검색결과 리스트
글
AI로 Labeling을 자동으로 더 편하게 - AnyLabeling
지난달 메타(페이스북)에서 학습되지 않은 물체(Unlabeled object)도 감지하여 이를 디테일하게 나타내는 Segment Anything 모델(SAM)이 공개된지 불과 1개월이 지난 현재 무려 피인용수가 50을 돌파할 정도로 Semantic Segmentation 분야에서 상당한 주목을 받고 있습니다. 실제 성능을 보았을 때 이미지 내의 Object들을 상당히 디테일하게 찾아주는 점이 상당히 놀라웠습니다. Vision 분야를 연구하는 저에게 있어 SAM 알고리즘은 ChatGPT에 버금갈 정도로 놀라운 성능을 보였습니다.
이러한 SAM 모델을 사용하여 Labeling 작업을 대신 할 수 있으면 편하겠다고 생각을 해보았었는데 이러한 상상을 벌써 하신 분이 계시다니! 어떤 똑똑한 개발자 분께서 SAM 알고리즘을 사용하여 자동으로 Labeling 작업을 수행할 수 있게 해주는 훌륭한 Tool인 AnyLabeling을 무려 오픈소스로 공개하였습니다.

인터페이스는 전반적으로 기존의 Labeling 오픈소스인 Labelimg과 Labelme와 같은 구성으로 기존에 해당 Tool을 사용해보셨던 분들이라면 금새 익숙하게 AnyLabeling을 사용할 수 있도록 설계되었습니다. 즉, 기존의 Labeling 방식대로 Bounding box나 Polygon 방식으로 Labeling을 할 수 있습니다.
