공대생의 팁
MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기
Justin T.
2024. 1. 31. 23:53
지난 포스팅에서 OCR(STR)의 개념과 발전 과정에 대해 설명드린 후, MMOCR의 동작 원리에 대해 설명을 드렸습니다. 이번 포스팅에서는 MMOCR에서 사용하고자 하는 데이터셋을 직접 제작하는 방법에 대해 소개드리도록 하겠습니다.
혹시 OCR의 기본 개념 및 원리에 대해 자세히 알고 싶으신 분은 아래 포스팅을 참조해주세요!
https://elecs.tistory.com/434
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적
elecs.tistory.com
1. OCR 데이터셋의 구조
딥러닝 분야에서 OCR은 이미지 내에서 글자를 찿아내는 Text Detection 과정과 이미지내 글자의 의미를 해석하는 Text Recognition 과정으로 분류됩니다. 쉬운 설명을 위해 사진으로 예시를 보여드리겠습니다.
Text Detection은 이미지를 모델에 입력하였을 때, 이미지에서 글자의 위치를 찾아내는 단계라고 보시면 됩니다 예를 들어 아래와 같은 사진이 모델의 Input으로 들어왔다고 가정합니다.

우리들의 눈으로 보았을 때, 위의 이미지에서 Text 정보로는 전철역 출입구 위에 적혀있는 'CC23', 'one-north'을 확인할 수 있습니다. OCR 모델의 출력은 사람이 글씨를 찾아내는 것과 같이 해당 글자 부분을 Object Detection처럼 표시해줄 것입니다.

MMOCR에서 제공하는 Text Detection 데이터셋 구성은 JSON 파일로 Label이 되어 있으며, 다음과 같이 구성됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_50.jpg",
"height": 720,
"width": 1280,
"instances":
[
{
"polygon":[53.0, 137.0, 97.0, 138.0, 97.0, 153.0, 52.0, 151.0]],
"bbox": [52.0, 137.0, 97.0, 153.0],
"bbox_label": 0,
"ignore": false
},
{
"polygon":[107.0, 138.0, 217.0, 143.0, 216.0, 162.0, 106.0, 157.0]],
"bbox": [106.0, 138.0, 217.0, 162.0],
"bbox_label": 0,
"ignore": false
}
]
}
]
}
|
cs |
Text Recognition은 입력된 이미지에서 Text를 추론하는 과정으로서, Text Recognition 모델의 출력은 해당 이미지의 Text입니다.
Text Recognition 모델에 다음과 같은 이미지가 입력되었을 때,

이미지 내의 Text가 Place임을 바로 알아낼 수 있습니다. Text Recognition 데이터셋 JSON Label은 다음과 같이 나타냅니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "word_25.png",
"instances":
[
{
"text": "Place
}
]
}
]
}
|
cs |
2. 기존에 공개된 OCR 데이터셋 사용하기
위에서 설명드린 양식대로 데이터셋을 직접 만들 수도 있지만, MMOCR을 처음 접하는 경우 데이셋의 구조가 바로 이해가 되지 않을 것입니다. 데이터셋을 당장 만들기 어려우신 분이라면, 기존에 공개된 OCR 데이터셋을 사용해보시는 것을 추천드립니다. MMOCR은 공개된 데이터셋을 MMOCR에서 활용할 수 있는 양식의 데이터셋으로 변환하여 사용할 수 있게 해줍니다. 변환된 데이터셋의 구조를 확인하고 이해하신다면 Custom Dataset을 만드시는데 큰 도움이 될 것입니다. MMOCR에서는 총 16개의 데이터셋의 다운로드를 제공하고 있으며, 데이터셋의 목록은 아래의 주소에서 확인하실 수 있습니다.
https://github.com/open-mmlab/mmocr/tree/main/dataset_zoo
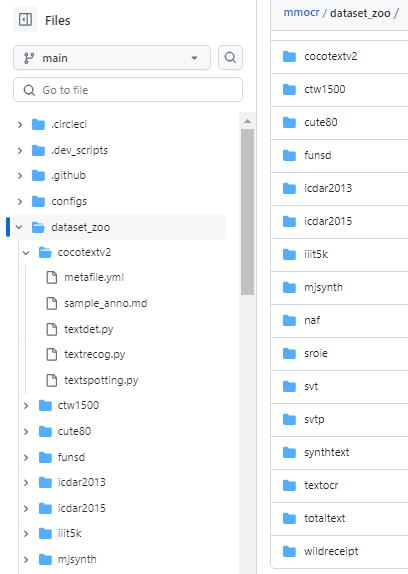
MMOCR에서 제공하는 데이터셋 다운로드 및 변환 기능을 사용해보도록 하겠습니다. 아래의 명령어를 입력하시면 ICDAR 2015 데이터셋을 다운로드한 다음, MMOCR 양식의 데이터셋으로 변환하실 수 있습니다.
