검색결과 리스트
분류 전체보기에 해당되는 글 462건
-
2025.11.28
Ubuntu로 apt 사용시 SSL 인증서 신뢰 문제 발생시 해결방법

- 2025.10.28 Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법
- 2025.09.05 TensorRT 10버전 이후 변환된 모델을 C++에서 Inference 수행 방법(enqueueV3 함수 사용법)
- 2025.08.01 Windows 환경에서 Visual Studio Code로 Libtorch 라이브러리를 사용해 Torchscript 실행 프로그램 빌드 및 실행
- 2025.07.02 libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent
- 2025.06.02 Libtorch 이전 버전을 다운로드 하는 방법
- 2025.05.20 티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법
- 2025.04.03 포항 영일만 바닷가를 옆에 두고 - 영일만항선 영일만항역(2025.04.01)
- 2025.03.17 git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed
- 2025.02.20 Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법
- 2025.01.14 Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법
- 2025.01.02 VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법
글
Ubuntu로 apt 사용시 SSL 인증서 신뢰 문제 발생시 해결방법
Ubuntu 환경에서 apt로 CUDA를 deb 패키지로 설치하기 위해 Nvidia 공식 페이지의 설명대로 key를 등록 후 아래와 같은 명령어를 입력했습니다.
sudo apt update
그런데 아래와 같은 오류가 발생하였습니다.
Certificate verification failed: The certificate is NOT trusted. The certificate issur is unknown
위 에러는 웹에 접근시 SSL 인증서를 확인하는 과정을 거치는데 모종의 사유로 SSL 인증서가 변조되어 신뢰할 수 없는 상황에서 발생하는 메시지입니다. 특히 사내망에서 보안 목적으로 SSL 인증서가 변조되는 경우인데 다음과 같이 명령어를 추가해주면 SSL 인증 확인을 무시하고 apt 명령어를 사용하실 수 있습니다.
sudo apt -o Acquire::https::Verify-Peer=false update
'공대생의 팁' 카테고리의 다른 글
| Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법 (0) | 2025.10.28 |
|---|---|
| 티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법 (0) | 2025.05.20 |
| Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법 (0) | 2025.01.14 |
| Flask 라이브러리로 이미지를 업로드하고 볼 수 있는 서버 구축하기 (0) | 2024.10.26 |
| Windows Powershell에서 python 실행시 환경변수 설정 방법 (0) | 2024.05.28 |
설정
트랙백
댓글
글
Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법
지난 2025년 10월 15일부로 Windows 10 공식 지원이 완전 종료됨에 따라 사용하던 PC의 운영체제를 바꾸어야 하는 상황이 되었습니다. 안타깝게도 제가 사용중인 PC의 성능이 Windows 11 최소 사양을 충족하지 못해 우여곡절 끝에 멀티부트로 Ubuntu를 설치하고, 불가피한 상황에는 Windows 10을 사용하기로 했습니다.
학생 시절 개발자 짬이 어디 안가서 Ubuntu를 설치하자마자 내가 원하는 환경에 맞추어 프로그램 및 라이브러리를 추가로 설치했습니다. 인터넷 브라우저도 기본 제공되는 FireFox 대신 Google Chrome을 설치해 사용하기로 했습니다.
그런데 이러한 과정에서 생각지도 못한 상황이 발생하였습니다. 저는 평소에 Windows에서 Youtube 영상을 보면서 다른 작업을 하고 싶을 때 저는 PIP(Picture in Picture)모드로 동영상을 모니터의 구석에 띄어두고 작업을 했었습니다.

Chrome 우상단의 동영상 제어 버튼 클릭 후 해당 유튜브 동영상의 'PIP 모드 시작' 버튼을 클릭 한 다음
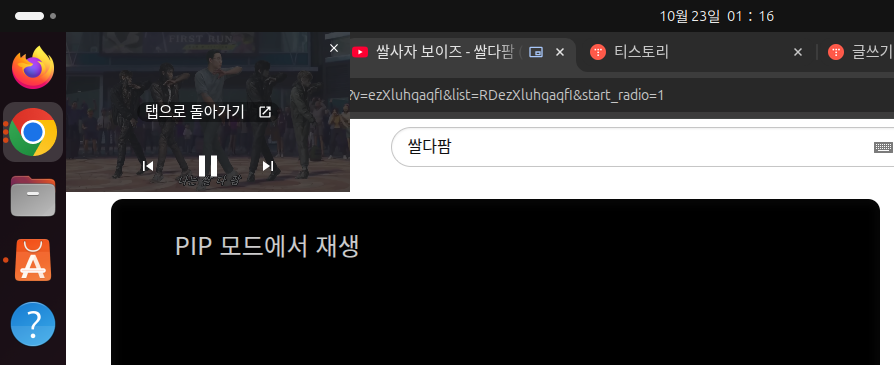
동영상이 별도의 창으로 분리되었을 때 Chrome의 다른 탭을 눌렀더니

놀랍게도 PIP모드로 띄어두었던 동영상이 난데 없이 사라져버렸습니다. 동영상의 사운드는 끊기지 않고 재생되는 것으로 보아 Ubuntu에서의 설정 문제로 보였고, 원인 해결을 위해 GPT에게 질문을 해보았습니다.
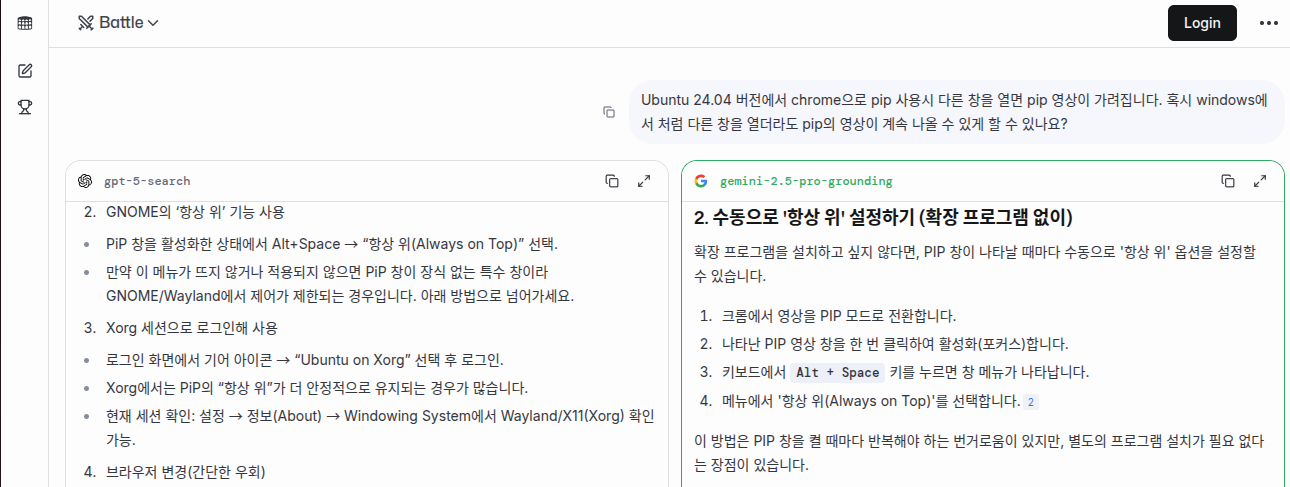
결과를 확인해보니 Linux 버전의 Chrome에서는 PIP모드 실행시 동영상 창의 설정이 '항상 위'로 되어 있지 않은 모양입니다.
GPT가 설명한 대로 PIP 모드로 동영상 창을 띄운 다음 Alt + Space 키를 누르니 아래와 같은 메뉴가 나타났습니다.
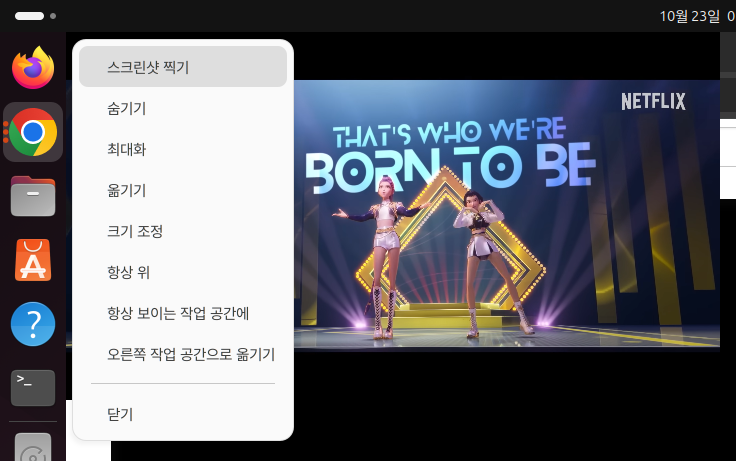
해당 메뉴에서 '항상 위'를 클릭한 다음 다른 탭을 열어보니