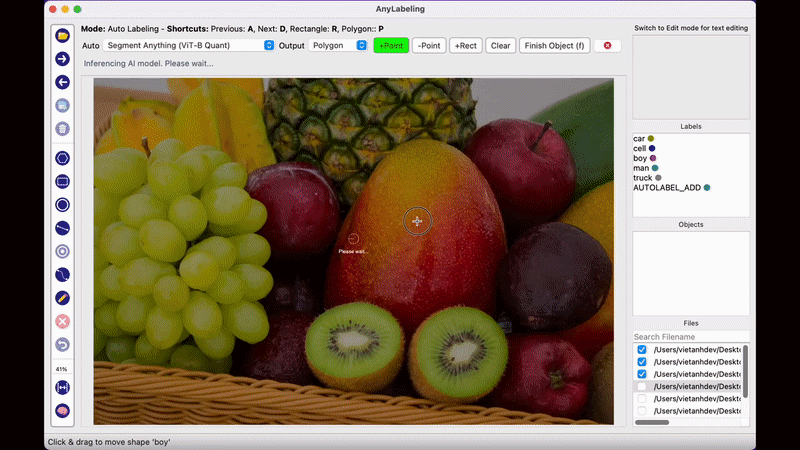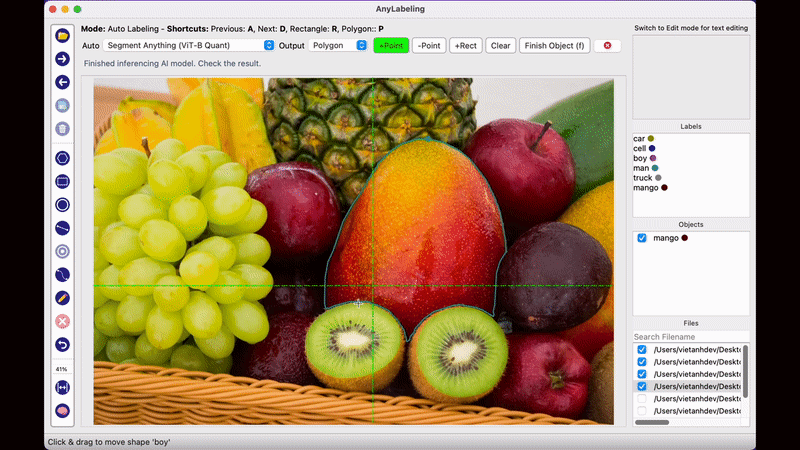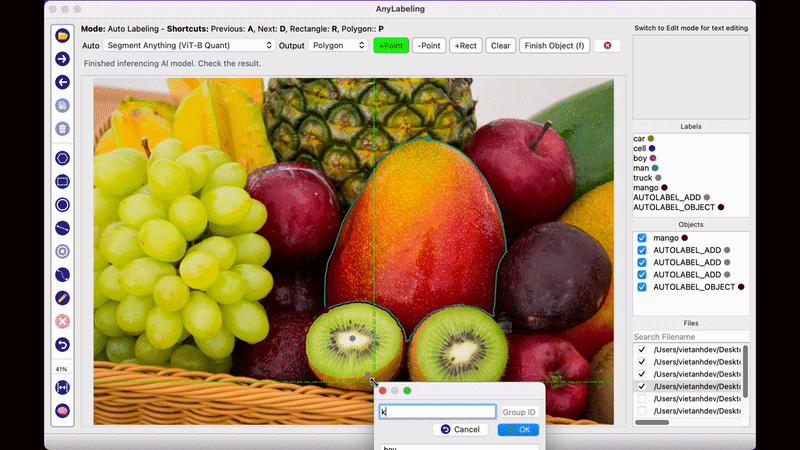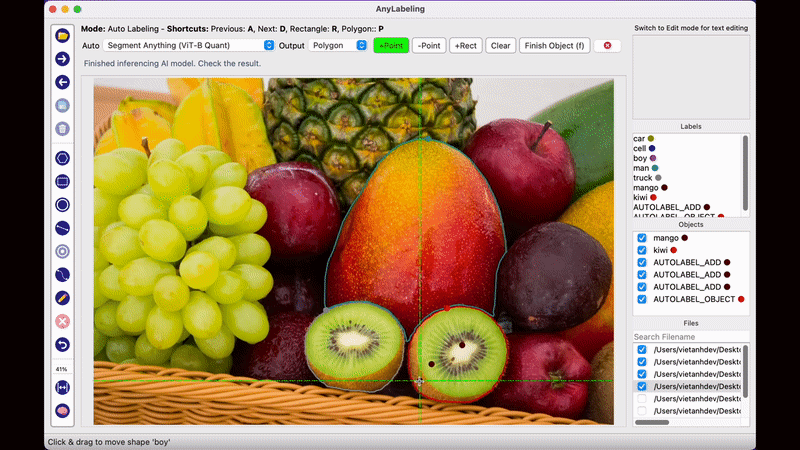
AnyLabeling의 가장 두드러지는 장점이라면 메타AI에서 공개한 Segment Anything 모델을 사용하여 단지 이미지를 클릭하는 것만으로도 물체를 자동으로 Segmentation Labeling 작업을 해준다는 점입니다. 생각보다 Labeling의 품질도 만족스러워 이전처럼 Labeling을 하기 위해 점을 한땀 한땀 클릭하는 작업을 많이 줄일 수 있을 것으로 보입니다.

2023년 5월 시점에서 AnyLabeling은 SAM과 YOLOv5, YOLOv8 알고리즘을 제공하고 있으며, 자신이 원하는 모델을 추가하여 자동 Labeling 작업을 수행할 수 있습니다.
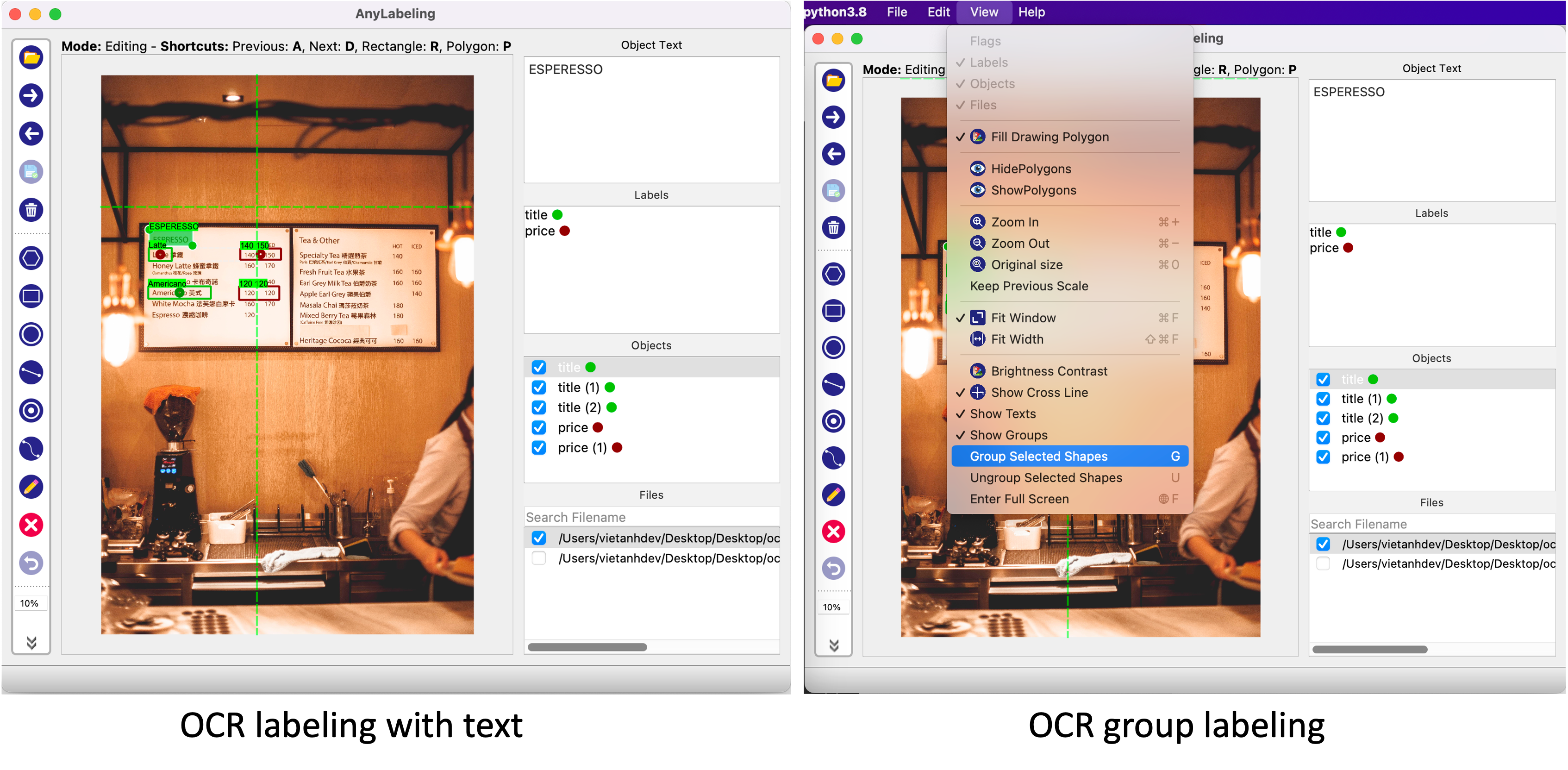
Anylabeling의 또다른 특징 중 하나는 Label에 텍스트 데이터를 남길 수 있다는 점입니다. 단순히 해당 객체의 특징을 설명하기 위한 목적으로도 사용할 수 있지만, 글자 판독 기술인 OCR 데이터를 구축하기 위해 사용하는 방법으로 사용할 수 있습니다. 지금까지 공개된 오픈소스 Labeling Tool 중에서 OCR을 위한 텍스트 데이터를 기록하 수 있는 Tool은 Anylabeling이 그나마 사용하기 편한 것 같습니다.
AnyLabeling은 모든 종류의 운영체제(Windows, Linux, MacOS)에서 사용하실 수 있습니다. AnyLabeling Github 사이트에서 아래의 주소를 통해 자신의 운영체제에 맞는 최신 버전을 설치하여 사용하시기 바랍니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from Segment Anything and YOLO! - vietanhdev/anylabeling
github.com

AnyLabeling에 대해 좀 더 자세한 내용을 알고 싶으신 분은 아래의 공식 페이지를 참조해주시기 바랍니다.
AnyLabeling - Smart Image Labeling Tool – AnyLabeling
Effortless data labeling With AI support from Segment Anything and YOLO models. Get started →
anylabeling.com
'공대생의 팁' 카테고리의 다른 글
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
|---|---|
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (3) | 2023.01.24 |
설정
트랙백
댓글
글
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오래 걸리는 경우가 있습니다. 이는 개발 단계에서 아무리 좋은 GPU를 사용한다 하더라도 해당 GPU에 모델이 최적화 되어있지 않은 경우 GPU의 성능 대비 좋은 성능을 기대하기 어려운 현상이 있습니다.
