검색결과 리스트
공대생의 팁에 해당되는 글 120건
- 2024.03.31 [mmcv] AssertionError: only one of size and size_divisor should be valid
- 2024.03.26 LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법
- 2024.01.31 MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기
- 2023.11.05 MMCV에서 사용되는 pretrained model 주소 알아내는 방법
- 2023.08.12 PowerShell에서 Visual Studio x64 환경으로 개발하기
- 2023.07.29 Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법
- 2023.06.24 MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
- 2023.05.20 AI로 Labeling을 자동으로 더 편하게 - AnyLabeling
- 2023.02.18 Lableme로 Coco Dataset과 VOC Dataset 만들기
- 2023.01.27 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV
- 2023.01.24 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법
- 2023.01.05 Windows에서 scann 라이브러리 설치하기
글
[mmcv] AssertionError: only one of size and size_divisor should be valid
MMSegmentation으로 딥러닝 모델을 실행하는 과정에서 종종 아래와 같은 에러를 접하곤 합니다.
assert (size is not None) ^ (size_divisor is not None),
AssertionError: only one of size and size_divisor should be valid
MMSegmentation github 사이트에서 관련 이슈로 등록된 글을 통해 확인해본 결과, data_preprocessor에서 size 혹은 size_divisor가 설정되어 있지 않아 발생하는 오류라고 합니다. 아래와 같이 data_preprocessor에 size를 추가 설정해주니 소스코드가 정상적으로 동작하는 것을 확인하였습니다.
crop_size = (512, 512)
data_preprocessor = dict(
# ....
size=crop_size)
참고자료: https://github.com/open-mmlab/mmsegmentation/issues/3425
AssertionError: only one of size and size_divisor should be valid · Issue #3425 · open-mmlab/mmsegmentation
I am trying to use mmsegmentation for segmentation of pathology images on my own new dataset. I have 512x512 patches of images and annotations. I am representing four classes of my new dataset as g...
github.com
'공대생의 팁' 카테고리의 다른 글
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법
요새 Dataset Lebeling 작업을 수행하는 과정에서 다양한 방식의 Label 구조 형식들을 접해보고 있습니다. Bounding Box 방식과 같이 단지 마우스 2번의 클릭으로 끝나는 경우가 있는가 하면, Polygon 방식과 같이 사진 내에 있는 모든 Object의 테두리에 점을 하나하나 공들여서 표시해보기도 합니다. Labeling 작업에 왕도는 없지만, 좀 더 데이터를 다루는 것에 초점을 맞추어 데이터의 속성을 이해하여 좀 더 적합한 모델을 찾는데 도움이 되기도 합니다.
2024년 현재도 좋은 AI 모델이 소개되고는 있지만 정제되지 않은 데이터로는 좋은 성능의 AI 모델을 구현할 수 없습니다. 비록 데이터셋 제작에 많은 시간이 소모되더라도 결국은 데이터셋의 품질이 AI모델의 성능을 좌우하는 데엔 그 누구도 이견이 없을 것입니다.
평소와 다름없이 LabelMe로 Labeling한 JSON 파일들을 Coco Dataset으로 변환한 다음, MMDetection으로 모델을 학습시키려 하는 과정에서 다음과 같은 에러를 접하게 되었습니다.
ValueError: need at least one array to concatenate
해당 오류의 원인을 찾아보니 MMDetection에서 원본 coco 데이터셋의 category를 기준으로 설정되어 있어서 우리들이 직접 만든 custom coco dataset의 class명이 원본 coco 데이터셋의 class명과 다를 경우 위와 같은 오류가 나타나는 것이었습니다. 이 문제는 LabelMe로 만든 coco 데이터셋의 class명을 원본 coco 데이터셋과 일치시키면 바로 해결됩니다.
비록 학습시에는 원본 coco 데이터셋의 class명이 출력되시만, 모델 Deploy 수행시 class명을 변경해서 사용할 수 있기 때문에, 학습이 진행되는 동안 출력되는 class명이 다르게 되는 불편함을 감수하실 수 있다면 아래의 소스코드를 다운로드 받은 다음 LabelMe로 작업한 JSON 파일을 변환하여 사용해보시기 바랍니다.
If you get an error like the one above when training mmdetecton on a coco dataset that you converted to LabelMe, download labelme2coco.py below and convert it to that file, and you should be able to train mmdetection cleanly and without errors.
위 소스코드를 다운로드 받으신 다음 LabelMe에서 사용하던 대로 명령어를 입력합니다.
python labelme2coco.py [변환할 이미지 및 JSON 폴더] [coco 데이터셋 변환 폴더명] --labels labels.txt
아래는 LabelMe에서 제공하는 예제입니다.
python labelme2coco.py data_annotated data_dataset_coco --labels labels.txt
'공대생의 팁' 카테고리의 다른 글
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기
지난 포스팅에서 OCR(STR)의 개념과 발전 과정에 대해 설명드린 후, MMOCR의 동작 원리에 대해 설명을 드렸습니다. 이번 포스팅에서는 MMOCR에서 사용하고자 하는 데이터셋을 직접 제작하는 방법에 대해 소개드리도록 하겠습니다.
혹시 OCR의 기본 개념 및 원리에 대해 자세히 알고 싶으신 분은 아래 포스팅을 참조해주세요!
https://elecs.tistory.com/434
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적
elecs.tistory.com
1. OCR 데이터셋의 구조
딥러닝 분야에서 OCR은 이미지 내에서 글자를 찿아내는 Text Detection 과정과 이미지내 글자의 의미를 해석하는 Text Recognition 과정으로 분류됩니다. 쉬운 설명을 위해 사진으로 예시를 보여드리겠습니다.
Text Detection은 이미지를 모델에 입력하였을 때, 이미지에서 글자의 위치를 찾아내는 단계라고 보시면 됩니다 예를 들어 아래와 같은 사진이 모델의 Input으로 들어왔다고 가정합니다.