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet
위의 명령어를 실행하면, ICDAR 2015 데이터셋을 Text Detection 양식의 데이터셋으로 변환하실 수 있습니다. 만약 Text Recognition 양식의 데이터셋을 원하시는 분께서는 task 옵션에 'textrecog'를 입력하시면 됩니다. 변환된 ICDAR2015 데이터셋을 data 폴더 내에서 확인하실 수 있습니다.
data/icdar2015
├── textdet_imgs
│ ├── test
│ └── train
├── textdet_test.json
└── textdet_train.json3. Tool을 사용하여 Labeling하기(AnyLabeling)
위의 설명을 통해 MMOCR 데이터셋의 구조를 이해하셨다면, 이번에는 우리의 손으로 직접 데이터셋을 만들어보겠습니다. Image 데이터에 Text 레이블링을 할 수 있는 프로그램 중 하나인 AnyLabeling으로 데이터셋을 사용하겠습니다. AnyLabeling은 아래의 github에서 다운로드하실 수 있습니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything, MobileSAM!! - vietanhdev/anylabeling
github.com
AnyLabeling을 설치하신 다음 실행하여 Labeling을 하고자 하는 이미지를 불러옵니다.

위의 사진에서 '71'이라는 텍스트가 가장 먼저 보일 것입니다. 이 부분을 Labeling해보도록 하겠습니다. 좌측에서 사각형 Labeling을 선택하신 후 71을 Bounding Box로 표시해줍니다.
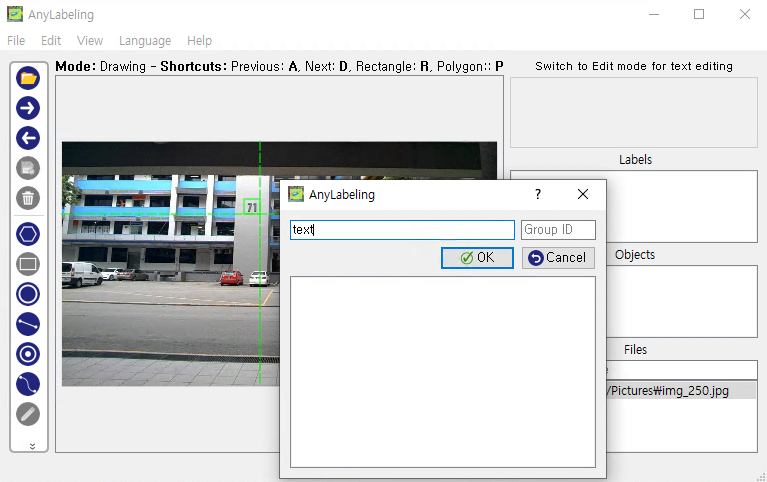
71에 대해 박스 표시가 완료되면, 해당 박스의 Label 정보를 무엇으로 할 지 설정하는 창이 뜰 것입니다. 이 단계에서는 해당 Label의 속성을 설정하는 단계로서, 여기서는 Label의 이름을 'text'로 설정해줍니다. 선택 완료시 labels 목록에 'text'가 추가되었으며, Objects 목록에서도 방금 만든 Box의 객체 정보가 추가된 것을 확인하실 수 있습니다.

다음으로, 방금전에 만든 Object에 Text 정보를 추가해보겠습니다. 좌측 하단에 연필 모양의 아이콘을 클릭하시면 수정모드에 진입하게 됩니다. 그와 동시에 우측 상단에 Text를 입력하는 칸이 활성화 됩니다. 여기서 주의할 것은 해당 칸이 활성화 되자마자 텍스트 정보 입력을 하게 되면, 해당 이미지 자체의 text 정보가 저장이 되버립니다. 방금 만든 '71'에 대한 Label 객체에 대해 text 정보를 추가하기 위해서는, 우측 정보란에 Objects 칸에서 '71'에 해당하는 Object를 목록에서 선택해줍니다.
