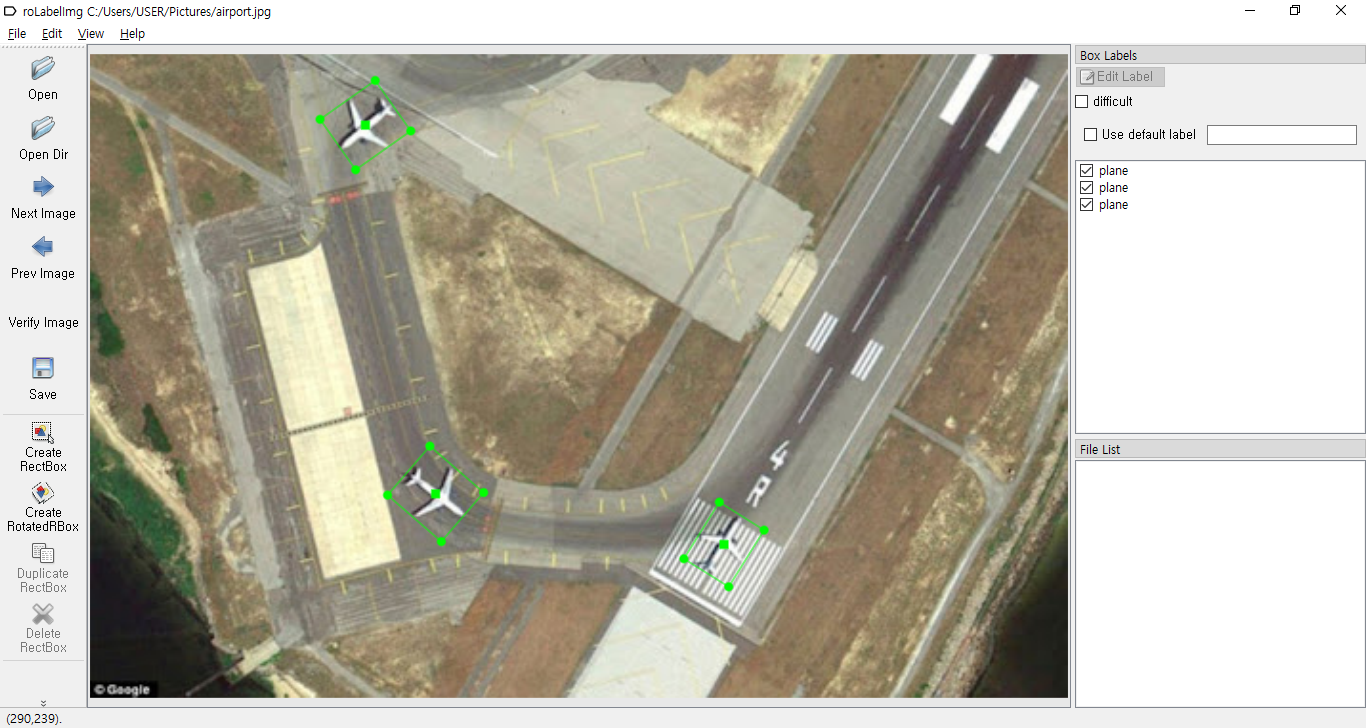
위와 같은 과정대로 이미지에 있는 3개의 비행기에 Rotated RBox를 모두 적용된 것을 확인하실 수 있습니다.
'프로그래밍 팁' 카테고리의 다른 글
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
|---|---|
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
설정
트랙백
댓글
글
Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++)
대다수의 AI 개발은 Linux 환경에서 이루어지다 보니 Linux환경에서 개발된 오픈소스 라이브러리를 Windows에서 사용하기 위해서는 Windows의 환경에 맞추어 설정을 해야하는 번거로움이 발생하곤 합니다. 사내 자체 개발이 목적이라면 Linux를 사용하는 것이 큰 문제가 되지 않을 수 있으나 고객사에서 Windows 환경에서의 사용을 원한다면 사실상 소스코드를 처음부터 설계한다는 각오를 해야 하기 때문에 개발에 많은 시간이 소요되는 안타까운 사례들이 있습니다.
OpenMMLab에서 공개된 오픈소스 라이브러리인 MMCV는 Linux 환경은 물론, Windows에서도 프로그램이 구동될 수 있도록 지원을 해주고 있습니다. 덕분에 Linux 천하의 Vision AI 개발 환경에서 Windows 운영체제 환경에 맞추어 사용할 수 있는 AI 모델을 개발할 수 있어 개발자의 입장에서 보았을 때 막대한 개발 시간이 소요되는 경우를 막을 수 있습니다.
이번 포스팅에서는 MMCV로 개발된 딥러닝 모델을 MMDeploy로 경량화한 다음, 개발한 딥러닝 모델이 Windows 환경에서 보다 빠르게 구동될 수 있도록 만드는 과정에 대해 다루어보도록 하겠습니다.
※MMDeploy는 OpenMMLab에서 공개한 라이브러리(MMDetection, MMSegmentation 등)를 실제 동작환경에서 경량화 및 가속화를 도와주는 라이브러리입니다. MMDeploy에 대해 자세한 내용은 아래의 포스팅을 참조 바랍니다.
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오
elecs.tistory.com
1. 버전 맞추기
2023년 4월 6일 OpenMMLab 2.0 방식의 최신 소스코드 구조가 적용된 MMDeploy 1.0 버전이 공개었습니다. 자신이 개발한 버전에 따라 해당 버전의 MMDeploy를 설정합니다. 본 예제에서는 MMSegmentation 0.30.0, MMDeploy 0.14.0 버전을 기준으로 작성하였습니다.

