Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++)
대다수의 AI 개발은 Linux 환경에서 이루어지다 보니 Linux환경에서 개발된 오픈소스 라이브러리를 Windows에서 사용하기 위해서는 Windows의 환경에 맞추어 설정을 해야하는 번거로움이 발생하곤 합니다. 사내 자체 개발이 목적이라면 Linux를 사용하는 것이 큰 문제가 되지 않을 수 있으나 고객사에서 Windows 환경에서의 사용을 원한다면 사실상 소스코드를 처음부터 설계한다는 각오를 해야 하기 때문에 개발에 많은 시간이 소요되는 안타까운 사례들이 있습니다.
OpenMMLab에서 공개된 오픈소스 라이브러리인 MMCV는 Linux 환경은 물론, Windows에서도 프로그램이 구동될 수 있도록 지원을 해주고 있습니다. 덕분에 Linux 천하의 Vision AI 개발 환경에서 Windows 운영체제 환경에 맞추어 사용할 수 있는 AI 모델을 개발할 수 있어 개발자의 입장에서 보았을 때 막대한 개발 시간이 소요되는 경우를 막을 수 있습니다.
이번 포스팅에서는 MMCV로 개발된 딥러닝 모델을 MMDeploy로 경량화한 다음, 개발한 딥러닝 모델이 Windows 환경에서 보다 빠르게 구동될 수 있도록 만드는 과정에 대해 다루어보도록 하겠습니다.
※MMDeploy는 OpenMMLab에서 공개한 라이브러리(MMDetection, MMSegmentation 등)를 실제 동작환경에서 경량화 및 가속화를 도와주는 라이브러리입니다. MMDeploy에 대해 자세한 내용은 아래의 포스팅을 참조 바랍니다.
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오
elecs.tistory.com
1. 버전 맞추기
2023년 4월 6일 OpenMMLab 2.0 방식의 최신 소스코드 구조가 적용된 MMDeploy 1.0 버전이 공개었습니다. 자신이 개발한 버전에 따라 해당 버전의 MMDeploy를 설정합니다. 본 예제에서는 MMSegmentation 0.30.0, MMDeploy 0.14.0 버전을 기준으로 작성하였습니다.

git clone https://github.com/open-mmlab/mmdeploy.git
git fetch --all --tags
git checkout tags/v0.14.0
2. MMDeploy 설치
Github를 통해 MMDeploy 소스코드 다운로드를 수행한 다음 MMDeploy을 사용하기 위해 필요한 pip 패키지들을 설치합니다.
pip install mmdeploy==0.14.0 mmdeploy-runtime==0.14.0 mmdeploy-runtime-gpu==0.14.0
3. MMPretrain(구 MMClassification) 설치
설치하시는 MMDeploy 버전이 1.x일 경우 MMPretrain을 설치합니다.
pip install mmpratrain
설치하시는 MMDeploy 버전이 0x.일 경우 MMClassification을 설치해주세요
pip install mmcls
4. ONNX 설치
MMDeploy는 MMCV로 개발된 딥러닝 모델을 ONNX로 변환한 다음 TensorRT로 변환하는 방식으로 2단계 변환을 수행합니다. 다음과 같이 ONNX를 설치합니다. 먼저 pip로 ONNX 패키지를 설치한 다음
pip install onnxruntime==1.8.1
다음으로 아래의 Github 사이트를 통해 onnxruntime 소스코드를 다운로드 받습니다.
https://github.com/microsoft/onnxruntime/releases/
Releases · microsoft/onnxruntime
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator - microsoft/onnxruntime
github.com
5. Nvidia 라이브러리 설치(CUDA, cuDNN, TensorRT)
자신의 환경에 맞는 버전의 CUDA, cuDNN, TensorRT를 설치합니다. cuDNN과 TensorRT 설치를 위해 Nvidia 계정이 필요합니다.
CUDA Toolkit >= 11.1
https://developer.nvidia.com/cuda-toolkit-archive/
CUDA Toolkit Archive
Previous releases of the CUDA Toolkit, GPU Computing SDK, documentation and developer drivers can be found using the links below. Please select the release you want from the list below, and be sure to check www.nvidia.com/drivers for more recent production
developer.nvidia.com
cuDNN >= 8.2.1.0
https://developer.nvidia.com/cudnn/
CUDA Deep Neural Network
cuDNN provides researchers and developers with high-performance GPU acceleration.
developer.nvidia.com
TensorRT >= 8.2.3.0
https://developer.nvidia.com/tensorrt-getting-started/
TensorRT - Get Started
Learn more about NVIDIA TensorRT and check out the latest codes and tutorials.
developer.nvidia.com
6. OpenCV 설치
Image Processing 과정에서 주로 사용되는 OpenCV 라이브러리를 설치합니다.
Python만 사용하실 예정이신 분은 pip를 통해 설치합니다.
pip install opencv-python
C++ 환경에서 TensorRT를 사용하고자 하시는 분은 OpenCV 공식 사이트에서 Runtime 라이브러리를 설치해줍니다. Windows 환경에서 설치하기 위해서는 아래의 사이트를 참조하여 설치해주시기 바랍니다.
https://hello-bryan.tistory.com/29
[OpenCV 설치] Windows OpenCv 설치
OpenCV 설치 Windows OpenCV OpenCV 공식 홈페이지로 갑니다. https://opencv.org 상단 메뉴의 RELEASES 를 클릭하고 원하는 버전의 Win Pack 을 클릭하여 다운로드 페이지로 이동합니다. 광고가 겁나많은 다운로드
hello-bryan.tistory.com
7. 환경변수 설정
위의 과정을 통해 설치하였던 onnxruntime, CUDA, cuDNN, TensorRT 라이브러리를 환경변수 Path에 등록합니다. 또한, CUDA_PATH의 환경변수 또한 다음과 같이 등록해주시기 바랍니다.