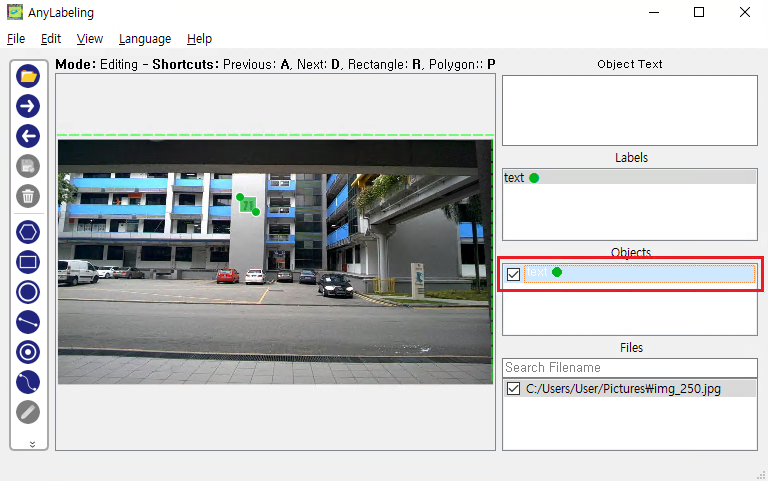
위의 화면에서 빨간색으로 표시한 부분을 클릭하면 '71'에 대한 Label 객체가 선택된 것을 확인하실 수 있으며, Text 정보 입력 칸 윗부분 표시가 'Object Text'로 변경되면서 Text를 입력할 수 있게 되었음을 확인하실 수 있습니다. 여기서 text 정보인 71을 입력해주시면
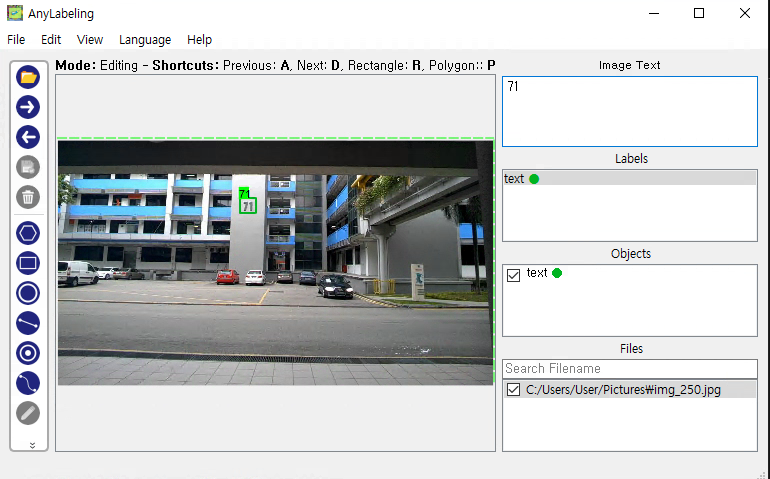
위의 화면과 같이 '71'이라는 text가 해당 Label 객체에 적용된 것을 확인하실 수 있습니다. 위의 과정으로 만든 Label 정보는 아래와 같이 json 양식으로 저장된 것을 확인하실 수 있습니다.

4. OCR 데이터셋으로 변환하기
지금까지 Anylabeling으로 이미지에 Text Labeling을 수행하는 방법에 대해 설명드렸습니다. 위의 과정으로 만든 json 파일을 MMOCR에서 학습할 수 있는 양식으로 변환하는 과정에 대해 설명드리도록 하겠습니다.
먼저, 이미지에서 Text를 찾아내는 과정인 TextDetection 데이터셋으로 변환해보도록 하겠습니다.