우리들의 눈으로 보았을 때, 위의 이미지에서 Text 정보로는 전철역 출입구 위에 적혀있는 'CC23', 'one-north'을 확인할 수 있습니다. OCR 모델의 출력은 사람이 글씨를 찾아내는 것과 같이 해당 글자 부분을 Object Detection처럼 표시해줄 것입니다.

MMOCR에서 제공하는 Text Detection 데이터셋 구성은 JSON 파일로 Label이 되어 있으며, 다음과 같이 구성됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_50.jpg",
"height": 720,
"width": 1280,
"instances":
[
{
"polygon":[53.0, 137.0, 97.0, 138.0, 97.0, 153.0, 52.0, 151.0]],
"bbox": [52.0, 137.0, 97.0, 153.0],
"bbox_label": 0,
"ignore": false
},
{
"polygon":[107.0, 138.0, 217.0, 143.0, 216.0, 162.0, 106.0, 157.0]],
"bbox": [106.0, 138.0, 217.0, 162.0],
"bbox_label": 0,
"ignore": false
}
]
}
]
}
|
cs |
Text Recognition은 입력된 이미지에서 Text를 추론하는 과정으로서, Text Recognition 모델의 출력은 해당 이미지의 Text입니다.
Text Recognition 모델에 다음과 같은 이미지가 입력되었을 때,

이미지 내의 Text가 Place임을 바로 알아낼 수 있습니다. Text Recognition 데이터셋 JSON Label은 다음과 같이 나타냅니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "word_25.png",
"instances":
[
{
"text": "Place
}
]
}
]
}
|
cs |
2. 기존에 공개된 OCR 데이터셋 사용하기
위에서 설명드린 양식대로 데이터셋을 직접 만들 수도 있지만, MMOCR을 처음 접하는 경우 데이셋의 구조가 바로 이해가 되지 않을 것입니다. 데이터셋을 당장 만들기 어려우신 분이라면, 기존에 공개된 OCR 데이터셋을 사용해보시는 것을 추천드립니다. MMOCR은 공개된 데이터셋을 MMOCR에서 활용할 수 있는 양식의 데이터셋으로 변환하여 사용할 수 있게 해줍니다. 변환된 데이터셋의 구조를 확인하고 이해하신다면 Custom Dataset을 만드시는데 큰 도움이 될 것입니다. MMOCR에서는 총 16개의 데이터셋의 다운로드를 제공하고 있으며, 데이터셋의 목록은 아래의 주소에서 확인하실 수 있습니다.
https://github.com/open-mmlab/mmocr/tree/main/dataset_zoo
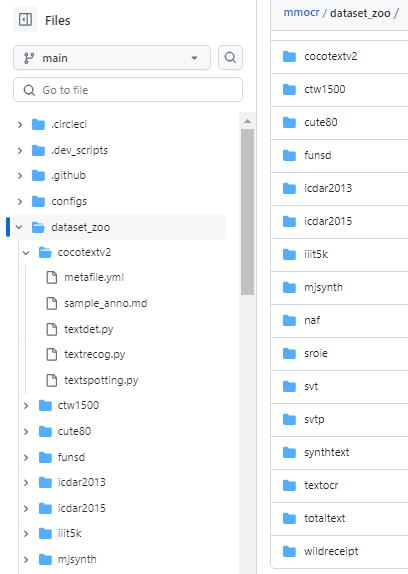
MMOCR에서 제공하는 데이터셋 다운로드 및 변환 기능을 사용해보도록 하겠습니다. 아래의 명령어를 입력하시면 ICDAR 2015 데이터셋을 다운로드한 다음, MMOCR 양식의 데이터셋으로 변환하실 수 있습니다.
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet
위의 명령어를 실행하면, ICDAR 2015 데이터셋을 Text Detection 양식의 데이터셋으로 변환하실 수 있습니다. 만약 Text Recognition 양식의 데이터셋을 원하시는 분께서는 task 옵션에 'textrecog'를 입력하시면 됩니다. 변환된 ICDAR2015 데이터셋을 data 폴더 내에서 확인하실 수 있습니다.
data/icdar2015
├── textdet_imgs
│ ├── test
│ └── train
├── textdet_test.json
└── textdet_train.json3. Tool을 사용하여 Labeling하기(AnyLabeling)
위의 설명을 통해 MMOCR 데이터셋의 구조를 이해하셨다면, 이번에는 우리의 손으로 직접 데이터셋을 만들어보겠습니다. Image 데이터에 Text 레이블링을 할 수 있는 프로그램 중 하나인 AnyLabeling으로 데이터셋을 사용하겠습니다. AnyLabeling은 아래의 github에서 다운로드하실 수 있습니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything, MobileSAM!! - vietanhdev/anylabeling
github.com
AnyLabeling을 설치하신 다음 실행하여 Labeling을 하고자 하는 이미지를 불러옵니다.

