프로그래밍 팁
MMCV 라이브러리로 Custom AI모델을 만들어보자!(1) - Backbone 추가하기
Justin T.
2024. 8. 31. 23:39
Pytorch는 Meta AI(구 페이스북 AI연구소)에서 만든 딥러닝 라이브러리로, 오늘날 AI 관련 논문등에서 많이 사용되고 있으며 Github를 통해 오픈소스로 공개되는 AI모델 다수가 Pytorch를 사용하고 있습니다. 과거 Google의 TensorFlow가 산업용 AI분야에 주로 사용되고 있다고 알려져 있으나 대학원에서 Pytorch를 접했던 연구원들이 산업 현장에서 Pytorch 사용을 이어가게 되면서 산업용 AI분야에서도 Pytorch의 점유율이 높아져가고 있습니다.
TensorFlow에 비해 Pytorch가 갖는 강점으로 모델 설계가 직관적이고 수정이 쉽다는 점입니다. 다만, Pytorch로 자신이 원하는 모델을 만들 수 있다 하더라도 지금까지 공개된 수많은 모델들을 일일히 공부하고 이를 이해하고 설계를 하는 과정은 개발시간이 소요되며, 개발자별 소스코드의 구조에 차이가 있을 경우 모델 설계를 처음부터 하는 것이 나을 정도로 복잡한 과정이 필요할 수 있습니다. 심지어 같은 구조의 AI모델임에도 소스코드 구조가 달라지게 되면 각각의 모델들이 파편화되어 모델 구조 관리에 더 큰 어려움이 생기게 되기 마련입니다.
OpenMMLab에서 공개한 오픈소스 라이브러리인 MMCV는 자주 사용되는 기능들을 단일화하고, 기본에 공개된 AI모델들을 MMCV 라이브러리로 설계하여 모델들의 구조를 단일화하여 개발자 입장에서 간단하게 소스코드 일부 수정만으로 AI모델을 쉽게 변경할 수 있어 개발이 쉽습니다.
이번 포스팅에서는 MMCV라이브러리에 자신이 직접 모델을 만들어 적용하는 방법을 소개시켜드리고자 합니다.
본 포스팅에서는 MMSegmentation을 기준으로 설명드리도록 하겠습니다. MMSegmentation 라이브러리에서 FCN모델은 Backbone으로 ResNet과 HRNet이 기본으로 적용되어 있는데, 저는 여기에 VGG 백본을 추가해보고자 합니다.
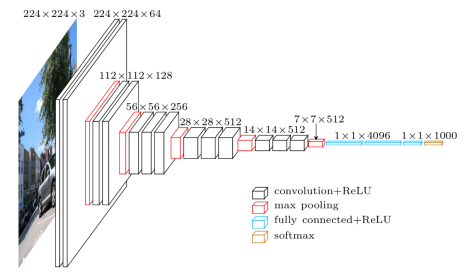
VGG는 2014년 공개된 AI분야 입장에서 보았을 땐 고전 CNN 구조의 모델입니다. 지금 시점에서 보았을 땐 단순한 구조로서 CNN, max pooling, Relu, softmax 등으로 Layer가 구성되어 있어, AI에 입문하시는 분들께서 자신이 직접 AI모델을 만드는 실습자료로 훌륭한 모델 중 하나입니다.
MMCV 라이브러리에서 VGG 모델이 기본으로 제공되고 있어, MMSegmentation에서는 VGG모델을 상속하는 방법으로 Backbone 모델을 추가해보겠습니다. 아래와 같은 경로에 소스코드를 추가해줍니다.