Anylabeling2textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import json
import random
import glob
import os
# Anylabeling으로 생성된 Label 데이터
input_path = 'Anylabeling'
# TextDetection 데이터셋으로 변환된 json 파일 저장경로
output_path = 'TextDet'
def extract_instance(shape):
instance = dict()
# 각 Instance별 Bounding Box 좌표값 추출
x1 = int(shape['points'][0][0])
y1 = int(shape['points'][0][1])
x2 = int(shape['points'][1][0])
y2 = int(shape['points'][1][1])
instance['polygon'] = [x1, y1, x2, y1, x2, y2, x1, y2]
instance['bbox'] = [x1, y1, x2, y2]
instance['bbox_label'] = 0
instance['text'] = shape['text']
instance['ignore'] = False
return instance
def create_json(json_list):
metainfo = dict()
# Text Detection 데이터셋
metainfo['dataset_type'] = 'TextDetDataset'
metainfo['task_name'] = 'textdet'
metainfo['category'] = [{'id': 0, 'name': 'text'}]
data_list = []
for file in json_list:
file_path = os.path.join(file)
file_name = os.path.splitext(os.path.basename(file))[0]
# Anylabeling에서 생성된 JSON파일 Load
with open(file_path) as f:
data = json.load(f)
img_info = dict()
# 이미지 파일 경로. 자신의 환경에 맞게 수정.
img_info['img_path'] = os.path.join(input_path, file_name + '.jpg')
img_info['height'] = int(data['imageHeight'])
img_info['width'] = int(data['imageWidth'])
img_info['instances'] = []
shapes = data['shapes']
for shape in shapes:
img_info['instances'].append(extract_instance(shape))
data_list.append(img_info)
json_text = dict()
json_text["metainfo"] = metainfo
json_text['data_list'] = data_list
return json_text
#Input 폴더내 모든 json파일을 불러옴
json_paths = glob.glob(os.path.join(input_path, "*.json"))
#Train-Test셋 데이터 생성(10:1)
random_files = random.sample(json_paths, 11)
remaining_files = [file for file in json_paths if file not in random_files]
trainset = create_json(remaining_files)
testset = create_json(random_files)
with open('textdet_test.json', 'w') as f:
json.dump(testset, f, indent=4)
with open('textdet_train.json', 'w') as f:
json.dump(trainset, f, indent=4)
|
cs |
위 소스코드를 샐행하면 아래와 같이 Text Detection Label 정보가 포함된 json 파일이 생성된 것을 확인하실 수 있습니다.
textdet_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet",
"category": [{"id":0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_250.jpg",
"height": 720,
"width": 1280,
"instances":
[
"ploygon": [536, 169, 583, 169, 583, 213, 536, 213],
"bbox": [536, 169, 583, 213],
"bbox_label": 0,
"text": "71",
"ignore": false
]
}
]
}
|
cs |
다음으로 Text Detection 데이터셋 정보를 설정해줍니다. 아래의 예제는 Text Detection 데이터셋에 대한 설정 파일입니다.
textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
textdet_data_root = 'data/textdet' #Text Detection Label JSON 폴더 위치
textdet_train = dict(
type='OCRDataset',
data_root=textdet_data_root,
ann_file='textdet_train.json',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=None)
textdet_test = dict(
type='OCRDataset'
data_root=textdet_data_root,
ann_file='textdet_test.json',
test_mode=True,
pipeline=None)
|
cs |
Text Detection 모델 중 하나인 TextSnake를 사용하여 위에서 작성한 Data Detection 데이터셋을 적용해보겠습니다.
textsnake.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
_base_ = [
'configs/text/textsnake/_base_textsnake_resnet50_fpn-unet.py',
# Text Detection 데이터셋 추가
'textdet.py',
'configs/textdet/_base_/default_runtime.py',
'configs/textdet/_base_/schedules/schedule_sgd_1200e.py',
]
# dataset settings
train_list = _base_.textdet_train
test_list = _base_.textdet_test
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_list)
val_dataloader = dict(
batch_size=1,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_list)
test_dataloader = val_dataloader
auto_scale_lr = dict(base_batch_size=4)
|
cs |
아래와 같이 한 줄의 명령어를 입력하시면 드디어 Text Detection 데이터셋이 학습되는 것을 확인하실 수 있습니다.
$ python tools/train.py textsnake.py
축하합니다! 여러분들을 드디어 Text Detection 데이터셋을 모델 학습에 적용하실 수 있게 되었습니다. Text Recognition 과정도 거의 비슷하게 진행되니, 잠시 숨을 고른 다음 Text Recognition 데이터셋 학습도 진행해보도록 합시다.
아래의 소스코드를 실행하여 Text Recognition 학습을 위한 json 파일을 생성합니다.