성공적으로 PIP 동영상 창이 사라지지 않고 항상 떠잇는 것을 확인하였습니다.
'공대생의 팁' 카테고리의 다른 글
| Ubuntu로 apt 사용시 SSL 인증서 신뢰 문제 발생시 해결방법 (0) | 2025.11.28 |
|---|---|
| 티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법 (0) | 2025.05.20 |
| Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법 (0) | 2025.01.14 |
| Flask 라이브러리로 이미지를 업로드하고 볼 수 있는 서버 구축하기 (0) | 2024.10.26 |
| Windows Powershell에서 python 실행시 환경변수 설정 방법 (0) | 2024.05.28 |
설정
트랙백
댓글
글
TensorRT 10버전 이후 변환된 모델을 C++에서 Inference 수행 방법(enqueueV3 함수 사용법)

※본 글을 작성했던 2025년 8월 당시 TensorRT 코드 작성을 GPT 4o에가 요청시 TensorRT 8버전을 기준으로 C++에서 Inference 수행시 'enqueueV2'를 사용하는 것으로만 코드 작성을 해줘서 온갖 고난 끝에 참고자료 페이지의 자료를 찾아내 enqueueV3() 함수 사용 방법을 작성하였습니다. 그런데 GPT5가 2024년 10월 1일까지의 자료를 학습하게 됨으로서 지금은 TensorRT 10 버전 기준으로 enqueueV3 함수를 잘 작성해줍니다.
TensorRT 10 버전이 등장하면서 변환된 모델을 C++에서 Inference 수행시 enqueueV3() 함수를 사용하여야 하며, 기존 8버전에서 사용했던 enqueueV2() 함수를 더이상 사용되지 않게 되었습니다. TensorRT 버전 변경에 따라 코드 변경 사항이 많아져 방법을 찾다가 아래 링크의 참고자료의 내용대로 코드를 작성하니 TensorRT 10 기준으로 변환된 AI모델이 잘 동작하는 것을 확인할 수 있었습니다.
아래의 소스코드는 퍼플렉시티AI의 도움으로 소스코드 설명을 주석으로 작성하였습니다. 아래의 흐름대로 코드를 작성하시면 TensorRT 10버전 이후 enqueueV3() 함수를 작성하는데 큰 어려움은 없을 것입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
|
#include <fstream>
#include <iostream>
#include <memory>
#include <vector>
#include <string>
#include <opencv2/opencv.hpp>
#include <NvInfer.h>
#include <cuda_runtime_api.h>
// CUDA 에러 체크 매크로 및 함수
#define CHECK_CUDA_ERROR(val) check((val), #val, __FILE__, __LINE__)
void check(cudaError_t err, const char* const func, const char* const file, const int line) {
if (err != cudaSuccess) {
std::cerr << "CUDA Runtime Error at: " << file << ":" << line << std::endl;
std::cerr << cudaGetErrorString(err) << " " << func << std::endl;
std::exit(EXIT_FAILURE);
}
}
// TensorRT 로그 출력을 위한 커스텀 Logger 클래스
class CustomLogger : public nvinfer1::ILogger {
void log(nvinfer1::ILogger::Severity severity, const char* msg) noexcept override {
// info 이하 레벨만 출력
if (severity <= nvinfer1::ILogger::Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
// TensorRT 객체 자동 삭제를 위한 Deleter 구조체
struct InferDeleter {
template <typename T>
void operator()(T* obj) const {
delete obj;
}
};
// Pascal VOC 21 클래스 색상 팔레트 (B,G,R 순서, OpenCV는 BGR)
cv::Vec3b getPascalVOCColor(int class_id) {
static const std::vector<cv::Vec3b> palette = {
{ 0, 0, 0}, // 0: background (black)
{128, 0, 0}, // 1: aeroplane
{ 0,128, 0}, // 2: bicycle
{128,128, 0}, // 3: bird
{ 0, 0,128}, // 4: boat
{128, 0,128}, // 5: bottle
{ 0,128,128}, // 6: bus
{128,128,128}, // 7: car
{ 64, 0, 0}, // 8: cat
{192, 0, 0}, // 9: chair
{ 64,128, 0}, // 10: cow
{192,128, 0}, // 11: diningtable
{ 64, 0,128}, // 12: dog
{192, 0,128}, // 13: horse
{ 64,128,128}, // 14: motorbike
{192,128,128}, // 15: person
{ 0, 64, 0}, // 16: potted plant
{128, 64, 0}, // 17: sheep
{ 0,192, 0}, // 18: sofa
{128,192, 0}, // 19: train
{ 0, 64,128} // 20: tv/monitor
};
if (class_id < 0 || class_id >= palette.size()) return {0,0,0};
return palette[class_id];
}
int main(int argc, char** argv) {
// 1. 입력 이미지 경로 및 엔진 파일 경로 지정
std::string image_path = "input.jpg"; // 입력 이미지 파일명
std::string engine_file_path = "end2end.engine"; // TensorRT 엔진 파일명
// 2. OpenCV로 이미지 읽기 (BGR)
cv::Mat img = cv::imread(image_path, cv::IMREAD_COLOR);
if (img.empty()) {
std::cerr << "이미지를 읽을 수 없습니다: " << image_path << std::endl;
return EXIT_FAILURE;
}
// RGB로 변환 (딥러닝 모델은 보통 RGB 입력)
cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
// 3. TensorRT 엔진 역직렬화 및 실행 컨텍스트 생성
CustomLogger logger{};
std::ifstream engine_file(engine_file_path, std::ios::binary);
if (!engine_file) {
std::cerr << "엔진 파일을 열 수 없습니다: " << engine_file_path << std::endl;
return EXIT_FAILURE;
}
// TensorRT 모델을 메모리에 로드
engine_file.seekg(0, std::ios::end);
size_t engine_file_size = static_cast<size_t>(engine_file.tellg());
engine_file.seekg(0, std::ios::beg);
std::unique_ptr<char[]> engine_data(new char[engine_file_size]);
engine_file.read(engine_data.get(), engine_file_size);
std::unique_ptr<nvinfer1::IRuntime, InferDeleter> runtime{nvinfer1::createInferRuntime(logger)};
std::unique_ptr<nvinfer1::ICudaEngine, InferDeleter> engine{
runtime->deserializeCudaEngine(engine_data.get(), engine_file_size)};
std::unique_ptr<nvinfer1::IExecutionContext, InferDeleter> context{
engine->createExecutionContext()};
// 4. 입력/출력 텐서 이름, shape, dtype 확인
// (엔진에 따라 다를 수 있으니 반드시 확인 필요)
const char* input_tensor_name = engine->getIOTensorName(0); // 입력 텐서 이름
const char* output_tensor_name = engine->getIOTensorName(1); // 출력 텐서 이름
nvinfer1::Dims input_dims = engine->getTensorShape(input_tensor_name); // 예: {1, 3, H, W}
nvinfer1::Dims output_dims = engine->getTensorShape(output_tensor_name); // 예: {1, H, W}
int input_batch = input_dims.d[0];
int input_channels = input_dims.d[1];
int input_height = input_dims.d[2];
int input_width = input_dims.d[3];
int output_batch = output_dims.d[0];
int output_height = output_dims.d[1];
int output_width = output_dims.d[2];
// 5. 입력 이미지 전처리 (리사이즈, 정규화, NCHW 변환)
cv::Mat resized;
cv::resize(img, resized, cv::Size(input_width, input_height));
resized.convertTo(resized, CV_32FC3, 1.0 / 255.0); // 0~1 사이의 값으로 Normalization, AI모델이 학습 수행시 설정하였던 값으로 설정
// NCHW로 변환 (OpenCV는 HWC, TensorRT는 NCHW)
std::vector<float> input_tensor(input_channels * input_height * input_width);
std::vector<cv::Mat> rgb_channels(input_channels);
for (int i = 0; i < input_channels; ++i)
rgb_channels[i] = cv::Mat(input_height, input_width, CV_32FC1, input_tensor.data() + i * input_height * input_width);
cv::split(resized, rgb_channels);
// 6. 입력/출력 버퍼 할당 (CUDA)
void* input_device_buffer = nullptr;
size_t input_bytes = input_tensor.size() * sizeof(float);
CHECK_CUDA_ERROR(cudaMalloc(&input_device_buffer, input_bytes));
void* output_device_buffer = nullptr;
size_t output_bytes = output_height * output_width * sizeof(int64_t); // int64 클래스 ID