git clone https://github.com/open-mmlab/mmdeploy.git
git fetch --all --tags
git checkout tags/v0.14.0
2. MMDeploy 설치
Github를 통해 MMDeploy 소스코드 다운로드를 수행한 다음 MMDeploy을 사용하기 위해 필요한 pip 패키지들을 설치합니다.
pip install mmdeploy==0.14.0 mmdeploy-runtime==0.14.0 mmdeploy-runtime-gpu==0.14.0
3. MMPretrain(구 MMClassification) 설치
설치하시는 MMDeploy 버전이 1.x일 경우 MMPretrain을 설치합니다.
pip install mmpratrain
설치하시는 MMDeploy 버전이 0x.일 경우 MMClassification을 설치해주세요
pip install mmcls
4. ONNX 설치
MMDeploy는 MMCV로 개발된 딥러닝 모델을 ONNX로 변환한 다음 TensorRT로 변환하는 방식으로 2단계 변환을 수행합니다. 다음과 같이 ONNX를 설치합니다. 먼저 pip로 ONNX 패키지를 설치한 다음
pip install onnxruntime==1.8.1
다음으로 아래의 Github 사이트를 통해 onnxruntime 소스코드를 다운로드 받습니다.
https://github.com/microsoft/onnxruntime/releases/
Releases · microsoft/onnxruntime
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator - microsoft/onnxruntime
github.com
5. Nvidia 라이브러리 설치(CUDA, cuDNN, TensorRT)
자신의 환경에 맞는 버전의 CUDA, cuDNN, TensorRT를 설치합니다. cuDNN과 TensorRT 설치를 위해 Nvidia 계정이 필요합니다.
CUDA Toolkit >= 11.1
https://developer.nvidia.com/cuda-toolkit-archive/
CUDA Toolkit Archive
Previous releases of the CUDA Toolkit, GPU Computing SDK, documentation and developer drivers can be found using the links below. Please select the release you want from the list below, and be sure to check www.nvidia.com/drivers for more recent production
developer.nvidia.com
cuDNN >= 8.2.1.0
https://developer.nvidia.com/cudnn/
CUDA Deep Neural Network
cuDNN provides researchers and developers with high-performance GPU acceleration.
developer.nvidia.com
TensorRT >= 8.2.3.0
https://developer.nvidia.com/tensorrt-getting-started/
TensorRT - Get Started
Learn more about NVIDIA TensorRT and check out the latest codes and tutorials.
developer.nvidia.com
6. OpenCV 설치
Image Processing 과정에서 주로 사용되는 OpenCV 라이브러리를 설치합니다.
Python만 사용하실 예정이신 분은 pip를 통해 설치합니다.
pip install opencv-python
C++ 환경에서 TensorRT를 사용하고자 하시는 분은 OpenCV 공식 사이트에서 Runtime 라이브러리를 설치해줍니다. Windows 환경에서 설치하기 위해서는 아래의 사이트를 참조하여 설치해주시기 바랍니다.
https://hello-bryan.tistory.com/29
[OpenCV 설치] Windows OpenCv 설치
OpenCV 설치 Windows OpenCV OpenCV 공식 홈페이지로 갑니다. https://opencv.org 상단 메뉴의 RELEASES 를 클릭하고 원하는 버전의 Win Pack 을 클릭하여 다운로드 페이지로 이동합니다. 광고가 겁나많은 다운로드
hello-bryan.tistory.com
7. 환경변수 설정
위의 과정을 통해 설치하였던 onnxruntime, CUDA, cuDNN, TensorRT 라이브러리를 환경변수 Path에 등록합니다. 또한, CUDA_PATH의 환경변수 또한 다음과 같이 등록해주시기 바랍니다.
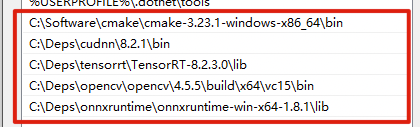
8. Pycuda 설치
Python에서 CUDA 병령 컴퓨팅 API를 수행할 수 있도록 해주는 pycuda를 설치합니다. 만약 설치 과정에서 실패하는 경우 위 6번 과정에서 설치한 라이브러리 환경변수 설정에서 잘못된 경우가 있을 수 있으므로 한 번 더 확인해보시기 바랍니다.
pip install pycuda
9. MMDeploy SDK 설치
Github에 공개된 MMDeploy의 release 라이브러리 탭에서 자신에게 맞는 버전을 선택 후 Assets에서 SDK를 다운로드 받습니다. 여기서는 "mmdeploy-0.14.0-windows-amd64-cuda11.3.zip"을 다운로드 합니다.
https://github.com/open-mmlab/mmdeploy/tags/
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
C++ 환경에서 사용하고자 하시는 경우 SDK를 폴더에 압축해제 하신 다음 Powershell을 실행하여 아래의 경로로 이동해주세요.
mmdeploy-0.14.0-windows-amd64-cuda11.3\example\cpp\build
위 경로로 이동한 다음 C++ SDK를 빌드합니다.
> cmake .. -DMMDeploy_DIR="mmdeploy-0.14.0-windows-amd64-cuda11.3\lib\cmake\mmdeploy" -DTENSORRT_DIR="TensorRT 설치 경로" -DONNXRUNTIME_DIR="onnxruntime 설치 경로" -DOpenCV_DIR="opencv\build\x64\vc15\lib"
> cmake --build . --config Release
10. Model 변환
지금까지 TensorRT를 사용하기 위해 구동 환경에서 MMDeploy를 적용하는 방법에 대해 설명드렸습니다. 이제 본격적으로 자신이 개발한 Model을 배포 환경에서 구동할 수 있도록 변환하는 단계를 진행해보도록 하겠습니다.
Python 소스코드를 아래와 같이 작성한 다음 실행합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from mmdeploy.apis import torch2onnx
from mmdeploy.apis .tensorrt import onnx2tensorrt
from mmdeploy.backend.sdk.expert_info import export2SDK
import os
img = '테스트하고자 하는 이미지 경로'
work_dir = 'TensorRT 변환 모델 저장 폴더 경로'
save_file = 'end2end.onnx'
deploy_cfg = 'mmdeploy/configs/mmseg/segmentation_tensorrt-fp16_static-512x512.py'
model_cfg = 'mmseg/자신이 학습한 모델의 설정.py'
model_checkpoint = '변환하고자 하는 모델.pth'
device = 'cuda'
# 1. convert model to IR(onnx)
torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg, model_checkpoint, device)
# 2. convert IR to tensorrt
onnx_model = os.path.join(work_dir, save_file)
save_file = 'end2end.engine'
model_id = 0
onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, onnx_model, device)
# 3. extract pipeline info for sdk use (dump-info)
export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint, device=device)
|
cs |
위의 소스코드를 실행하시면 work_dir 폴더에 다음과 같은 파일들이 생성된 것을 확인하실 수 있습니다.
deploy.json
detail.json
end2end.engine
end2end.onnx
pipeline.json
11. Inference 코드 구현
이제 여러분들이 개발한 딥러닝 모델이 TensorRT로 변환된 것을 확인하였습니다. TensorRT 최적화 모델을 아래와 같이 실행할 수 있습니다.
- python
> python MMDEPLOY/mmdeploy/tools/deploy.py MMDEPLOY/mmdeploy/configs/mmseg/segmentation_tensorrt-int8_static-512x512.py MMSEGMENTATION/configs/모델 설정 파일.py 학습한 모델.engine "데모 이미지.jpg" --device cuda:0
> python MMDEPLOY/demo/python/image_segmentation.py cuda "work_dir 경로" "데모이미지 경로.jpg"
- C++
> MMDeployDIR/example/cpp/build/release/image_segmentation.exe cuda "work_dir 경로" "데모이미지 경로.jpg"
이제 여러분들도 MMDeploy를 통해 경량화돤 모델이 배포 환경에 맞추어 실행 속도가 굉장히 향상된 것을 확인하실 수 있습니다.
- 참고자료
https://mmdeploy.readthedocs.io/en/v0.14.0/get_started.html#installation
Get Started — mmdeploy 0.14.0 documentation
Get Started MMDeploy provides useful tools for deploying OpenMMLab models to various platforms and devices. With the help of them, you can not only do model deployment using our pre-defined pipelines but also customize your own deployment pipeline. Introdu
mmdeploy.readthedocs.io
https://mmdeploy.readthedocs.io/en/v0.14.0/02-how-to-run/prebuilt_package_windows.html
How to use prebuilt package on Windows10 — mmdeploy 0.14.0 documentation
Docs > How to use prebuilt package on Windows10 以中文阅读 Shortcuts
mmdeploy.readthedocs.io
'프로그래밍 팁' 카테고리의 다른 글
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
|---|---|
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
설정
트랙백
댓글
글
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오래 걸리는 경우가 있습니다. 이는 개발 단계에서 아무리 좋은 GPU를 사용한다 하더라도 해당 GPU에 모델이 최적화 되어있지 않은 경우 GPU의 성능 대비 좋은 성능을 기대하기 어려운 현상이 있습니다.
개발 단계에서 만들어지는 모델은 다양한 환경에서도 실행될 수 있는 소스코드로 배포되어 어떤 환경에서도 구동될 수 있도록 할 수 있습니다. Nvidia에서 공개한 TensorRT와 같은 모델 최적화 라이브러리를 사용하면 특정 환경의 GPU에서 모델의 Inference 속도가 향상되는 것을 확인할 수 있습니다.