Anylabeling2textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import os
import copy
from PIL import Image
# Anylabeling이 생성한 json 폴더 경로
folder_path = 'Anylabeling'
# Label 저장 경로
save_path = 'output'
# folder_path 내부에 있는 json파일 모두 불러오기
json_files = [file for file in os.listdir(folder_path) if file.endswith('.json')]
# Text Recognition 양식의 JSON 파일 설정
data = {
"metainfo": {
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list": []
}
# Train Set
train = copy.deepcopy(data)
# Test Set
test = copy.deepcopy(data)
# Train-Test Set 분배를 위한 카운터
count = 0
for json_file in json_files:
# .json 확장자 제거
file_name = os.path.splitext(json_file)[0]
with open(os.path.join(folder_path, json_file), 'r', encoding='utf-8') as file:
json_data = json.load(file)
image = Image.open(os.path.join(folder_path, file_name + '.jpg'))
# 이미지에 Label이 있는지 확인
if len(json_data['shapes'] > 0:
shapes = json_data['shapes']
# 이미지 내에 각 Label을 꺼내옴
for i in range(len(shapes)):
# 원본 이미지에서 Text 정보 부분 추출
cropped_image = image.crop((shapes[i]['points'][0][0],shapes[i]['points'][0][1],shapes[i]['points'][1][0],shapes[i]['points'][1][1]))
# 추출된 Text 이미지를 별도의 폴더에 저장
cropped_image.save(os.path.join(save_path, file_name + '_' + str(i) + '.jpg'))
count+=1
# Text 정보를 TextRecognition Dataset 양식으로 저장
new_data = {
"instances": [{"text": shapes[i]['text']}],
"img_path": os.path.join(os.path.join(os.getcwd(), save_path, file_name + '_' + str(i) + '.jpg'))
}
# Train-Test Set 비율을 10:1로 저장
if count % 11 == 0:
test['data_list'].append(new_data)
else:
train['data_list'].append(new_data)
with open("textrecog_train.json", "w") as outfile:
json.dump(train, outfile, indent=4)
with open("textrecog_test.json", "w") as outfile:
json.dump(test, outfile, indent=4)
|
cs |
위 소스코드를 실행하면 Text Recognition Label 양식의 데이터가 적용된 json 파일이 생성된 것을 확인하실 수 있습니다.
textrecog_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"metainfo":
{
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list":
[
{
"img_path": "output/word_1.png",
"instances":
[
{
"text": "71"
}
]
},
]
}
|
cs |
바로 Text Recognition 데이터셋 설정 파일을 만들어줍니다.
textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
textrecog_data_root = 'data/textrecog' #Text Recognition Label JSON 폴더 위치
textrecog_train = dict(
type='OCRDataset',
data_root=textrecog_data_root,
ann_file='textrecog_train.json',
pipeline=None)
textrecog_test = dict(
type='OCRDataset'
data_root=textrecog_data_root,
ann_file='textrecog_test.json',
test_mode=True,
pipeline=None)
|
cs |
거의 다 오셨습니다! SATRN 데이터셋에 방금 만든 Text Recognition 데이터셋을 적용해줍니다.
satrn.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
_base_ = [
'textrecog.py',
'configs/textrecog/_base_/default_runtime.py',
'configs/textrecog/_base_/schedules/schedule_adam_step_5e.py',
'configs/textrecog/satrn/_base_satrn_shallow.py',
]
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=20, val_interval=1)
# dataset settings
train_list = [_base_.textrecog_train]
test_list = [_base_.textrecog_test]
train_dataset = dict(
type='ConcatDataset', datasets=train_list, pipeline=_base_.train_pipeline)
test_dataset = dict(
type='ConcatDataset', datasets=test_list, pipeline=_base_.test_pipeline)
# optimizer
optim_wrapper = dict(type='OptimWrapper', optimizer=dict(type='Adam', lr=3e-4))
train_dataloader = dict(
batch_size=128,
num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
test_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_dataset)
val_dataloader = test_dataloader
#dataset_prefixes는 임의로 설정
val_evaluator = dict(dataset_prefixes=['IC15'])
test_evaluator = val_evaluator
auto_scale_lr = dict(base_batch_size=64 * 8)
|
cs |
아래의 명령어를 통하여 SATRN 모델을 학습합니다.
$ python tools/train.py satrn.py
이제 여러분께서는 MMOCR을 사용하여 Text Detection과 Text Recognition 데이터셋을 만들고 모델을 학습시키는 방법을 터득하였습니다!
300x250