CHECK_CUDA_ERROR(cudaMalloc(&output_device_buffer, output_bytes));
// 7. TensorRT 실행 컨텍스트에 입력 버퍼 바인딩
context->setTensorAddress(input_tensor_name, input_device_buffer);
// 8. 실제 출력 텐서 shape와 타입 확인
nvinfer1::Dims output_dims = context->getTensorShape(output_tensor_name); // 실제 shape
size_t output_size = 1;
for (int i = 0; i < output_dims.nbDims; ++i) {
output_size *= output_dims.d[i];
}
nvinfer1::DataType output_dtype = engine->getTensorDataType(output_tensor_name);
// 9. 출력 버퍼 할당 및 추론 실행
void* output_device_buffer = nullptr;
size_t output_bytes = 0;
cudaStream_t stream;
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
// 10. 출력 타입에 따라 분기 처리
if (output_dtype == nvinfer1::DataType::kINT32) {
output_bytes = output_size * sizeof(int32_t);
CHECK_CUDA_ERROR(cudaMalloc(&output_device_buffer, output_bytes));
context->setTensorAddress(output_tensor_name, output_device_buffer);
// 추론 실행
bool status = context->enqueueV3(stream);
if (!status) {
std::cerr << "TensorRT 추론 실행에 실패했습니다." << std::endl;
return EXIT_FAILURE;
}
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
// 결과 복사 및 마스킹
std::vector<int32_t> output_tensor(output_size);
CHECK_CUDA_ERROR(cudaMemcpy(output_tensor.data(), output_device_buffer, output_bytes, cudaMemcpyDeviceToHost));
// 마스크 생성
int mask_height = output_dims.d[output_dims.nbDims - 2];
int mask_width = output_dims.d[output_dims.nbDims - 1];
cv::Mat mask(mask_height, mask_width, CV_8UC3);
for (int y = 0; y < mask_height; ++y) {
for (int x = 0; x < mask_width; ++x) {
int class_id = static_cast<int>(output_tensor[y * mask_width + x]);
mask.at<cv::Vec3b>(y, x) = getPascalVOCColor(class_id);
}
}
cv::Mat mask_resized;
cv::resize(mask, mask_resized, img.size(), 0, 0, cv::INTER_NEAREST);
cv::Mat blended;
cv::addWeighted(img, 0.6, mask_resized, 0.4, 0, blended);
cv::cvtColor(blended, blended, cv::COLOR_RGB2BGR);
cv::imwrite("output_masked_voc.jpg", blended);
std::cout << "INT32 타입 결과를 output_masked_voc.jpg로 저장했습니다." << std::endl;
}
else if (output_dtype == nvinfer1::DataType::kINT64) {
output_bytes = output_size * sizeof(int64_t);
CHECK_CUDA_ERROR(cudaMalloc(&output_device_buffer, output_bytes));
context->setTensorAddress(output_tensor_name, output_device_buffer);
// 추론 실행
bool status = context->enqueueV3(stream);
if (!status) {
std::cerr << "TensorRT 추론 실행에 실패했습니다." << std::endl;
return EXIT_FAILURE;
}
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
// 결과 복사 및 마스킹
std::vector<int64_t> output_tensor(output_size);
CHECK_CUDA_ERROR(cudaMemcpy(output_tensor.data(), output_device_buffer, output_bytes, cudaMemcpyDeviceToHost));
int mask_height = output_dims.d[output_dims.nbDims - 2];
int mask_width = output_dims.d[output_dims.nbDims - 1];
cv::Mat mask(mask_height, mask_width, CV_8UC3);
for (int y = 0; y < mask_height; ++y) {
for (int x = 0; x < mask_width; ++x) {
int class_id = static_cast<int>(output_tensor[y * mask_width + x]);
mask.at<cv::Vec3b>(y, x) = getPascalVOCColor(class_id);
}
}
cv::Mat mask_resized;
cv::resize(mask, mask_resized, img.size(), 0, 0, cv::INTER_NEAREST);
cv::Mat blended;
cv::addWeighted(img, 0.6, mask_resized, 0.4, 0, blended);
cv::cvtColor(blended, blended, cv::COLOR_RGB2BGR);
cv::imwrite("output_masked_voc.jpg", blended);
std::cout << "INT64 타입 결과를 output_masked_voc.jpg로 저장했습니다." << std::endl;
}
else if (output_dtype == nvinfer1::DataType::kFLOAT) {
output_bytes = output_size * sizeof(float);
CHECK_CUDA_ERROR(cudaMalloc(&output_device_buffer, output_bytes));
context->setTensorAddress(output_tensor_name, output_device_buffer);
// 추론 실행
bool status = context->enqueueV3(stream);
if (!status) {
std::cerr << "TensorRT 추론 실행에 실패했습니다." << std::endl;
return EXIT_FAILURE;
}
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
// 결과 복사 및 마스킹
std::vector<float> output_tensor(output_size);
CHECK_CUDA_ERROR(cudaMemcpy(output_tensor.data(), output_device_buffer, output_bytes, cudaMemcpyDeviceToHost));
int mask_height = output_dims.d[output_dims.nbDims - 2];
int mask_width = output_dims.d[output_dims.nbDims - 1];
cv::Mat mask(mask_height, mask_width, CV_8UC3);
for (int y = 0; y < mask_height; ++y) {
for (int x = 0; x < mask_width; ++x) {
int class_id = static_cast<int>(output_tensor[y * mask_width + x]);
mask.at<cv::Vec3b>(y, x) = getPascalVOCColor(class_id);
}
}
cv::Mat mask_resized;
cv::resize(mask, mask_resized, img.size(), 0, 0, cv::INTER_NEAREST);
cv::Mat blended;
cv::addWeighted(img, 0.6, mask_resized, 0.4, 0, blended);
cv::cvtColor(blended, blended, cv::COLOR_RGB2BGR);
cv::imwrite("output_masked_voc.jpg", blended);
std::cout << "FLOAT 타입 결과를 output_masked_voc.jpg로 저장했습니다." << std::endl;
}
else {
std::cerr << "지원하지 않는 출력 데이터 타입입니다." << std::endl;
return EXIT_FAILURE;
}
// 11. 자원 해제
CHECK_CUDA_ERROR(cudaFree(input_device_buffer));
if (output_device_buffer) CHECK_CUDA_ERROR(cudaFree(output_device_buffer));
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
return 0;
}
|
cs |
참고자료: https://leimao.github.io/blog/TensorRT-Custom-Plugin-Example/
TensorRT Custom Plugin Example
TensorRT Custom Plugin Implementation and Integration
leimao.github.io
'프로그래밍 팁' 카테고리의 다른 글
| libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent (0) | 2025.07.02 |
|---|---|
| git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed (0) | 2025.03.17 |
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
설정
트랙백
댓글
글
Windows 환경에서 Visual Studio Code로 Libtorch 라이브러리를 사용해 Torchscript 실행 프로그램 빌드 및 실행
Pytorch로 학습한 AI모델을 C++환경에서 구동하는 방법 중 하나인 Torchscript를 사용하기 위해 Libtorch를 다운로드한 후 Torchscript를 불러오는 간단한 예제를 만들어 테스트를 하려 했더나 아래와 같은 에러가 저를 반겼습니다...
Debug Assertion Failed!
File: minkernel\crts\ucrt\src\appcrt\stdio\fopen.cpp
line: 30
Expressing: file_name != nullptr
For information on how your program can cause an assertion failure, see the Visual C++ documentation on asserts.
(Press Retry to debug the application)