그러므로 설계가 완료된 모델을 배포할 때, 모델이 배포되는 환경에서 최적화되어 좋은 성능을 발휘할 수 있도록 관리하는 과정 또한 매우 중요합니다. OpenMMLab에서 공개한 MMDeploy는 지금까지 OpenMMLab에서 공개한 MMDetection, MMSegmentation등과 같은 딥러닝 라이브러리를 특정 환경에서 최적화 설계되어 배포할 수 있도록 해주는 라이브러리입니다.

MMDeploy를 사용하여 MMCV로 설계된 모델들을 범용 딥러닝 모델인 ONNX로 변환하여 다른 딥러닝 라이브러리로 변환하여 사용하거나 TensorRT를 사용해 자신이 사용하고자 하는 GPU에 모델을 최적화하여 사용할 수도 있습니다.
MMDeploy는 아래의 Github 사이트를 통해 소스코드를 다운로드 받으실 수 있습니다.
https://github.com/open-mmlab/mmdeploy
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
Github 공식 사이트를 통해 자신이 구현하고자 하는 환경의 운영체제(Linux, Windows, macOS 등)에서 직접 설치하실 수 있습니다.
다만, 직접 설치하는 과정이 상당히 복잡하기 때문에 만약 Linux 환경에서 사용하고자 하시는 분은 Docker를 사용하여 설치하시는 것을 적극적으로 권장드립니다. Ubuntu에서 Docker를 설치하는 방법은 아래의 사이트를 참조해주시기 바랍니다.
https://dongle94.github.io/docker/docker-ubuntu-install/
[Docker] Ubuntu에 Docker 설치하기
리눅스 OS 중 우분투 OS에서 도커(Docker) 프로그램을 설치하는 방법을 알아본다.
dongle94.github.io
Docker 환경에서 GPU 버전의 MMDeploy 설치를 시도하면 아래와 같은 에러가 발생하는 경우가 있습니다.
docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
이 경우 아래의 블로그에서 소개하는 방법과 같이 nvidia-container-toolkit을 설치해주면 쉽게 해결하실 수 있습니다.
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
https://bluecolorsky.tistory.com/110
[정보] docker: Error response from daemon: could not select device driver with capabilities: [[gpu]] 문제 해결하기
도커를 사용하다 보면 다양한 문제에 맞닥뜨리게 된다. 해결하기 쉬운 문제부터 어려운 문제까지 수많은 문제들이 존재하는데 사용할때마다 항상 다른 오류가 발생하여 문제가 발생할때마다
bluecolorsky.tistory.com
'프로그래밍 팁' 카테고리의 다른 글
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
|---|---|
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
설정
트랙백
댓글
글
MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기)
제가 인공지능에 대해 한창 공부를 할때마다 가장 아쉬웠던 점 중 하나는 자신이 구현하고자 하는 모델에 적합한 데이터를 구하는 것이 어려웠던 것이었습니다. 단지 사람을 감지해내는 기술이 필요한 것이라면 SOTA 알고리즘을 찾은 다음 고성능의 기학습된 모델을 적용하는 것이 가장 좋고 실제로도 제가 다시 재학습 해서 만든 모델보다도 성능이 뛰어나기 때문에 굳이 데이터셋을 직접 만드는 고생을 할 이유가 없기도 합니다.
그러나 내가 구현하고자 하는 물체가 기존의 모델들에 구현되어 있지 않는 경우에는 어쩔수없이 데이터를 수집하여 나만의 데이터셋을 만들어야만합니다. 그러나 기존의 모델들의 성능에 준하는 새로운 모델을 만들기 위해서는 무려 수십만장의 데이터를 수집해야 하는데 이를 개인이 직접 수집하기에는 시간과 비용이 만만치 않습니다.
그렇다면, 내가 원하는 데이터셋을 만들어 이를 테스트해 볼 수 있는 방법은 없는걸까요? 이번 포스팅에서는 Custom Dataset을 본인이 직접 제작하는 방법과 이 데이터셋을 사용하여 MMCV 기반 딥러닝 모델(MMDetection, MMSegmentation)에서 Custom Dataset을 학습해보고자 합니다.