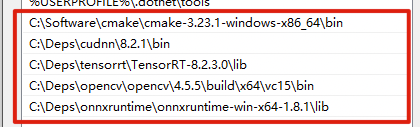
8. Pycuda 설치
Python에서 CUDA 병령 컴퓨팅 API를 수행할 수 있도록 해주는 pycuda를 설치합니다. 만약 설치 과정에서 실패하는 경우 위 6번 과정에서 설치한 라이브러리 환경변수 설정에서 잘못된 경우가 있을 수 있으므로 한 번 더 확인해보시기 바랍니다.
pip install pycuda
9. MMDeploy SDK 설치
Github에 공개된 MMDeploy의 release 라이브러리 탭에서 자신에게 맞는 버전을 선택 후 Assets에서 SDK를 다운로드 받습니다. 여기서는 "mmdeploy-0.14.0-windows-amd64-cuda11.3.zip"을 다운로드 합니다.
https://github.com/open-mmlab/mmdeploy/tags/
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
C++ 환경에서 사용하고자 하시는 경우 SDK를 폴더에 압축해제 하신 다음 Powershell을 실행하여 아래의 경로로 이동해주세요.
mmdeploy-0.14.0-windows-amd64-cuda11.3\example\cpp\build
위 경로로 이동한 다음 C++ SDK를 빌드합니다.
> cmake .. -DMMDeploy_DIR="mmdeploy-0.14.0-windows-amd64-cuda11.3\lib\cmake\mmdeploy" -DTENSORRT_DIR="TensorRT 설치 경로" -DONNXRUNTIME_DIR="onnxruntime 설치 경로" -DOpenCV_DIR="opencv\build\x64\vc15\lib"
> cmake --build . --config Release
10. Model 변환
지금까지 TensorRT를 사용하기 위해 구동 환경에서 MMDeploy를 적용하는 방법에 대해 설명드렸습니다. 이제 본격적으로 자신이 개발한 Model을 배포 환경에서 구동할 수 있도록 변환하는 단계를 진행해보도록 하겠습니다.
Python 소스코드를 아래와 같이 작성한 다음 실행합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from mmdeploy.apis import torch2onnx
from mmdeploy.apis .tensorrt import onnx2tensorrt
from mmdeploy.backend.sdk.expert_info import export2SDK
import os
img = '테스트하고자 하는 이미지 경로'
work_dir = 'TensorRT 변환 모델 저장 폴더 경로'
save_file = 'end2end.onnx'
deploy_cfg = 'mmdeploy/configs/mmseg/segmentation_tensorrt-fp16_static-512x512.py'
model_cfg = 'mmseg/자신이 학습한 모델의 설정.py'
model_checkpoint = '변환하고자 하는 모델.pth'
device = 'cuda'
# 1. convert model to IR(onnx)
torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg, model_checkpoint, device)
# 2. convert IR to tensorrt
onnx_model = os.path.join(work_dir, save_file)
save_file = 'end2end.engine'
model_id = 0
onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, onnx_model, device)
# 3. extract pipeline info for sdk use (dump-info)
export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint, device=device)
|
cs |
위의 소스코드를 실행하시면 work_dir 폴더에 다음과 같은 파일들이 생성된 것을 확인하실 수 있습니다.
deploy.json
detail.json
end2end.engine
end2end.onnx
pipeline.json
11. Inference 코드 구현
이제 여러분들이 개발한 딥러닝 모델이 TensorRT로 변환된 것을 확인하였습니다. TensorRT 최적화 모델을 아래와 같이 실행할 수 있습니다.
- python
> python MMDEPLOY/mmdeploy/tools/deploy.py MMDEPLOY/mmdeploy/configs/mmseg/segmentation_tensorrt-int8_static-512x512.py MMSEGMENTATION/configs/모델 설정 파일.py 학습한 모델.engine "데모 이미지.jpg" --device cuda:0
> python MMDEPLOY/demo/python/image_segmentation.py cuda "work_dir 경로" "데모이미지 경로.jpg"
- C++
> MMDeployDIR/example/cpp/build/release/image_segmentation.exe cuda "work_dir 경로" "데모이미지 경로.jpg"
이제 여러분들도 MMDeploy를 통해 경량화돤 모델이 배포 환경에 맞추어 실행 속도가 굉장히 향상된 것을 확인하실 수 있습니다.
- 참고자료
https://mmdeploy.readthedocs.io/en/v0.14.0/get_started.html#installation
Get Started — mmdeploy 0.14.0 documentation
Get Started MMDeploy provides useful tools for deploying OpenMMLab models to various platforms and devices. With the help of them, you can not only do model deployment using our pre-defined pipelines but also customize your own deployment pipeline. Introdu
mmdeploy.readthedocs.io
https://mmdeploy.readthedocs.io/en/v0.14.0/02-how-to-run/prebuilt_package_windows.html
How to use prebuilt package on Windows10 — mmdeploy 0.14.0 documentation
Docs > How to use prebuilt package on Windows10 以中文阅读 Shortcuts
mmdeploy.readthedocs.io