위 에러를 해결하기 위해 구글링 및 GPT를 사용해보았으나 마땅한 해답을 찾지 못하였습니다. 저와 같은 에러가 발생하였던 케이스들의 경우들도 오류의 원인 해결에 대한 언급이 없는 것으로 보았을 때 제 환경에서의 문제인 것으로 추정하였습니다.
테스트 수행을 위해 Libtorch 라이브러리 설치 단계부터 차근차근 다시 시도해보았습니다.
1. Pytorch 공식 페이지에서 Libtorch를 설치합니다. Release와 Debug 버전 두 가지 중 하나만 선택하여 다운로드합니다. 2개의 버전을 동시에 사용할 경우 문제가 복잡해질 가능성이 있습니다. 저의 경우 Pytorch 버전과 일치하는 Libtorch를 다운로드하였습니다. 공식 페이지에서는 최신 버전의 Libtorch만 제공되므로 혹시 이전 버전의 Libtorch를 찾고 싶으신 분은 아래의 페이지를 참조해주시기 바랍니다.
Libtorch 이전 버전을 다운로드 하는 방법
Pytorch로 AI모델 프로그래밍을 하다보면 버전 충돌 등으로 인해 과거의 Pytorch 버전을 설치해야 하는 상황에 직면하는 경우가 자주 있다보니 과거의 Pytorch 버전을 설치하곤 합니다. Pytorch 공식 홈
elecs.tistory.com
2. 다운로드한 Libtorch를 압축해제한 후 lib 폴더 경로를 아래와 같이 환경변수 'Path'에 등록합니다.

3. Visual Studio Code를 실행하여 C++ 개발 환경을 설정해줍니다. SHIFT + CTRL + P를 입력하여 명령팔레트에서 C/C++: 구성 편집을 찾아줍니다.

4. 위 과정에서 'c_cpp_properties.json' 파일이 생성됩니다. 아래와 같이 Libtorch에 있는 Library 파일 경로들을 추가해줍니다.
"includePath" [
"${workspaceFolder}/**,
"(Libtorch 설치 경로)/include",
"(Libtorch 설치 경로)/include/torch/csrc/api/include"
]

5. 이번에는 명령팔레트에서 작업:기본 빌드 작업 구성 → C/C++: cl.exe 활성 파일 빌드를 선택합니다.
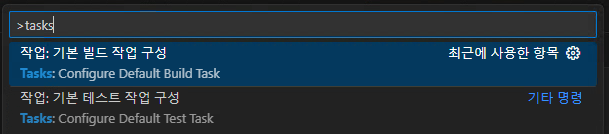
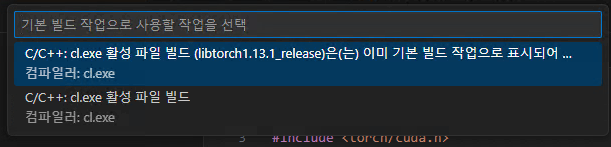
6. 위 과정에서 'tasks.json' 파일이 생성된 것을 확인할 수 있습니다. 파일 내부에 아래와 같이 Libtorch 라이브러리를 설치해줍니다.
"args": [
....
"${file}",
"/I",
"(Libtorch 설치 경로)/include"
"/I",
"(Libtorch 설치 경로)/include/torch/csrc/api/include",
"/link",
"/LIBPATH:(Libtorch 설치 경로)/lib",
"c10.lib",
"torch.lib",
"torch_cpu.lib",
"torch_cuda.lib"
]
7. 이제 VSCode에 Libtorch 라이브러리 관련 설정이 모두 완료되었습니다. 아래의 예제 소스코드를 작성합니다.
test.cpp
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#include <iostream>
#include <torch/script.h>
#include <torch/cuda.h>
using namespace std;
int main(){
torch::jit::script::Module module;
torch::Tensor tensor = torch::rand({1, 3});
cout << "Random Tensor: " << tensor << end;
cout << torch::cuda::is_available() << endl;
try {
torch::Device device(torch::kCUDA, 0); // GPU 사용
torch::Device device(torch::kCPU); // CPU 사용
string script = "end2end.pt";
module = torch::jit::load(script, device);
} catch (const c10::Error& e) {
cerr << "error loading the module \n";
return -1;
}
cout << "ok" << endl;
}
|
cs |
8. 입력한 소스코드를 'Ctrl + Shift + b" 버튼으로 Build를 수행합니다.
위 예제 소스코드 실행에 성공하셨다면 이제 본격적으로 Torchscript를 개발할 수 있는 환경이 갖추어진 것입니다.
'프로그래밍 팁 > Pytorch' 카테고리의 다른 글
| Libtorch 이전 버전을 다운로드 하는 방법 (0) | 2025.06.02 |
|---|---|
| Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법 (0) | 2025.02.20 |
설정
트랙백
댓글
글
libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent
AI모델을 학습하는 과정에서 최신 버전의 Pytorch에서 원활하게 작동되지 않는 케이스가 있어 이전 버전의 Pytorch를 설치후 import 하는 과정에서 아래와 같은 에러가 발생하였습니다.
libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent
이 오류는 주로 PyTorch와 Intel MKL 라이브러리간의 호환성 문제로 발생한다고 합니다. MKL(Intel Math Kernel Library)은 인텔에서 제공하는 고성능 수치 연산 라이브러리로서 최신 MKL 버전에서 일부 심볼이 제거되어 이러한 문제가 발생할 수 있다고 합니다.
해당 오류는 아래의 방법과 같이 MKL의 버전을 낮춤으로서 해결할 수 있었습니다.
conda install mkl==2024.0
또는
pip install mkl==2024.0
'프로그래밍 팁' 카테고리의 다른 글
| TensorRT 10버전 이후 변환된 모델을 C++에서 Inference 수행 방법(enqueueV3 함수 사용법) (0) | 2025.09.05 |
|---|---|
| git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed (0) | 2025.03.17 |
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
설정
트랙백
댓글
글
Libtorch 이전 버전을 다운로드 하는 방법
Pytorch로 AI모델 프로그래밍을 하다보면 버전 충돌 등으로 인해 과거의 Pytorch 버전을 설치해야 하는 상황에 직면하는 경우가 자주 있다보니 과거의 Pytorch 버전을 설치하곤 합니다. Pytorch 공식 홈페이지에서는 Python 에서 동작하는 이전 버전의 Pytorch를 설치하는 방법을 자세히 설명하고 있습니다.
https://pytorch.org/get-started/previous-versions/
Previous PyTorch Versions
Access and install previous PyTorch versions, including binaries and instructions for all platforms.
pytorch.org
그러나 해당 링크를 통해서는 C++ 환경에서 Pytorch로 학습된 AI모델을 구동할 수 있게 해주는 Libtorch의 이전 버전에 대한 설치 방법을 설명하지 않고 있습니다. 최신 버전의 Libtorch의 경우 다운로드 링크를 제공하고 있으나 이전 버전의 링크는 해당 페이지에서는 확인할 수 없습니다.
다행히도 Pytorch 웹페이지를 오픈소스로 공개한 github 페이지에서 이전 버전의 Libtorch 링크를 찾을 수 있습니다.
https://github.com/pytorch/pytorch.github.io/blob/site/published_versions.json
pytorch.github.io/published_versions.json at site · pytorch/pytorch.github.io
The website for PyTorch. Contribute to pytorch/pytorch.github.io development by creating an account on GitHub.
github.com
위 페이지에서 json 양식으로 작성된 파일 내에서 자신이 원하는 Libtorch의 버전을 찾으실 수 있습니다.