1. 데이터 수집 및 Labeling
원하는 모델 설계에 앞서 자신이 감지하고자 하는 물체가 실제 학습이 가능한지 우선 확인해 볼 필요가 있습니다. 우선 자신이 학습하고자 하는 이미지를 100장 정도 수집한 후 Labeling 작업을 수행합니다. 최근에는 Labeling 작업을 쉽고 효율적으로 수행할 수 있는 Tool들이 많아졌지만 Tutorial 목적으로 작업을 하고자 하시는 분들께서는 추가 비용을 요구하지 않는 오픈소스인 LableMe를 사용해보는 것을 추천 드립니다.
LabelMe를 사용하는 방법에 대해 제가 이전에 정리하였던 자료가 있으니 아래의 포스팅을 참조해주시길 바랍니다.
Lableme로 Coco Dataset과 VOC Dataset 만들기
고성능의 인공지능을 만들기 위한 가장 중요한 작업 중 하나는 최대한 많은 양질의 데이터를 확보하는 것입니다. 상상을 뛰어넘는 인공지능의 놀라운 발전을 보았을 때 마치 AI를 연구하는 사람
elecs.tistory.com
2. 보편적으로 사용되는 Custom Dataset 양식으로 변환
지금까지 공개된 인공지능 모델들의 대부분은 많은 사람들이 자신들이 개발한 소스코드를 쉽게 사용할 수 있도록 설계되어 있습니다. 특히 기존에 공개된 COCO 데이터셋과 PascalVOC는 대중적으로 공개된 퍼블릭 데이터셋으로 누구가 쉽게 접할 수 있어 인공지능에 입문하는 사람들이 처음으로 사용하게 되는 데이터셋이기도 합니다.
위에서 언급한 제 이전의 포스팅 자료에서 소개드렸던 LabelMe로 Labeling 작업을 수행한 다음 COCO 혹은 PascalVOC 데이터셋 양식으로 변경하는 내용에 대해 다루었으니 해당 부분을 참조해주시길 바랍니다.
3. MMCV에서 사용하기
위의 과정을 통해 Custom 데이터셋을 만드셨다면 이를 가지고 OpenMMLab에서 제작한 MMCV에서 바로 사용하실 수 있습니다. LableMe를 통해 제작한 Custom Dataset으로 MMDetection과 MMSegmentation에서의 동작을 확인하였습니다. 각 프로젝트에 바로 사용할 수 있는 데이터셋 양식은 다음과 같습니다. 나머지 데이터셋 양식의 경우 추가적인 설정을 해주시면 사용하실 수 있습니다.
MMDetection: COCO Dataset
LabelMe를 기준으로 Custom Dataset을 Coco 방식으로 변활할 때 Label을 수행한 Json 파일을 Train 용도와 Test 용도로 구분한 다음 각 용도별 Dataset을 Coco로 변환하면 Train 그리고 Test 수행을 위한 Annotation.json 파일을 생성할 수 있습니다.
위의 과정을 통해 생성된 Coco Dataset은 MMDetection에서 제공되는 config 파일에 있는 기본 dataset을 수정하여 자신의 환경에 맞도록 고쳐주시면 바로 사용하실 수 있습니다.
/mmdetection/configs/_base_/datasets/coco*.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/' #Custon Coco Dataset의 폴더 위치
....
#Train, Val, Test 데이터의 Json 및 이미지 파일 경로
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/train.json',
img_prefix=data_root + 'train/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json',
img_prefix=data_root + 'val/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/test.json',
img_prefix=data_root + 'test/',
pipeline=test_pipeline))
....
|
cs |
MMSegmentation: PascalVOC
LableMe에서 labelme2voc로 변환한 데이터들은 MMSegmentation에서 바로 사용하실 수 있습니다. 여기서 만들어진 Segmentation 이미지들 중에서 train.txt, val.txt, test.txt로 사용하고자 하는 파일들의 제목들을 작성해주시고 아래와 같이 Custom Dataset으로 구성하실 수 있습니다.
/mmsegmentation/configs/_base_/datasets/custom_voc12.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
# dataset settings
dataset_type = 'PascalVOCDataset'
data_root = 'data/VOCdevkit/VOC2012' # Custom Voc 데이터셋의 폴더 위치
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='test.txt',
pipeline=test_pipeline))
|
cs |
'프로그래밍 팁' 카테고리의 다른 글
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
|---|---|
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
설정
트랙백
댓글
글
복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기
업무 목적으로 EsperTech사의 Esper를 개발하게 되면서 오랜만에 Java를 사용하게 되었습니다. 학생때 Android 프로그래밍을 하면서 Java를 애용했던 기억이 있고, 그 당시 안드로이드 애플리케이션 개발을 열정적으로 했던 경험이 생생합니다.
어느샌가 안드로이드 앱 개발 환경은 Kotlin으로 재편되면서 자바의 입지는 예전보다 줄어든 경향이 있어보입니다. 그러나 운영체제와 상관 없이 자바 가상머신(JVM)만 설치되어 있으면 그 어떤 기기에서도 Java를 사용할 수 있다는 매력 만큼은 무시할 수 없기에 Java는 2022년 현재에도 애용되는 언어입니다. Espertech의 Esper는 Java로 설계되어 있으며 그 덕에 운영체제를 가리지 않고 손쉽게 사용할 수 있다는 점은 개발자의 관점에서는 편하다고 할 수 있지요.

Espertech사의 esper는 복합 이벤트 처리(Complex Event Processing)를 위한 라이브러리로, 영상, 센서 등에서 복합적으로 발생하는 데이터를 수신하여 이벤트가 발생하였을 때, 각 센서에서 수신되는 데이터 값을 esper가 수신하였을 때 각 센서의 값들을 복합적으로 판단하여 해당 이벤트의 속성을 분석하여 이를 올바르게 판단하는 것을 목표료 합니다.
예를 들어, 공사 현장에 카메라와 마이크가 설치되어 있을 때, 현장에서 작업자가 쓰러지는 모습과 그 과정에서 발생하는 소음들을 카메라와 마이크가 해당 영상 및 소리를 데이터화 하여 esper에 전달하였을 때, esper는 이 이벤트를 위급한 상황이라 판단하고 이를 조치하기 위한 요청을 발생하는 것을 목표로 한다고 생각하시면 되겠습니다.

복합 이벤트 처리 라이브러리인 esper를 Visual Studio code에서 실행해보도록 합니다. 먼저 esper 공식사이트 혹은 공식 github 사이트를 통해 esper 라이브러리를 다운로드 받습니다.
https://www.espertech.com/esper/esper-downloads/
Downloads - EsperTech
Esper is distributed in several packaged formats for your convenience. […]
www.espertech.com
https://github.com/espertechinc/esper
GitHub - espertechinc/esper: Esper Complex Event Processing, Streaming SQL and Event Series Analysis
Esper Complex Event Processing, Streaming SQL and Event Series Analysis - GitHub - espertechinc/esper: Esper Complex Event Processing, Streaming SQL and Event Series Analysis
github.com
다음으로 자신이 esper를 사용하고자 하는 환경에 맞추어 Java, Maven, Visual Studio Code를 설치합니다.
VS Code를 설치한 다음 확장 탭에서 Debugger for Java를 설치해주세요.