mmseg/models/backbones/FCNVGG.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
import warnings
import torch.nn as nn
from typing import List, Optional, Sequence, Tuple, Union
from mmcv.cnn Import VGG
from mmseg.registry import MODELS
@MODELS.register_module()
class FCNVGG(VGG):
def __init__(self,
depth: int,
with_bn: bool = False,
num_classes: int = -1,
num_stages: int = 5,
dilations: Sequence[int] = (1, 1, 1, 1, 1),
out_indices: Sequence[int] = (0, 1, 2, 3, 4),
frozen_stages: int = -1,
bn_eval: bool = True,
bn_frozen: bool = False,
ceil_mode: bool = False,
with_label_pool: bool = True,
pretrained = None,
init_cfg = None):
super().__init__(
depth,
with_bn,
num_classes,
dilations,
out_indies,
frozem_stages,
bn_eval,
bn_frozen,
ceil_mode,
with_last_pool)
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be specified at the same time'
if init_cfg is not None:
self.init_cfg = init_cfg
elif isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is None:
self.init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(type='Constant', val=1, layer='BatchNorm2d'),
dict(type='Normal', std=0.01, layer='Linear'),
]
else:
raise TypeError('pretrained must e a str or None')
def init_weights(self, pretrained=None):
super().init_weights(pretrained)
def forward(self, x): # should return a tuple
result = super().forward(x)
return result
|
cs |
추가한 Backbone 모델이 mmsegmentation 라이브러리 import시 불러오도록 설정합니다.
mmseg/models/backbones/__init__.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# Copyright (c) OpenMMLab. All rights reserved.
from .beit import BEiT
from .bisenetv1 import BiSeNetV1
from .bisenetv2 import BiSeNetV2
from .cgnet import CGNet
from .ddrnet import DDRNet
from .erfnet import ERFNet
from .fast_scnn import FastSCNN
from .hrnet import HRNet
from .icnet import ICNet
from .mae import MAE
from .mit import MixVisionTransformer
from .mobilenet_v2 import MobileNetV2
from .mobilenet_v3 import MobileNetV3
from .mscan import MSCAN
from .pidnet import PIDNet
from .resnest import ResNeSt
from .resnet import ResNet, ResNetV1c, ResNetV1d
from .resnext import ResNeXt
from .stdc import STDCContextPathNet, STDCNet
from .swin import SwinTransformer
from .timm_backbone import TIMMBackbone
from .twins import PCPVT, SVT
from .unet import UNet
from .vit import VisionTransformer
from .vpd import VPD
__all__ = [
'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT',
'SVT', 'STDCNet', 'STDCContextPathNet', 'BEiT', 'MAE', 'PIDNet', 'MSCAN',
'DDRNet', 'VPD', 'FCNVGG'
]
|
cs |
끝으로, VGG를 Backbone으로 하는 FCN모델을 Config로 구성해줍니다.
fcn_vgg16.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
_base_ = [
'configs/_base_/datasets/cityscapes.py',
'configs/_base_/default_runtime.py',
'configs/_base_/schedules/schedule_40k.py'
]
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
data_preprocessor = dict(
type='SegDataPreProcessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_val=0,
size=(512,512),
seg_pad_val=255)
model = dict(
type='EncoderDecoder',
data_preprocessor=data_preprocessor,
backbone=dict(
type='FCNVGG',
depth=16,
with_last_pool=False,
ceil_mode=True,
init_cfg=dict(
type='Pretrained',
checkpoint='open-mmlab://vgg16_caffe'),
decode_head=dict(
type='FCNHead',
in_channels=512, # VGG모델의 출력 채널수와 일치시킬것
in_index=4, # VGG모델의 출력 Layer중 선택(5개의 Layer중 5번째)
channels=512,
num_convs=2,
concat_input=True,
dropout_ratio=0.1,
num_classes=80,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=512, # VGG모델의 출력 채널수와 일치시킬것
in_index=3, # VGG모델의 출력 Layer중 선택(5개의 Layer중 4번째)
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=80,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg = dict()
test_cfg = dict(mode='whole'))
|
cs |
위와 같이 설정해주신 다음 아래의 명령어를 실행하시면 VGG Backbone이 적용된 AI모델이 학습되는 것을 확인하실 수 있습니다.
$ python tools/train.py fcn_vgg16.py
300x250