'프로그래밍 팁 > Pytorch' 카테고리의 다른 글
| Windows 환경에서 Visual Studio Code로 Libtorch 라이브러리를 사용해 Torchscript 실행 프로그램 빌드 및 실행 (0) | 2025.08.01 |
|---|---|
| Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법 (0) | 2025.02.20 |
설정
트랙백
댓글
글
티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법
평소 PC를 사용할때 의심스러운 프로그램은 절대 설치하지 않는 것을 원칙으로 해왔으며, 프로그램 설치 과정에서 무의식적으로 광고 프로그램 설치 버튼을 누르지 않으려 단계별로 꼼꼼히 확인하며 컴퓨터를 관리해왔던 저의 습관 덕분에 지난 7년동안 단 한번도 악성코드 없는 청정한 환경의 PC를 유지해왔습니다.
그러나 그토록 악성코드를 경계하면서 살아오던 저였습니다만 허무하게도 안타까운 상황이 벌어지고 말았습니다. 언제나 그랬듯이 평소처럼 티스토리에 오랜만에 포스팅을 작성하고자 티스토리에 접속한 다음

'카카오계정으로 로그인' 버튼을 클릭했더니

난생 처음보는 팝업창이 뙇! 하고 로그인창을 가려버립니다. '온라인쇼핑/금융사기 예방방법'이라는 거창한 제목을 적어두고는 'AD'라고 적혀있는 화면에서부터 굉장히 불순한 냄새가 풀풀 풍깁니다..
처음에는 단순한 팝업 예외처리 문제로 해결할 수 있으리라 판단되어 AdBlock을 Chrome 확장프로그램으로 설치하였습니다만 같은 현상이 계속 나타는 것이었습니다. 심지어 저와 같은 현상이 발생하는 다른 블로거 분들의 해결책을 써봐도 도통 해결이 되지 않고 있던 찰나...
우연히 발견한 이 분께서 작성하신 포스팅의 내용대로 제 의도와는 하등 관계없이 컴퓨터에 악성코드가 강제로 설치되어 버렸고 이로 인해 티스토리 로그인을 시도할 때 마다 악질같은 광고창이 계속 뜨는 현상이 발생하는 것임을 알게 되었습니다.
(극강 무료 프로그램) 로그인 시, 팝업광고 노출 악성코드 멀웨어 제거 방법
어느 날, 티스토리 블로그를 하기 위해 [로그인]을 하는 순간, 갑자기 [팝업 광고]가 똭! 하니 등장했습니다. 허걱! ''이게 뭐지?' "뭔가 프로그램(앱)을 깔았나?" "별로 설치한 것도 없는데..."
reportandmore.tistory.com
위 포스팅에서 소개한 악성코드 제거 도구인 'Malware Zero'를 아래의 공식 웹페이지를 통해 바로 다운로드하였습니다.
Malware Zero - 무료 악성코드 제거 도구
악성코드 및 애드웨어 등 각종 유해 프로그램에 의한 고통에서 해방되기 위해 설치 없이 사용 가능한 무료 악성코드 제거 도구
malzero.xyz
Malware Zero를 다운로드한 다음 압축을 해제하면 'malzero'라는 이름의 폴더를 연 다음 'start'를 관리자권한으로 실행하였습니다.
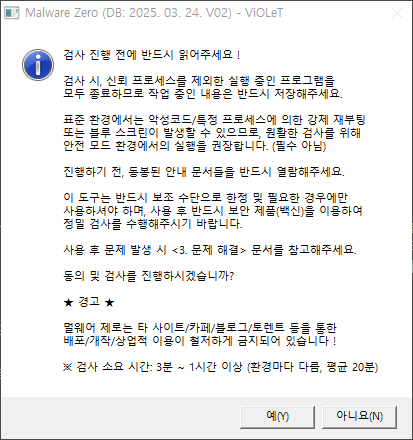
아래와 같은 창들에서 '예'를 클릭하고
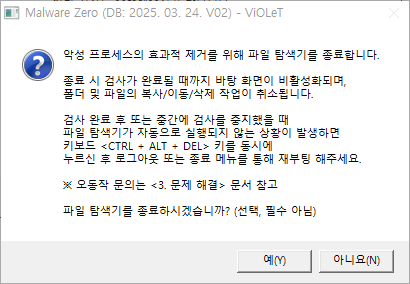
아래의 화면과 같이 Malware Zero가 검사를 수행합니다. 저의 경우 약 20분 정도 수행되었습니다. 한동안 백신 검사를 수행하지 않았어서 그런지 마치 내 하드디스크의 묵은 때를 벆벆 긁어내듯이 악성코드 제거 프로그램이 악성코드를 찾아내는 듯한 느낌이었습니다.
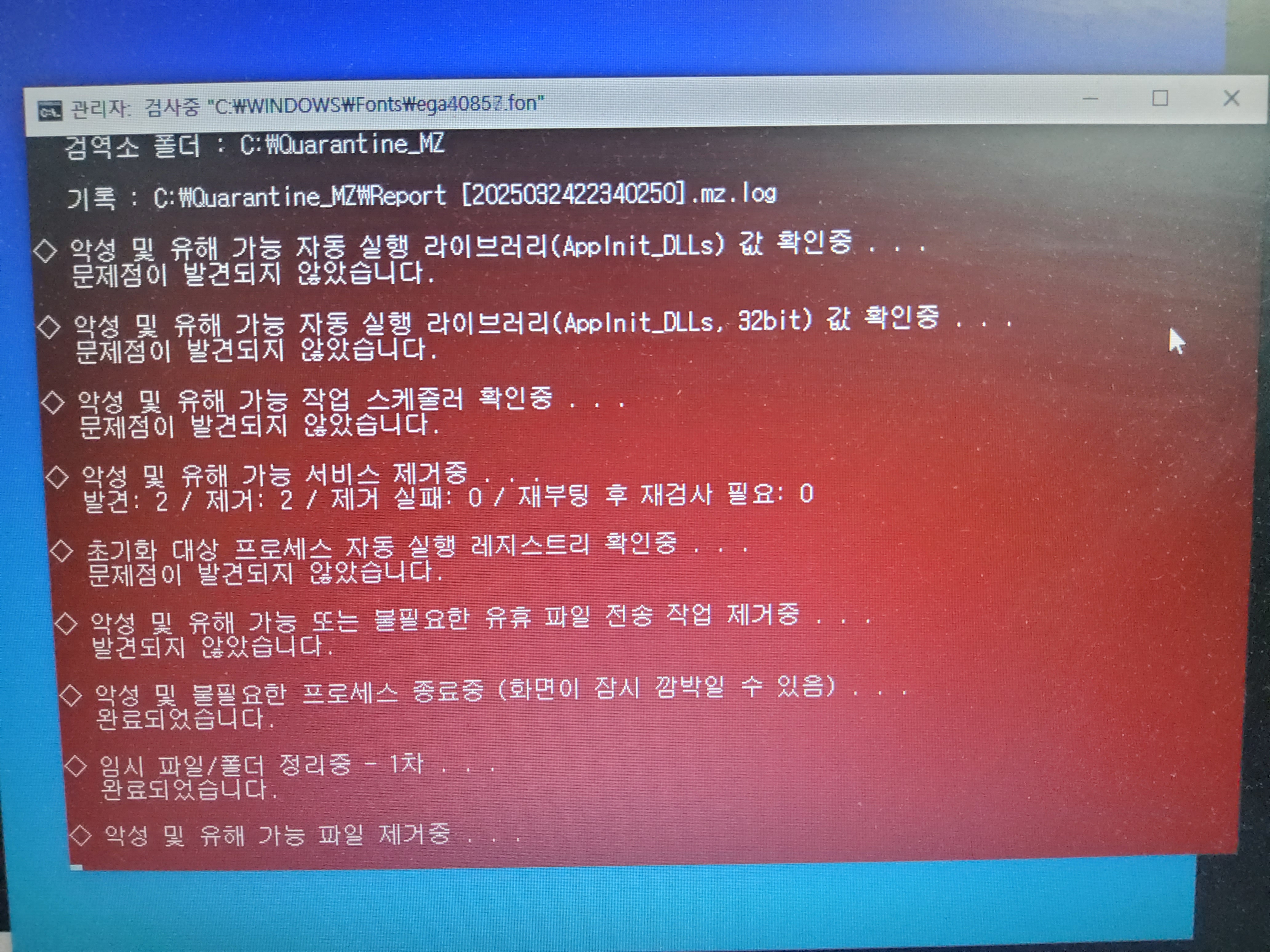
아래와 같은 화면이 나오면 검사가 완료된 것입니다.
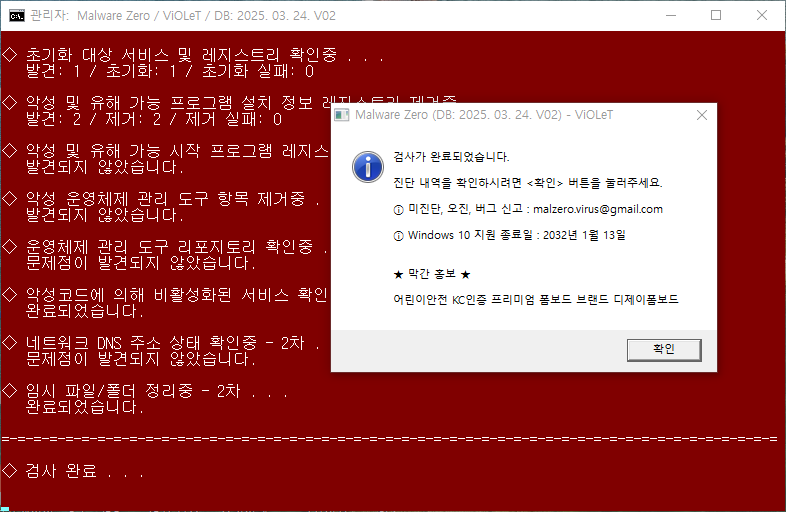
창을 닫자마자 메모장이 열리며 검사 결과를 알려줍니다.(생각보다 너무나도 많은 악성코드들이 발견되어 놀랐습니다. 나름 주의를 기울이며 PC를 써왔음에도 이렇게 속수무책으로 당하고 있었을 줄은 생각도 못했습니다.)