이어서 EsperEPL 확장 프로그램을 추가로 설치합니다.

다음으로 설정 탭에서 Maven for Java 탭을 선택한 후 Maven > Executable: Path 메뉴에서 설치된 maven의 bin 경로를 입력해줍니다.
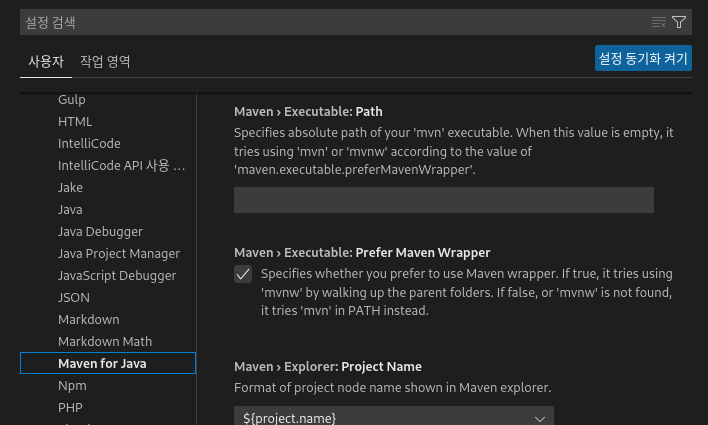
다음으로 esper 소스의 example 폴더를 엽니다.

이제 Example 소스코드들을 컴파일 해봅니다. test모드를 적용하기 위해 탐색기의 maven 탭에서 Lifecycle > test-compile 버튼을 클릭하여 아래와 같이 예제 코드가 컴파일 되는 것을 확인합니다.

이제 컴파일된 esper 예제 코드를 실행해봅니다. Ctrl+F5를 누르면 실행하고자 하는 메인함수를 선택할 수 있으며 선택된 예제 코드가 실행되는 것을 확인하실 수 있습니다.

'프로그래밍 팁' 카테고리의 다른 글
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
|---|---|
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
| IP 주소를 통해 위치 정보 얻기(IP-API.com) (0) | 2016.11.09 |
설정
트랙백
댓글
글
VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기
Visual Studio code를 사용함에 있어 가장 큰 강점은 확장(Extension) 기능을 설치하여 단지 소스코드를 열람하거나 수정하는 것에서 끝나는 것이 아니라 C++, Java, Python 등 자신이 사용하고자 하는 언어를 컴파일 하고 실행까지 직접 해볼 수 있다는 점입니다.
그렇기에 저의 경우 프로그래밍을 하고자 할 때 해당 환경이 VScode에서 지원이 되는지를 먼저 확인하고 결정하는데 중요한 역할을 합니다. 심지어는 SSH를 지원하여 원격 환경에 있는 서버에 접속해 마치 자신의 컴퓨터에서 작업을 하는 것과 같이 편하게 프로그래밍을 진행할 수 있다는 점이 좋습니다.
특히 SSH 환경에서도 확장 기능을 사용할 수 있어 SSH 접속을 통해 원격 서버에 확장을 설치하면 Local에서 사용하는 것과 같이 프로그래밍을 할 수 있는데요. 이번에는 희안하게도 설정이 제대로 되지 않았는지 원격 서버에 확장 설치를 시도하려 하였으나 아래와 같은 에러가 발생하며 더이상 진행이 되지 않는 현상이 발생했습니다.
This extension is disabled in this workspace because it is defined to run in the Remote Extension Host.
이 확장은 원격 확장 호스트에서 실행되도록 정의되었기 때문에 이 작업 영역에서 사용하지 않도록 설정되어 있습니다.

정황상 모종의 사유로 인하여 원격 컴퓨터에 vscode 확장 설치가 진행되지 못한 것으로 추측됩니다. 이 경우 확장 프로그램을 서버에 직접 설치하여 문제를 해결해봅니다.
먼저 자신이 설치하고자 하는 vscode 확장 프로그램을 visual studio makret place에서 검색하신 다음 직접 다운로드 받도록 합니다.
Visual Studio Marketplace
Extensions for Visual Studio family of products on Visual Studio Marketplace
marketplace.visualstudio.com
위 링크의 웹사이트에 접속하신 다음 Visual Studio Code 탭을 선택한 다음 검색창에 자신이 원하는 확장 프로그램의 이름을 입력후 검색합니다.
원하시는 확장 프로그램을 찾으신 다음 해당 페이지 우측에서 'Download Extension'을 클릭하여 확장 프로그램을 다운로드 받습니다.

다운로드를 완료하시면 확장명 .vsix인 설치 파일이 다운로드 된 것을 확인하실 수 있습니다.
다시 vscode를 실행한 다음 소스코드가 저장되어 있는 서버에 ssh 원격 접속하여 다운로드 받은 .vsix 파일을 서버에 전송하신 다음 vscode의 extension 탭에서 아래의 그림과 같이 클릭한 다음 'install from VSIX...' 버튼을 클릭합니다
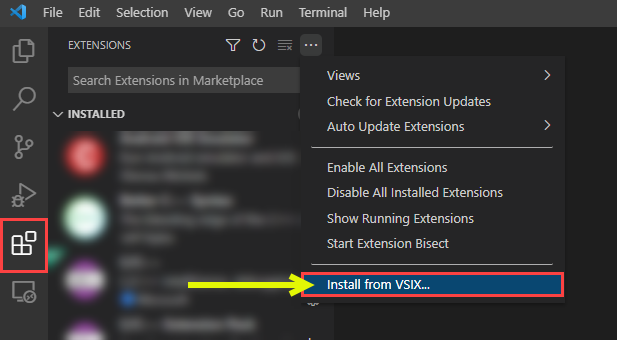
그 다음 .vsix를 저장한 폴더의 위치로 이동한 다음 .vsix를 선택하여 설치를 진행하면 서버에 확장 프로그램이 설치된 것을 확인하실 수 있습니다.
'프로그래밍 팁' 카테고리의 다른 글
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
|---|---|
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
| IP 주소를 통해 위치 정보 얻기(IP-API.com) (0) | 2016.11.09 |
| Fedora에 이전 버전의 OpenJDK 설치하기(Install OpenJDK 7 in Fedora 23) (0) | 2015.12.22 |
설정
트랙백
댓글
글
Anaconda 사설 로컬 저장소 채널 만들기
지금 이순간에도 등장하는 새로운 인공지능 알고리즘을 테스트해보고자 라이브러리를 맞추어서 설치해야 하는데 라이브러리 종속성 충돌로 인해 상당히 골치아픈 일이 많을 것입니다. 이 때 라이브러리를 가상 환경에 만들어 제공하는 Anaconda는 굳이 컴퓨터를 리셋하지 않더라도 간단하게 독립된 가상 환경에서 다른 인공지능 알고리즘의 종속성에 구애받지 않아도 되기 때문에 인공지능 라이브러리 관리 프로그램으로 널리 사용되고 있습니다.
Anaconda는 딥러닝에 필요한 라이브러리를 인터넷을 통해 제공하고 있습니다. 특히 conda-forge 채널은 상당히 많은 라이브러리들을 제공하고 있어 사실상 Anaconda에서 가장 많이 사용되는 저장소이기도 합니다.
그러나 pytorch와 같이 가장 주요한 딥러닝 라이브러리의 경우 용량이 큰데다가 다운로드 받는데에만 상당한 시간이 소요됩니다. 또한 기업 혹은 국가 기관과 같이 보안을 요구하는 곳에서 혹여나 해커에 의해 악성코드가 숨겨진 라이브러리가 유입될 경우 무형 자산의 심각한 손실이 발생하기도 합니다.
이러한 환경에서는 자주 사용되는 라이브러리를 로컬 공간에 저장해두고 사용하는 방법이 요구됩니다. 같은 망 내에 있는 컴퓨터를 통해 자료를 받기 때문에 다운로드 속도 향상은 물론 검증된 자료만 사설망 내에 활용함으로서 외부로부터 악성 공격의 유입을 막을 수 있습니다.
이러한 환경을 만들기 위해 Anaconda의 라이브러리 채널을 저장하여 사설 저장소를 구축하는지에 대해 알아보도록 하겠습니다.
기본 개념

