공대생의 팁
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
Justin T.
2023. 6. 24. 21:02
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적용되면서 생성형 인공지능의 성능은 더 빠르게 발전하는 양상을 보이는 가운데 지식 업무를 수행하는 화이트칼라 사무직들 조차 AI시대에 일자리를 뺏길 위기를 걱정을 하게 되는 세상이 도래하려나 싶은 생각이 드는 요즈음입니다.
다행히도(?) 사람처럼 현실세계에서 길거리의 간판을 쉽게 읽고 이해하는 로봇은 보이지 않는 듯 합니다. 분명 인공지능은 오직 사람만이 구현하리라 믿었던 상상력을 발휘하는 듯 함에도 현실 세계에서 이러한 기능을 실제 로봇에 구현하기에는 시간이 더 필요할 것으로 보입니다.

이번 포스팅에서는 인공지능이 현실세계에서 접할 수 있는 글씨들을 감지하고 이를 해석하는 장면 글자 인식(Scene Text Recognition, 혹은 광학 글자 인식 - Optical Text recognition)에 대해 이해하고 지금까지 공개된 글자 인식 알고리즘들을 총망라한 MMOCR에 대해 소개드리도록 하겠습니다.
사람의 도움 없이 스스로 글자를 읽는 기계?
OCR(Optical Character Recognition) 기술은 이름 그대로 광학 문자 인식 기술을 의미하며, 마치 사람이 글자를 이해하듯이 컴퓨터가 글씨를 사람처럼 읽을 수 있는 기술을 일컫는 말입니다.
딥러닝 기반 인공지능 기술이 활발하게 사용되고 있는 오늘날 관점에서 보면 놀랍게도 OCR 기술은 생각보다 오래전부터 연구된 분야입니다. 초창기의 OCR 기술은 글을 볼 수 없는 시각장애인들을 위해 종이에 적혀있는 글씨를 인식하는 기기에서 에서 시작되었습니다. 1913년, 아일랜드의 물리학자이자 화학자였던 에드먼드 에드워드 푸르니에 달베(Edmund Edward Fournier d'Albe, 1868년 – 1933년 6월 29일)가 발명한 옵토폰(Optophone)의해 OCR 기술이 처음으로 세상에 등장하였습니다.

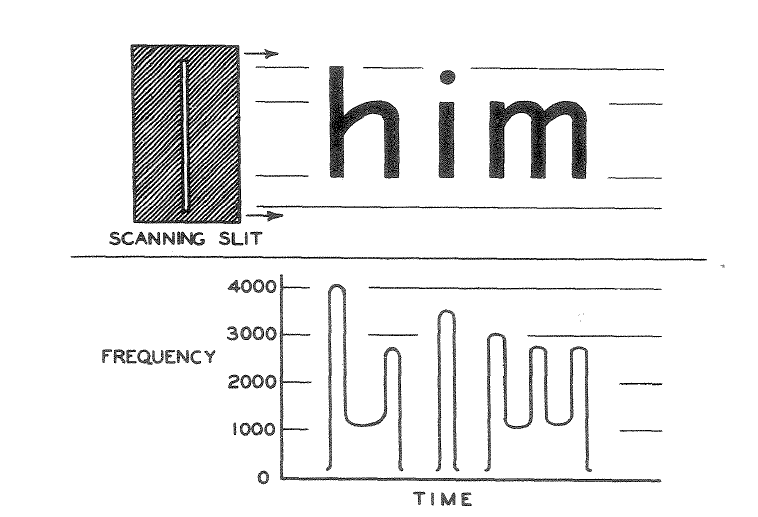
옵토폰은 이름 그대로 빛을 소리로 바꾸어주는 기기로서 광학 센서에 의해 글자의 세로 두께에 해당되는 주파수를 내면 이를 사람이 듣고 어떤 글자인지 알 수 있는 방법으로 발명되었습니다.
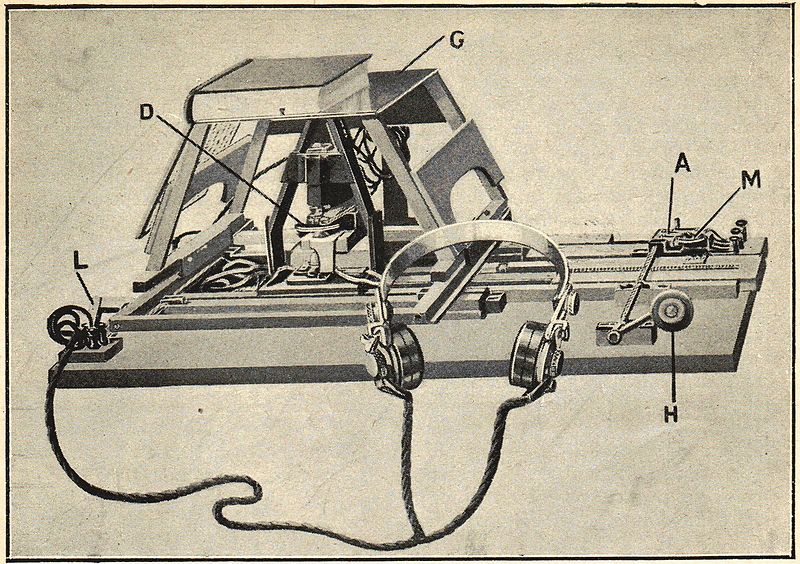
이후에도 인쇄물의 글자를 인식하는 기능들이 지속적으로 발전해왔으며, 오늘날 주로 사용되는 광학 문자 인식기는 로버트 노이스(Robert Norton Noyce, 1927년 12월 12일 - 1990년 6월 3일)가 1977년 발명한 OCR 리더기로서 그 모습을 갖추었습니다. 종이에 적힌 글자를 OCR 리더기로 스캔하면 컴퓨터에 해석된 글자를 전송하는 방식으로 동작하며, 손쉽게 책의 내용을 컴퓨터가 읽을 수 있는 시스템을 갖출 수 있게 되었습니다.