검사가 끝난 후 컴퓨터를 껏다 킨 다음 티스토리 로그인을 시도해보니 다행히도 지금까지 지금껏 저를 괴롭히던 악성 팝업 광고창이 나타나지 않고 있습니다. 이 프로그램으로 원인을 찾아내고 악성코드를 말끔히 제거하니 7년 묵은 제 PC가 새 PC마냥 산뜻해진 듯한 느낌입니다.
혹시 이 글을 보고 계신 여러분들 중에도 저와 같은 현상이 반복되시는 분이 계시다면 지금 바로 Malware Zero를 다운로드하여 PC 내에 악성코드가 있는지 확인해보시기 바랍니다!
'공대생의 팁' 카테고리의 다른 글
| Ubuntu로 apt 사용시 SSL 인증서 신뢰 문제 발생시 해결방법 (0) | 2025.11.28 |
|---|---|
| Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법 (0) | 2025.10.28 |
| Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법 (0) | 2025.01.14 |
| Flask 라이브러리로 이미지를 업로드하고 볼 수 있는 서버 구축하기 (0) | 2024.10.26 |
| Windows Powershell에서 python 실행시 환경변수 설정 방법 (0) | 2024.05.28 |
설정
트랙백
댓글
글
포항 영일만 바닷가를 옆에 두고 - 영일만항선 영일만항역(2025.04.01)
코로나 시기에 서핑이 유행하던 즈음 영일만항 인근에 있는 용한리 해수욕장에서 서핑을 도전해본 적이 있었습니다. 가던 길에 6차선 도로를 철길건널목으로 가르질러 컨테이너가 가득한 항만으로 이어지던 영일만항선 철길이 보았었습니다.
영일만항선은 10년전 포항역이 시내에서 외곽으로 이설되는 과정에서 신축 역사에서 영덕 방면 연장 구간에서 분기하여 영일만항에서 화물을 취급하기 위해 2019년에 신설된 노선으로 여객 취급이 없는 구간이다 보니 이 곳을 찾아오는 분들은 해수욕장을 방문하는 분들이 거의 대부분일겁니다.
지난 여름 서핑을 즐기며 보던 바다의 모습을 다시 한 번 보는 김에 영일만항역을 찾아가 보았습니다.

포항 시내 외곽에 위치한 영일만대로를 쭈욱 달려오면 영일만항로와 접하는 삼거리가 나오는데 바로 그 앞에 보이는 건물이 영일만항역입니다.

3년전에 왔을때엔 없던 역명판을 붙여놓았네요. 항만 내 역의 위치를 확실히 알 수 있게 되었습니다.

영일만대로 북쪽으로 가다보면 6차선을 가로지르는 영일만신항건널목이 나타납니다.

철길이 대로를 비스듬히 지나가다보니 건널목 길이가 꽤 깁니다.

항만으로 들어가는 길은 열차가 통과하지 않는 시간에는 굳건히 닫혀있습니다.

용한리 해수욕장 방향을 바라본 모습

항만 내부 방향으로 찍은 모습입니다.

건널목의 규모가 크지만 열차 통행이 빈번하지는 않아 큰 사고가 날 것 같지는 않을거같습니다.