Python - 프로그래밍 언어 中 하나로서 PIP(파이피)를 통해 수많은 라이브러리를 사용할 수 있습니다.

PIP - Python의 라이브러리 설치를 도와주는 패키지 인스톨러로서 명령어만으로 저장소에서 다운로드 하여 설치할 수 있습니다.

ANACONDA - PIP의 최대 단점인 root 호환성 문제 및 서로 다른 버전의 패키지를 요구하는 인공지능 알고리즘들을 별개의 가상환경을 생성하여 관리해주는 사설 패키지 저장소입니다. 단지 원하는 환경을 명령어로 부르는 것 만으로 다른 라이브러리와의 의존성 충돌을 피하는 것 만으로도 개발자들의 생산성 향상에 큰 기여를 하고 있습니다.

CHANNEL - Anaconda의 저장소를 이루는 기본 단위로서, 자신이 원하는 저장소를 선택하여 패키지를 설치할 수 있습니다.

conda-forge - Anaconda의 channel중 하나로서 상당히 많은 패키지들을 제공합니다. 패키지를 설치하고자 할 때는 다음과 같은 명령어를 사용합니다.
$ conda install -c conda-forge 패키지명
위 명령어에서 -c는 원하는 채널을 설정하는 명령어로 conda-forge 채널에 있는 패키지를 받아오겠다는 명령어입니다.
지금까지 Anaconda 및 채널의 개념에 대해 설명드렸습니다. 이제부터 우리가 직접 Anaconda의 채널을 만들고 이를 외부에 공개하는 방법에 대해 살펴보도록 하겠습니다.
1. Channel 저장소를 미러링 하여 가져오기
자신만을 위한 Channel 저장소를 만들기 위해 저장소에 다운받았던 나의 환경에 있는 패키지를 그대로 사용하는 방법이 있습니다만, 다른 환경에서 설치할 때 의존성 문제가 발생할 수 있으므로 인터넷 상에 공개되어 있는 Channel 저장소를 미러링하여 가져오는 방법에 대해 설명 드리겠습니다.
먼저 Channel 저장소의 패키지들을 로컬 저장소로 복사해주는 패키지인 conda-mirror를 설치합니다.
$ pip install conda-mirror
혹은
$ conda install -c conda-forge conda-mirror
혹은
$ git clone https://github.com/conda-incubator/conda-mirror
다음으로 로컬 저장소로 복사하고자 하는 채널을 미러링 합니다. 이를 위해 사용되는 conda-mirror의 사용 옵션에에 대해 간단히 살펴보도록 합시다.
-h, --help
conda-mirror의 옵션들을 확인하실 수 있습니다.
--upstream-channel UPSTREAM_CHANNEL
로컬 저장소에 복사하고자 하는 채널명 혹은 주소를 입력합니다.
--target-directory TARGET_DIRECTORY
upstream channel에서 미러링할 로컬 저장소의 경로를 설정합니다.
--temp-directory TEMP_DIRECTORY
로컬 저장소의 경로에 저장하기 전 임시로 저장하고자 하는 폴더 경로를 입력합니다.
Windows의 경우 사용자 계정의 Temp 내에 임의로 생성됩니다. 이 경우 폴더 관리가 어려울 수 있습니다.
--platform PLATFORM
미러링 하고자 하는 운영체제의 종류를 선택합니다. {'linux-64', 'linux-32','osx-64', 'win-32', 'win-64'}
-D, --include-depends
받고자 하는 패키지의 조건을 설정할 수 있습니다. 일종의 화의트리스트 기능을 합니다.
--config CONFIG
blacklist 및 whitelist를 설정한 yaml 파일을 불러옵니다.
--num-threads NUM_THREADS
다운로드를 위해 사용할 스레드의 갯수를 입력합니다. 0을 입력할 경우 사용가능한 모든 스레드를 설정합니다.
--minimum-free-space MINIMUM_FREE_SPACE
로컬 저장소의 용량이 제한되어있을 경우 해당 용량이 초과하지 않도록 mb 단위로 설정합니다.
-k, --insecure
SSL 에러 이슈로 에러가 발생할 경우 SSL을 무시하고 사용합니다.
만약 conda-forge에서 linux 64비트 라이브러리 전체를 다운로드 받고자 한다면 다음과 같이 입력합니다.
$ conda-mirror --upstream-channel conda-forge --target-directory local_mirror --platform linux-64