2023년 기준 최근에는 OCR Reader에 인공지능 번역 기능까지 갖춘 상품이 등장하였습니다. 책의 사진을 찍으면 인공지능 번역기로 번역을 해주던 기능은 기존에도 존재했지만 책을 촬영할때 빛과 손떨림 등으로 인해 초점이 맞지 않아 글자가 제대로 보이지 않는 문제점이 있지요. 이러한 단점을 OCR Reader를 사용하여 정확도를 높였고, OCR리더기를 사용하여 글자를 직접 스캔한 다음 이를 번역기에 넣어 돌린다는 아이디어는 상당히 참신해 보입니다.
MMOCR

MMOCR은 OpenMMLab에서 제작한 MM시리즈 중 하나로 공개된 OCR 알고리즘들을 통합한 프로젝트입니다. mmcv, mmdet 라이브러리와 mmocr 소스코드에 맞추어진 모델을 다운로드하여 명령어 단 한줄만으로 손쉽게 ocr을 경험해보실 수 있습니다.
MMOCR은 OCR 모델의 주요한 알고리즘인 Text Detection, Text Recognition을 제공합니다. Text Detection 과정을 통해 이미지에서 글자가 위치한 부분을 Segmentation 방식으로 표시하고, Recognition 단계에서는 Detection 과정에서 찾아낸 글자를 인식하는 과정을 거칩니다.

MMOCR에서 제공하는 예제를 실행하여 OCR의 원리를 빠르게 이해해봅니다. Github에서 MMOCR 소스코드를 다운로드합니다.
$ git clone https://github.com/open-mmlab/mmocr
MMOCR 소스코드를 다운로드한 다음 아래의 명령어를 입력하면 MMOCR에서 기본 설정한 OCR 모델이 자동으로 다운로드 되며 바로 실행되는 것을 확인하실 수 있습니다.
$ python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result
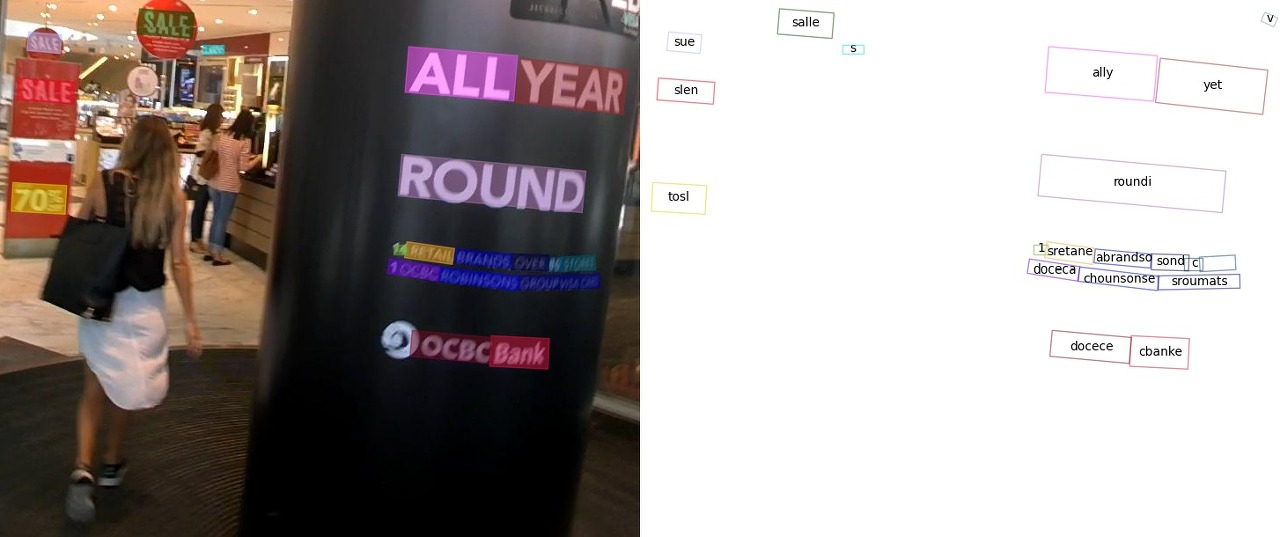
왼쪽의 사진은 이미지에서 글자의 위치를 찾아 표시하는 Text Detection, 오른쪽의 사진은 Text Detection 과정에서 찾은 Text의 글자를 해석하는 Text Recognition 과정을 나타내고 있습니다. 아래는 Text Recognition 결과를 Text로 출력되는 것을 보실 수 있습니다.
# Inference result
{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year',
'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores':
[...]}]}
300x250