시내와는 동떨어진 곳이어서 차량도 많이 다니지는 않다보니 건널목을 설치해도 큰 문제는 없어보입니다.

항만에서 곧 열차가 나올 시간이 다가오자 건널목 신호기가 요란한 소리를 내기 시작합니다.

워낙에 넓은 대로에 있는 건널목이어서 차단봉이 휠 정도로 길다랗습니다.

컨테이너 화물이 연결된 기관차가 항만을 빠져나오기 시작합니다.

건널목관리원이 주변 차량들을 통제하고 있습니다.







열차가 통과하는 모습을 보고 가려고 했는데 건널목관리원분께서 저에게 걸어오셔서 뭘 찍고있는지 물어보셨습니다. 열차가 나오는 시간을 어떻게 알고 찾아왔는지 저를 의심하는 질문에 대해 기차를 좋아해서 사진을 찍고 싶어 찾아왔다는 대답을 해드리니 상황을 어느정도 이해하시고 대기실로 돌아가셨습니다.

용한리 해수욕장에서 영일만항을 바라보며 하루를 마칩니다..
'좌충우돌 여행기 > 국내여행' 카테고리의 다른 글
| 2024년의 끝을 앞두고 사라지다 - 중앙선 북영천역(+화본역) (0) | 2024.12.16 |
|---|---|
| 중앙선 이설전 마지막 풍경들 - 의성역~우보역 구간(2024.12.01) (0) | 2024.12.06 |
| 중앙선 이설전 마지막 풍경들 - 북영천역~갑현역 구간(2024.11.22) (0) | 2024.11.23 |
| 중앙선에 남은 마지막 아담한 간이역 - 화본역(2024.07.27) (0) | 2024.09.30 |
| 뒤바뀐 운명 - 중앙선 건천역과 아화역(2024.07.27) (0) | 2024.07.28 |
설정
트랙백
댓글
글
git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed
사내에서 git으로 라이브러리를 다음과 같이 다운로드를 시도하였습니다.
$ git clone https://github.com/open-mmlab/mmcv.git
그런데, 다음과 같은 오류가 발생하였습니다.
fatal: unable to access 'https://github.com/open-mmlab/mmcv.git/': schannel: next InitializeSecurityContext failed: CRYPT_E_REVOCATION_OFFLINE (0x80092013)
위 에러는 사내 보안에 의해 SSL 관련 기능들이 차단되어 발생하는 오류였습니다. 아래와 같이 git에서 ssl체크 기능을 사용하지 않으면 git을 정상적으로 사용할 수 있습니다.
$ git -c http.sslVerify=false clone http://github.com/open-mmlab/mmcv.git/
'프로그래밍 팁' 카테고리의 다른 글
| TensorRT 10버전 이후 변환된 모델을 C++에서 Inference 수행 방법(enqueueV3 함수 사용법) (0) | 2025.09.05 |
|---|---|
| libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent (0) | 2025.07.02 |
| VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법 (0) | 2025.01.02 |
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
설정
트랙백
댓글
글
Pytorch로 학습한 Image AI모델을 Torchscript로 변환 및 실행방법
Torchscript에 대해 검색을 하는 과정에서 제 글을 찾기까지 여러분께서는 Torchscript에 대해 많은 내용들을 배우셨으리라 생각합니다.
그럼에도 수많은 Torchscript에 다룬 글들을 끊임없이 찾다 제 블로그를 발견하신 여러분들이라면 아마도 이러한 고민을 하셨을 것으로 어림 짐작해봅니다.
"간단한 예제들을 보면서 Torchscript에 대해 이해할 수 있었습니다. 하지만 내가 학습한 AI 모델을 Torchscript로 변환하려면 어떻게 해야하죠?
저 또한 지금까지 Torchscript 이론 및 예제들을 익혀보았지만, 실무에 바로 적용하기엔 뭔가 부족한 느낌을 많이 받았습니다. 카메라 영상 데이터를 사용하여 AI모델을 만들고 있는 저에게 있어 영상 데이터를 입력값으로 하는 Torchscript 예제를 찾기가 상당히 어려웠습니다. 다행히도 수없이 많은 구글링과 ChatGPT의 도움 덕에 Torchscript모델을 현업에 적용하는데 간신히 성공하였습니다.
이 포스팅에서는 컬러 이미지를 입력으로 받는 AI모델을 Torchscript로 변환한 후 활용하는 과정들을 기록하였습니다. 혹시나 Torchscript에 대해 이론적인 지식을 필요로 하시는 분들께서는 아래의 자료를 참조해주셨으면 합니다.
https://velog.io/@dev_junseok_22/TorchScript-%EC%86%8C%EA%B0%9C
TorchScript 소개
TorchSciprt는 PyTorch 모델을 프로덕션 환경에서 쉽게 사용할 수 있도록 설계된 언어 및 컴파일러입니다. PyTorch는 주로 연구 및 개발에 사용되는 파이썬 기반의 딥러닝 프레임워크이지만, 프로덕션
velog.io
아래 코드를 통해 Vision AI모델을 TorchScript로 변환하고 실행하는 예제를 확인하실 수 있습니다.
먼저, Pytorch로 학습한 AI모델을 TorchScript로 변환합니다 여기서는 TorchVision에서 제공되는 Pretrained Model을 변환해보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import torch
import torchvision
# TorchVision에서 제공하는 모델을 로드
model = torchvision.models.resnet18(pretrained=True)
# 모델을 평가 모드로 전환
model.eval()
# Trace 방식으로 TorchScript 변환
example_input - torch.randn(1, 3, 512, 512)
traced_model = torch.jit.trace(model, example_input)
# TorchScript 모델 저장
traced_model.save('end2end.pt')
|
cs |
다음은 TorchScript로 변환된 AI모델을 Inference 하는 방법입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import cv2
import numpy as np
import torch
import os
import glob
from torchvision import transforms
# AI모델을 학습하였을 때 사용한 이미지 Dataset의 정보
mean=[95.5142,114.2475,112.4564]
std=[40.0954,43.8636,38.223]
input_size=(512,512)
# 입력 데이터로 사용할 이미지 불러오기
image_path = "input_image.jpg"
img = cv2.imread(image_path)
height, width, c = img.shape
# AI모델의 Input 양식으로 변환
inputs = cv2.resize(img, input_size)
inputs = (inputs - mean) / std
# 이미지 데이터를 PyTorch 텐서로 변환
toTensor = transforms.ToTensor()
input_tensor = toTensor(inputs.astype(np.float32))
# 입력 이미지의 Tensor 차원을 추가함
# RGB 이미지 기준으로 Tensor가 (3,512,512)에서 (1,3,512,512)로 차원이 증가함
# Batch Size가 1인 입력으로 만들어 AI모델에 입력하는 것임
# to('cuda')로 Tensor값을 GPU메모리에 올림
input_batch = input_tensor.unsqueeze(0).to('cuda:1')
# 저장된 TorchScript 모델 로드
script_model = torch.jit.load('end2end.pt')
# 모델을 GPU로 이동
script_model.to('cuda:1')
# 모델을 추론 모드로 설정
script_model.eval()
# 모델 추론
with torch.no_grad():
output = script_model(input_batch)
# 추론 결과를 GPU에서 CPU 메모리로 불러옴
inference_result = output.squeeze().cpu().numpy()
# 추론 결과를 이미지의 원본 크기로 Resize하여 결과 출력
seg = cv2.resize(inference_result, (width, height), interpolation=cv2.INTER_NEAREST)
|
cs |
이번 포스팅을 작성하면서 딥러닝 AI모델을 가공하는 과정들에 대해 다시 한 번 복습할 수 있었습니다.
실무자 입장에서 오픈소스로 공개된 라이브러리들이 이미지 전처리를 포함한 전반적인 학습 과정들을 포함해 잘 갖추어져 있어 가공되지 않은 원본 이미지를 입력으로 하면 곧바로 결과를 확인할 수 있다보니 Vision AI를 연구하는 입장으로서 AI모델의 학습과정에 필요한 기초적인 내용들에 대해 어렴풋이만 알고 있었다가 Torchscript로 변환된 모델을 다루게 되면서 Low 데이터로부터 학습데이터를 가공하는 기술의 중요성을 깨닫게 되었습니다.
최신 AI 기술들의 경향을 따라가는 것은 중요하지만, 가끔은 AI의 기초를 다시 한 번 되짚어보는 것도 좋을것같습니다.
'프로그래밍 팁 > Pytorch' 카테고리의 다른 글
| Windows 환경에서 Visual Studio Code로 Libtorch 라이브러리를 사용해 Torchscript 실행 프로그램 빌드 및 실행 (0) | 2025.08.01 |
|---|---|
| Libtorch 이전 버전을 다운로드 하는 방법 (0) | 2025.06.02 |
설정
트랙백
댓글
글
Huggingface에서 데이터셋 다운로드가 계속 끊길때 해결방법
Huggingface 라이브러리에서 제공되는 Transformer 모델을 테스트해보기 위해 PC에 실행 환경 구축을 시도해보고 있었습니다. trasforemrs, datasets 등 필요한 pip 라이브러를 설치한 후 아래와 같은 방법으로 python 스크립트를 작성하였습니다.
|
1
2
|
from datasets import load_dataset
ds = load_dataset('scene_parse_150', trust_remote_code=True)
|
cs |
그런데 데이터셋 다운로드가 진행되는 과정이 갑자기 중단되면서 에러가 발생합니다.
asyncio.exceptions.TimeoutError
fsspec.exceptions.FSTimeoutError
출력된 에러를 분석해보니 다운로드가 더이상 진행이 되지 않는 상황이 발생하였을 경우 datasets 라이브러리에서 다운로드를 중단시켜버립니다. 해당 라이브러리에서 다운로드 진행이 1초 이상 되지 않으면 프로그램이 종료되도록 설정되어 있는 것으로 제한시간을 넉넉하게 잡아주면 해결될 것 같아 아래와 같이 스크립트를 작성하였습니다.
|
1
2
3
4
5
|
from datasets import load_dataset
import aiohttp
ds = load_dataset('scene_parse_150',
trust_remote_code=True,
storage_options={'client_kwargs': {'timeout': aiohttp.ClientTimeout(total==3600)}})
|
cs |
위와 같이 설정해주었더니 다운로드가 끊기지 않고 완료되는 것을 확인할 수 있었습니다.
'공대생의 팁' 카테고리의 다른 글
| Ubuntu에서 Youtube 동영상 PIP모드에서 다른 창에 의해 화면이 가려질 때 해결방법 (0) | 2025.10.28 |
|---|---|
| 티스토리에서 카카오 로그인시 튀어나오는 팝업 광고 삭제 방법 (0) | 2025.05.20 |
| Flask 라이브러리로 이미지를 업로드하고 볼 수 있는 서버 구축하기 (0) | 2024.10.26 |
| Windows Powershell에서 python 실행시 환경변수 설정 방법 (0) | 2024.05.28 |
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
설정
트랙백
댓글
글
VirtualBox에 Ubuntu 24.04를 설치 후 해상도 확장하는 방법
매번 Ubuntu의 새로운 버전이 나올 때마다 평소대로 Virtualbox에 설치하여 체험을 해왔습니다만 이번 버전에서는 미묘한 변화로 인해 기존의 방식대로 설치가 되지 않는 문제가 발생하여 혹시나 저와 같은 문제가 있으신 분들을 위해 제가 설치했던 방법을 여러분들께 전달드리고자 합니다.
1. VirtualBox에 Ubuntu 24.04를 설치한 후 장치→ 게스트 확장 CD 이미지 삽입... 을 클릭하여 게스트 확장 CD를 가상머신에 삽입합니다.