conda-forge는 Python의 거의 모든 패키지를 제공한다 해도 무방할 만큼 모두 미러링을 하게 될 경우 상당한 용량을 감당해야 하는 부담감이 있습니다. 우리들이 사용하고자 하는 라이브러리 패키지가 일부이기에 용량만 차지하는 패키지까지 저장해야할 이유가 없지요. 이를 위해 config를 통해 blacklist와 whitelist를 설정하여 원하는 패키지만 설치할 수 있습니다. blacklist란 다운로드를 원치 않는 패키지가 있는 경우 이를 특정고자 할 때 사용하며, whitelist는 특정한 패키지만 다운로드 하고자 할 때 해당 패키지의 상세 내용을 적어 이외의 패키지를 받지 않기 위해 사용합니다. 이를 위해 config에 적용하고자 하는 yaml 파일을 생성합니다.
만약 여러분들이 botocore라는 라이브러리만 얻고자 하고 특정 버전 및 사용하고자 하는 파이썬 버전을 한정하고자 한다면 다음과 같이 내용을 입력합니다.
blacklist:
- name: "*"
whitelist:
- name: botocore
version: 1.4.10
build: py34_0
반면, 특정 패키지중 패키지명에 'agpl'이라는 이름이 들어간 패키지를 제외한 모든 패키지를 설치하고자 한다면 다음과 같은 명령어를 입력합니다.
blacklist:
- license: "*agpl*"
다음으로 예제를 실행해봅시다. 이 예제에서는 특정 버전의 git 패키지만 다운로드할 것입니다.
example.yaml
blacklist:
- name: "*"
whitelist:
- name: git
version: ">=2.32"
다음으로 config를 적용하여 원하는 라이브러리를 conda-forge로부터 가져옵니다.
$ conda-mirror --upstream-channel conda-forge --target-directory 로컬폴더 --temp-directory 임시폴더 --platform win-64 --config .\example.yaml
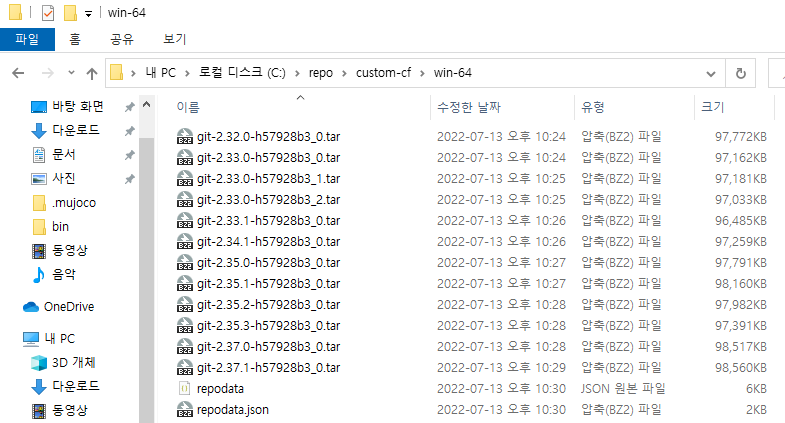
이 명령어를 실행하면 아래의 그림과 같이 2.32버전 이상의 git 라이브러리 패키지가 다운로도 된 것을 확인하실 수 있습니다.
2. 사설 로컬 저장소 채널 지정하기
이번에는 자신이 갖고 있는 패키지 라이브러리를 사설 저장소 채널로 만드는 작업을 진행합니다. 먼저 conda-build 패키지를 설치합니다.
$ conda install conda-build
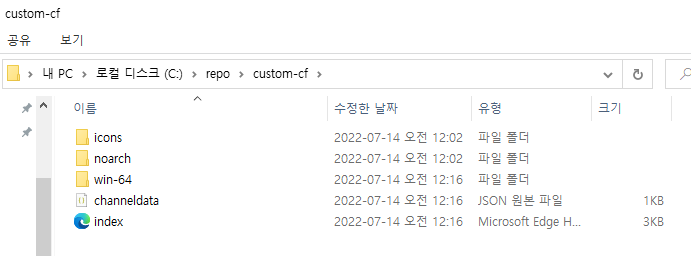
로컬 저장소 채널로 만들고자 하는 폴더가 들어있는 디렉토리에 위치한 다음 다음과 같은 명령어를 입력합니다.
$ conda index 채널명
실행 후 잠시 기다리면 다음과 같이 채널 디랙토리 내에 index 웹페이지 폴더가 생성된 것을 확인하실 수 있습니다.
3. 웹서버 구축 및 등록하기
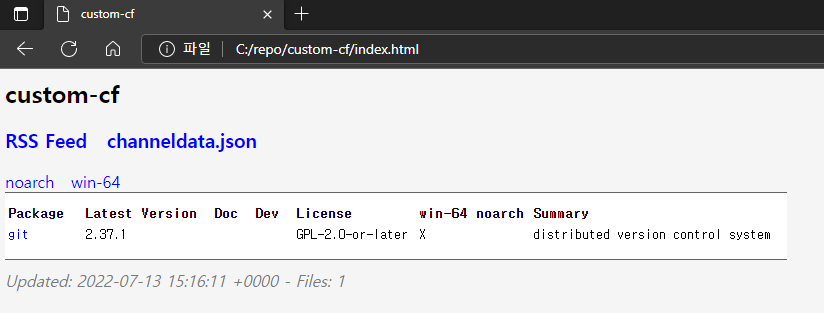
custom 채널 디렉토리에 생성된 index 웹페이지를 열면 다음과 같이 미러링 하였던 저장소 목록이 나타나는 것을 확인하실 수 있습니다.
다음으로 외부에서 미러 서버에 접속할 수 있도록 웹 서버를 설치합니다. 웹서버는 Apache를 보편적으로 사용되고 있습니다.
자신의 운영체제에 맞는 Apache를 설치하여 웹서버를 구축하도록 합니다.
https://mainia.tistory.com/5572
윈도우10 아파치 웹 서버 설치하기
아파치 Apache 는 아파치 재단에서 만든 웹 서버 입니다. 윈도우뿐만 아니라 Unix, Linux 등의 운영체제에서 쉽게 운영할 수 있도록 만든 소프트웨어 입니다. 웹 어플리케이션을 만들기 위한 가장 기
mainia.tistory.com
https://askforyou.tistory.com/120
[linux] 우분투(ubuntu) 아파치(apache) 웹서버 설치 구축(ufw 방화벽 설정)
아파치 웹서버 설치하기 1. 패키지 목록 업데이트 $ sudo apt-get update 2. 아파치 설치 $ sudo apt-get install apache2 3. 설치 진행 화면에서 "y" 입력 후 진행 3. 설치 완료 후 확인 $ sudo service apache2..
askforyou.tistory.com
Apache httpd를 다운로드하신 후 압축을 풀어 원하는 위치에 설치를 진행합니다. 그 다음 httpd.conf 파일을 열어 4군데를 수정하여 자신의 환경에 맞추어 설정합니다.