개발 단계에서 만들어지는 모델은 다양한 환경에서도 실행될 수 있는 소스코드로 배포되어 어떤 환경에서도 구동될 수 있도록 할 수 있습니다. Nvidia에서 공개한 TensorRT와 같은 모델 최적화 라이브러리를 사용하면 특정 환경의 GPU에서 모델의 Inference 속도가 향상되는 것을 확인할 수 있습니다.

그러므로 설계가 완료된 모델을 배포할 때, 모델이 배포되는 환경에서 최적화되어 좋은 성능을 발휘할 수 있도록 관리하는 과정 또한 매우 중요합니다. OpenMMLab에서 공개한 MMDeploy는 지금까지 OpenMMLab에서 공개한 MMDetection, MMSegmentation등과 같은 딥러닝 라이브러리를 특정 환경에서 최적화 설계되어 배포할 수 있도록 해주는 라이브러리입니다.

MMDeploy를 사용하여 MMCV로 설계된 모델들을 범용 딥러닝 모델인 ONNX로 변환하여 다른 딥러닝 라이브러리로 변환하여 사용하거나 TensorRT를 사용해 자신이 사용하고자 하는 GPU에 모델을 최적화하여 사용할 수도 있습니다.
MMDeploy는 아래의 Github 사이트를 통해 소스코드를 다운로드 받으실 수 있습니다.
https://github.com/open-mmlab/mmdeploy
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
Github 공식 사이트를 통해 자신이 구현하고자 하는 환경의 운영체제(Linux, Windows, macOS 등)에서 직접 설치하실 수 있습니다.
다만, 직접 설치하는 과정이 상당히 복잡하기 때문에 만약 Linux 환경에서 사용하고자 하시는 분은 Docker를 사용하여 설치하시는 것을 적극적으로 권장드립니다. Ubuntu에서 Docker를 설치하는 방법은 아래의 사이트를 참조해주시기 바랍니다.
https://dongle94.github.io/docker/docker-ubuntu-install/
[Docker] Ubuntu에 Docker 설치하기
리눅스 OS 중 우분투 OS에서 도커(Docker) 프로그램을 설치하는 방법을 알아본다.
dongle94.github.io
Docker 환경에서 GPU 버전의 MMDeploy 설치를 시도하면 아래와 같은 에러가 발생하는 경우가 있습니다.
docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
이 경우 아래의 블로그에서 소개하는 방법과 같이 nvidia-container-toolkit을 설치해주면 쉽게 해결하실 수 있습니다.
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
https://bluecolorsky.tistory.com/110
[정보] docker: Error response from daemon: could not select device driver with capabilities: [[gpu]] 문제 해결하기
도커를 사용하다 보면 다양한 문제에 맞닥뜨리게 된다. 해결하기 쉬운 문제부터 어려운 문제까지 수많은 문제들이 존재하는데 사용할때마다 항상 다른 오류가 발생하여 문제가 발생할때마다
bluecolorsky.tistory.com
'프로그래밍 팁' 카테고리의 다른 글
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
|---|---|
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
설정
트랙백
댓글
글
MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기)
제가 인공지능에 대해 한창 공부를 할때마다 가장 아쉬웠던 점 중 하나는 자신이 구현하고자 하는 모델에 적합한 데이터를 구하는 것이 어려웠던 것이었습니다. 단지 사람을 감지해내는 기술이 필요한 것이라면 SOTA 알고리즘을 찾은 다음 고성능의 기학습된 모델을 적용하는 것이 가장 좋고 실제로도 제가 다시 재학습 해서 만든 모델보다도 성능이 뛰어나기 때문에 굳이 데이터셋을 직접 만드는 고생을 할 이유가 없기도 합니다.
그러나 내가 구현하고자 하는 물체가 기존의 모델들에 구현되어 있지 않는 경우에는 어쩔수없이 데이터를 수집하여 나만의 데이터셋을 만들어야만합니다. 그러나 기존의 모델들의 성능에 준하는 새로운 모델을 만들기 위해서는 무려 수십만장의 데이터를 수집해야 하는데 이를 개인이 직접 수집하기에는 시간과 비용이 만만치 않습니다.
그렇다면, 내가 원하는 데이터셋을 만들어 이를 테스트해 볼 수 있는 방법은 없는걸까요? 이번 포스팅에서는 Custom Dataset을 본인이 직접 제작하는 방법과 이 데이터셋을 사용하여 MMCV 기반 딥러닝 모델(MMDetection, MMSegmentation)에서 Custom Dataset을 학습해보고자 합니다.