2. 바탕화면에서 CD 아이콘이 생성되는 것을 확인하실 수 있습니다. 해당 아이콘을 클릭합니다.

3. 게스트 확장 설치 폴더가 열립니다. '프로그램 실행' 버튼을 눌러 설치를 진행합니다.
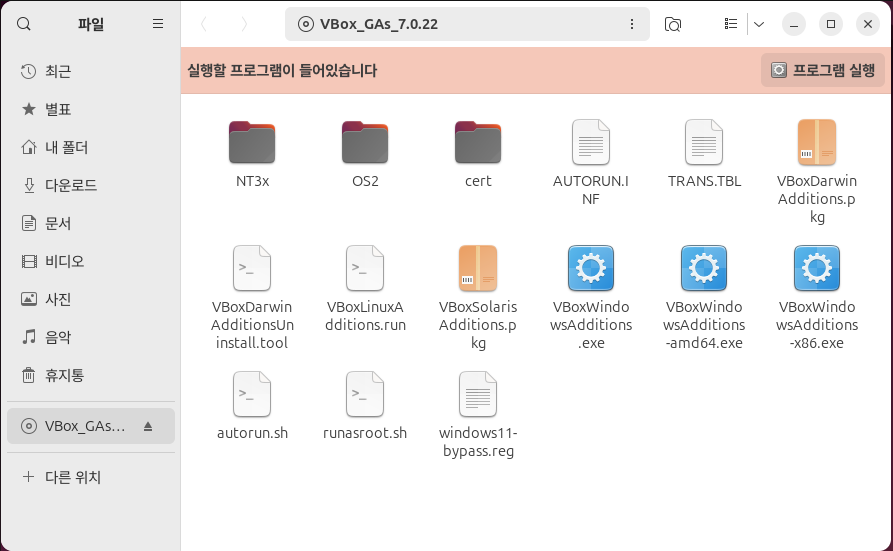
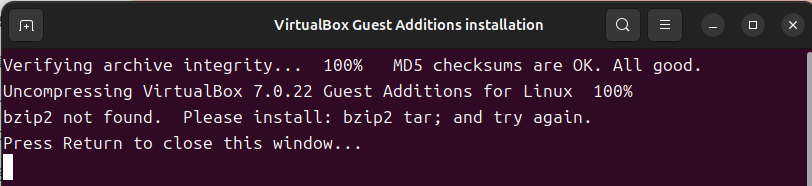
4. 관리자 권한 획득을 위한 비밀번호 입력 후 설치가 진행됩니다. 혹시 아래와 같은 화면이 나올 경우 Terminal에서 다음과 같은 명령어를 입력하여 bzip2를 설치합니다.
$ sudo apt install bzip2
아래와 같은 화면이 나온다면 VirtualBox Guest Addition이 정상적으로 설치되고 있는 것입니다.

이제 Ubuntu 가상머신을 껏다 키면 아래와 같이 해상도가 VirtualBox의 창 크기에 맞추어 변경되는 것을 확인하실 수 있습니다.

'프로그래밍 팁' 카테고리의 다른 글
| libtorch_cpu.so: undefined symbo: iJIT_NotifyEvent (0) | 2025.07.02 |
|---|---|
| git 사용시 오류 발생 해결 방법 - schannel: next InitializedSecurityContext failed (0) | 2025.03.17 |
| Ubuntu 24.04에서 apt 저장소를 mirror 사이트를 변경하는 방법 (0) | 2024.12.28 |
| MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기 (2) | 2024.08.31 |
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