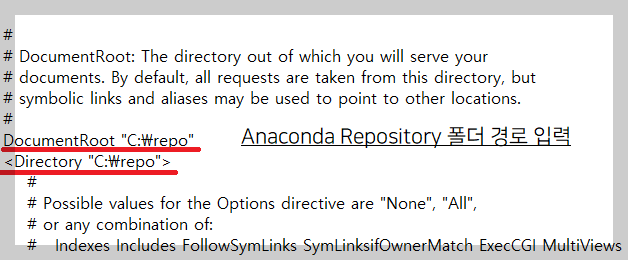
위의 절차대로 수행한 다음 설정한 주소를 입력하면 Anaconda Repository 사이트 웹페이지가 나타나는것을 확인하실 수 있습니다.
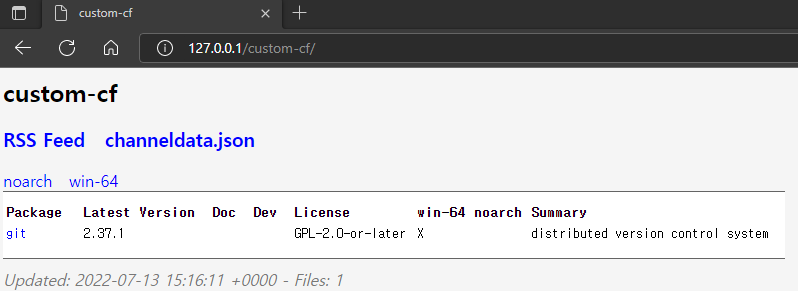
4. 구축된 Anaconda custom 저장소 접속하기
지금까지의 과정을 통해 만든 Anaconda custom 저장소의 Library 패키지를 다운로드해봅니다.
> conda install -c http://127.0.0.1/custom-cf git
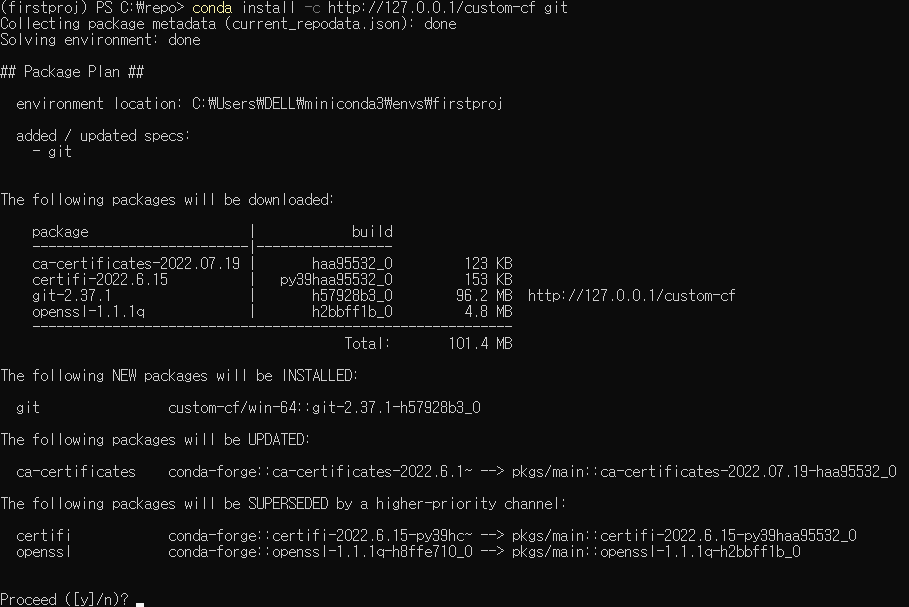
축하합니다! 여러분들만의 Anaconda custom 사설 저장소가 완성되었습니다.
'프로그래밍 팁' 카테고리의 다른 글
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
|---|---|
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| IP 주소를 통해 위치 정보 얻기(IP-API.com) (0) | 2016.11.09 |
| Fedora에 이전 버전의 OpenJDK 설치하기(Install OpenJDK 7 in Fedora 23) (0) | 2015.12.22 |
| OpenCV 최신 버전에서 Python으로 SIFT, SURF 사용하기(Install OpenCV 3.0 in Ubuntu) (2) | 2015.11.18 |
설정
트랙백
댓글
글
IP 주소를 통해 위치 정보 얻기(IP-API.com)
보통 위치 정보를 얻는 방법으로 GPS를 통해 위도 및 경도 값을 구하는 방법과 연결된 Network 정보를 통해 현위치를 짐작해 보는 방법이 있습니다.
GPS를 사용할 때 현위치를 비교적 정확하게 알 수 있으나 실내에 있을 경우 GPS 위성 신호를 수신하는 데에 장애요소가 발생하여 이를 활용하기 어려운 경우가 있습니다. 이 경우 Network 정보를 통해 위치 정보를 얻는 방법이 있습니다. 비록 Network 방식을 통하여 얻게 되는 위치 정보는 GPS에 비하면 신뢰하기 어려우나 GPS를 사용하지 못하는 상황일 경우 위치 정보를 얻는 경우에 쓸 만하다고 볼 수 있겠습니다.
구글 지도를 통해 자신이 알아보고자 하는 위치의 위도 및 경도를 얻는 것은 쉽습니다. 그러나 위치정보 서비스를 제공해야 하는 프로그램의 경우 GPS와 Network를 통해 위치 정보를 얻게 되는데 이를 위해 위치 정보를 얻을 수 있는 방법을 모색해야 할 필요가 있습니다. Network가 연결되어 인터넷을 할 수 있는 환경의 경우 아래 사이트를 접속하면 위치 정보를 얻을 수 있습니다.

위 사이트를 이용할 경우 위와 같이 기기가 Network에 접속하기 위해 사용중인 IP주소를 검색함으로서 위와 같은 정보를 얻을 수 있습니다.
IP-API.com에서는 애플리케이션에서 위 정보를 사용자가 쉽게 이용할 수 있도록 XML과 JSON등을 통해 가공하여 정보를 제공합니다. 프로그램 개발자 자신의 입맛에 맞는 방식을 사용하여 위치 정보를 얻는 것이 다소 쉬워질 것입니다.
XML
JSON
http://ip-api.com/json
CSV
new line
위 주소를 입력하자 마자 사용자의 기기에서 사용중인 IP 주소를 기준으로 위치정보를 제공하게 됩니다. 자신이 다루기 쉬운 방식을 사용하여 원하는 위치 정보를 사용해 보도록 합니다!
'프로그래밍 팁' 카테고리의 다른 글
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
|---|---|
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
| Fedora에 이전 버전의 OpenJDK 설치하기(Install OpenJDK 7 in Fedora 23) (0) | 2015.12.22 |
| OpenCV 최신 버전에서 Python으로 SIFT, SURF 사용하기(Install OpenCV 3.0 in Ubuntu) (2) | 2015.11.18 |
| [JAVA] 같은 공유기에 접속중인 기기의 IP 주소 확인하는방법 (0) | 2015.10.15 |