1. 데이터 수집 및 Labeling
원하는 모델 설계에 앞서 자신이 감지하고자 하는 물체가 실제 학습이 가능한지 우선 확인해 볼 필요가 있습니다. 우선 자신이 학습하고자 하는 이미지를 100장 정도 수집한 후 Labeling 작업을 수행합니다. 최근에는 Labeling 작업을 쉽고 효율적으로 수행할 수 있는 Tool들이 많아졌지만 Tutorial 목적으로 작업을 하고자 하시는 분들께서는 추가 비용을 요구하지 않는 오픈소스인 LableMe를 사용해보는 것을 추천 드립니다.
LabelMe를 사용하는 방법에 대해 제가 이전에 정리하였던 자료가 있으니 아래의 포스팅을 참조해주시길 바랍니다.
Lableme로 Coco Dataset과 VOC Dataset 만들기
고성능의 인공지능을 만들기 위한 가장 중요한 작업 중 하나는 최대한 많은 양질의 데이터를 확보하는 것입니다. 상상을 뛰어넘는 인공지능의 놀라운 발전을 보았을 때 마치 AI를 연구하는 사람
elecs.tistory.com
2. 보편적으로 사용되는 Custom Dataset 양식으로 변환
지금까지 공개된 인공지능 모델들의 대부분은 많은 사람들이 자신들이 개발한 소스코드를 쉽게 사용할 수 있도록 설계되어 있습니다. 특히 기존에 공개된 COCO 데이터셋과 PascalVOC는 대중적으로 공개된 퍼블릭 데이터셋으로 누구가 쉽게 접할 수 있어 인공지능에 입문하는 사람들이 처음으로 사용하게 되는 데이터셋이기도 합니다.
위에서 언급한 제 이전의 포스팅 자료에서 소개드렸던 LabelMe로 Labeling 작업을 수행한 다음 COCO 혹은 PascalVOC 데이터셋 양식으로 변경하는 내용에 대해 다루었으니 해당 부분을 참조해주시길 바랍니다.
3. MMCV에서 사용하기
위의 과정을 통해 Custom 데이터셋을 만드셨다면 이를 가지고 OpenMMLab에서 제작한 MMCV에서 바로 사용하실 수 있습니다. LableMe를 통해 제작한 Custom Dataset으로 MMDetection과 MMSegmentation에서의 동작을 확인하였습니다. 각 프로젝트에 바로 사용할 수 있는 데이터셋 양식은 다음과 같습니다. 나머지 데이터셋 양식의 경우 추가적인 설정을 해주시면 사용하실 수 있습니다.
MMDetection: COCO Dataset
LabelMe를 기준으로 Custom Dataset을 Coco 방식으로 변활할 때 Label을 수행한 Json 파일을 Train 용도와 Test 용도로 구분한 다음 각 용도별 Dataset을 Coco로 변환하면 Train 그리고 Test 수행을 위한 Annotation.json 파일을 생성할 수 있습니다.
위의 과정을 통해 생성된 Coco Dataset은 MMDetection에서 제공되는 config 파일에 있는 기본 dataset을 수정하여 자신의 환경에 맞도록 고쳐주시면 바로 사용하실 수 있습니다.
/mmdetection/configs/_base_/datasets/coco*.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/' #Custon Coco Dataset의 폴더 위치
....
#Train, Val, Test 데이터의 Json 및 이미지 파일 경로
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/train.json',
img_prefix=data_root + 'train/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json',
img_prefix=data_root + 'val/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/test.json',
img_prefix=data_root + 'test/',
pipeline=test_pipeline))
....
|
cs |
MMSegmentation: PascalVOC
LableMe에서 labelme2voc로 변환한 데이터들은 MMSegmentation에서 바로 사용하실 수 있습니다. 여기서 만들어진 Segmentation 이미지들 중에서 train.txt, val.txt, test.txt로 사용하고자 하는 파일들의 제목들을 작성해주시고 아래와 같이 Custom Dataset으로 구성하실 수 있습니다.
/mmsegmentation/configs/_base_/datasets/custom_voc12.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
# dataset settings
dataset_type = 'PascalVOCDataset'
data_root = 'data/VOCdevkit/VOC2012' # Custom Voc 데이터셋의 폴더 위치
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='test.txt',
pipeline=test_pipeline))
|
cs |
'프로그래밍 팁' 카테고리의 다른 글
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
|---|---|
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
