검색결과 리스트
글
Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법
공대생의 팁
2025. 1. 14. 15:27
Huggingface 라이브러리에서 제공되는 Transformer 모델을 테스트해보기 위해 PC에 실행 환경 구축을 시도해보고 있었습니다. trasforemrs, datasets 등 필요한 pip 라이브러를 설치한 후 아래와 같은 방법으로 python 스크립트를 작성하였습니다.
|
1
2
|
from datasets import load_dataset
ds = load_dataset('scene_parse_150', trust_remote_code=True)
|
cs |
그런데 데이터셋 다운로드가 진행되는 과정이 갑자기 중단되면서 에러가 발생합니다.
asyncio.exceptions.TimeoutError
fsspec.exceptions.FSTimeoutError
출력된 에러를 분석해보니 다운로드가 더이상 진행이 되지 않는 상황이 발생하였을 경우 datasets 라이브러리에서 다운로드를 중단시켜버립니다. 해당 라이브러리에서 다운로드 진행이 1초 이상 되지 않으면 프로그램이 종료되도록 설정되어 있는 것으로 제한시간을 넉넉하게 잡아주면 해결될 것 같아 아래와 같이 스크립트를 작성하였습니다.
|
1
2
3
4
5
|
from datasets import load_dataset
import aiohttp
ds = load_dataset('scene_parse_150',
trust_remote_code=True,
storage_options={'client_kwargs': {'timeout': aiohttp.ClientTimeout(total==3600)}})
|
cs |
위와 같이 설정해주었더니 다운로드가 끊기지 않고 완료되는 것을 확인할 수 있었습니다.
300x250
'공대생의 팁' 카테고리의 다른 글
| Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법 (0) | 2025.10.28 |
|---|---|
| 티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법 (0) | 2025.05.20 |
| Flask 라이브러리로 이미지를 업로드하고 볼 수 있는 서버 구축하기 (0) | 2024.10.26 |
| Windows Powershell에서 python 실행시 환경변수 설정 방법 (0) | 2024.05.28 |
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
설정
트랙백
댓글
글
VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법
프로그래밍 팁
2025. 1. 2. 00:11
매번 Ubuntu의 새로운 버전이 나올 때마다 평소대로 Virtualbox에 설치하여 체험을 해왔습니다만 이번 버전에서는 미묘한 변화로 인해 기존의 방식대로 설치가 되지 않는 문제가 발생하여 혹시나 저와 같은 문제가 있으신 분들을 위해 제가 설치했던 방법을 여러분들께 전달드리고자 합니다.
1. VirtualBox에 Ubuntu 24.04를 설치한 후 장치→ 게스트 확장 CD 이미지 삽입... 을 클릭하여 게스트 확장 CD를 가상머신에 삽입합니다.

2. 바탕화면에서 CD 아이콘이 생성되는 것을 확인하실 수 있습니다. 해당 아이콘을 클릭합니다.

3. 게스트 확장 설치 폴더가 열립니다. '프로그램 실행' 버튼을 눌러 설치를 진행합니다.
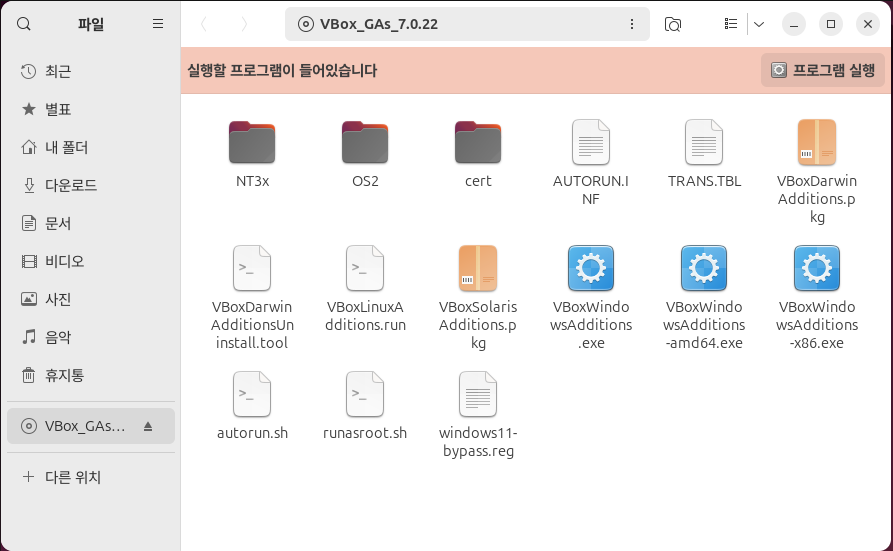
4. 관리자 권한 획득을 위한 비밀번호 입력 후 설치가 진행됩니다. 혹시 아래와 같은 화면이 나올 경우 Terminal에서 다음과 같은 명령어를 입력하여 bzip2를 설치합니다.
$ sudo apt install bzip2
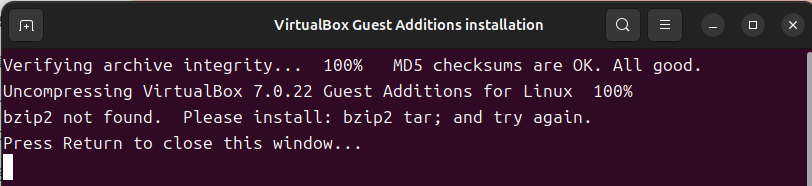
아래와 같은 화면이 나온다면 VirtualBox Guest Addition이 정상적으로 설치되고 있는 것입니다.

이제 Ubuntu 가상머신을 껏다 키면 아래와 같이 해상도가 VirtualBox의 창 크기에 맞추어 변경되는 것을 확인하실 수 있습니다.

300x250
'프로그래밍 팁' 카테고리의 다른 글
| libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent (0) | 2025.07.02 |
|---|---|
| git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed (0) | 2025.03.17 |
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
설정
트랙백
댓글
글
Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법
프로그래밍 팁
2024. 12. 28. 16:39
지금까지 Ubuntu를 사용할 때 마다 apt를 사용시 다운로드 속도를 빠르게 하기 위해 mirror.kakao.com을 사용하고 있었습니다. 이번에 24.04에서도 미러사이트를 변경하려 하였는데 기존처럼 vi로 /etc/apt/sources.list 파일을 수정하려 했더니 이번 버전부터는 구조가 변경되어 아래 폴더에서 설정하는 것으로 변경되었습니다.
/etc/apt/sources.list.d/ubuntu.sources
위 폴더 내에 있는 파일 내에 설정된 kr.archive.ubuntu.com을 mirror.kakao.com으로 변경해주면 기존처럼 카카오 미러를 통해 apt를 설치할 수 있게 됩니다.
Ubuntu 데스크탑 버전을 사용하는 경우 아래와 같은 방법으로 좀 더 쉽게 apt저장소 사이트를 변경할 수 있습니다.
1. 데스크탑 왼쪽 윗부분을 마우스로 클릭합니다.

1. 검색창에 영어로 'soft'를 입력해주면 아래와 같은 화면이 나옵니다. '소프트웨어 및 업데이트'를 클릭합니다.
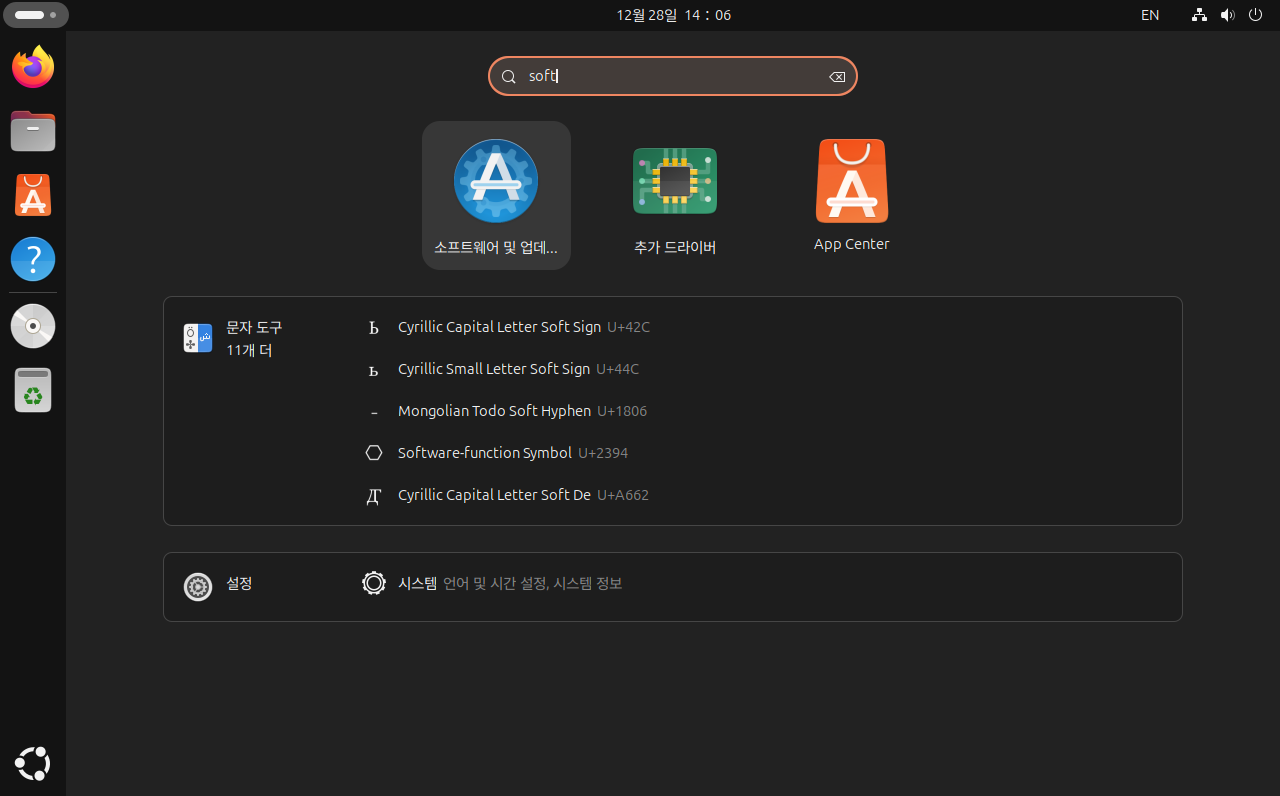
2. 설정 화면에서 '다운로드 위치' 클릭 후 '기타...'를 클릭합니다.

3. 아래와 같은 화면이 나왔다면 '대한민국→mirror.kakao.com'을 선택한 후 '서버 선택'을 클릭합니다.

4. Terminal에서 'sudo apt update' 명령어 입력시 apt가 미러사이트에 접속되는 것을 확인할 수 있습니다.

300x250
'프로그래밍 팁' 카테고리의 다른 글
| git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed (0) | 2025.03.17 |
|---|---|
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