위의 사진에서 '71'이라는 텍스트가 가장 먼저 보일 것입니다. 이 부분을 Labeling해보도록 하겠습니다. 좌측에서 사각형 Labeling을 선택하신 후 71을 Bounding Box로 표시해줍니다.
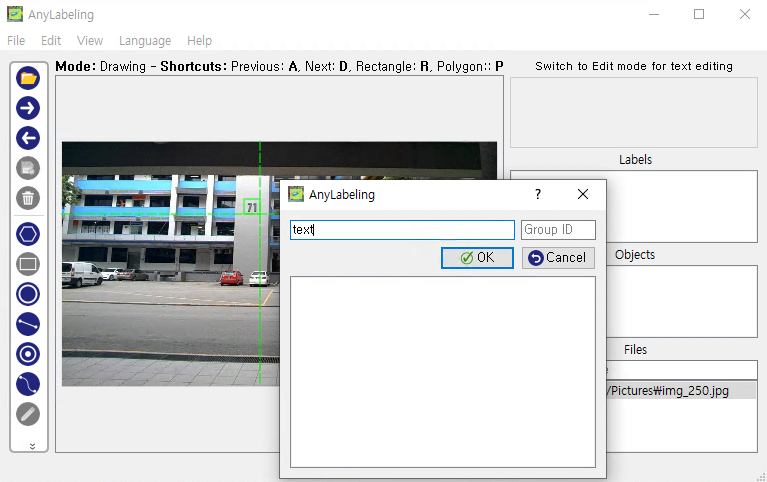
71에 대해 박스 표시가 완료되면, 해당 박스의 Label 정보를 무엇으로 할 지 설정하는 창이 뜰 것입니다. 이 단계에서는 해당 Label의 속성을 설정하는 단계로서, 여기서는 Label의 이름을 'text'로 설정해줍니다. 선택 완료시 labels 목록에 'text'가 추가되었으며, Objects 목록에서도 방금 만든 Box의 객체 정보가 추가된 것을 확인하실 수 있습니다.

다음으로, 방금전에 만든 Object에 Text 정보를 추가해보겠습니다. 좌측 하단에 연필 모양의 아이콘을 클릭하시면 수정모드에 진입하게 됩니다. 그와 동시에 우측 상단에 Text를 입력하는 칸이 활성화 됩니다. 여기서 주의할 것은 해당 칸이 활성화 되자마자 텍스트 정보 입력을 하게 되면, 해당 이미지 자체의 text 정보가 저장이 되버립니다. 방금 만든 '71'에 대한 Label 객체에 대해 text 정보를 추가하기 위해서는, 우측 정보란에 Objects 칸에서 '71'에 해당하는 Object를 목록에서 선택해줍니다.
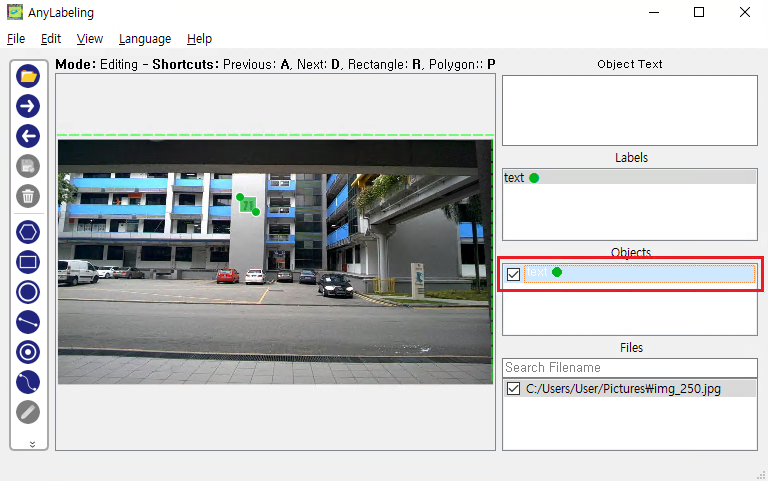
위의 화면에서 빨간색으로 표시한 부분을 클릭하면 '71'에 대한 Label 객체가 선택된 것을 확인하실 수 있으며, Text 정보 입력 칸 윗부분 표시가 'Object Text'로 변경되면서 Text를 입력할 수 있게 되었음을 확인하실 수 있습니다. 여기서 text 정보인 71을 입력해주시면
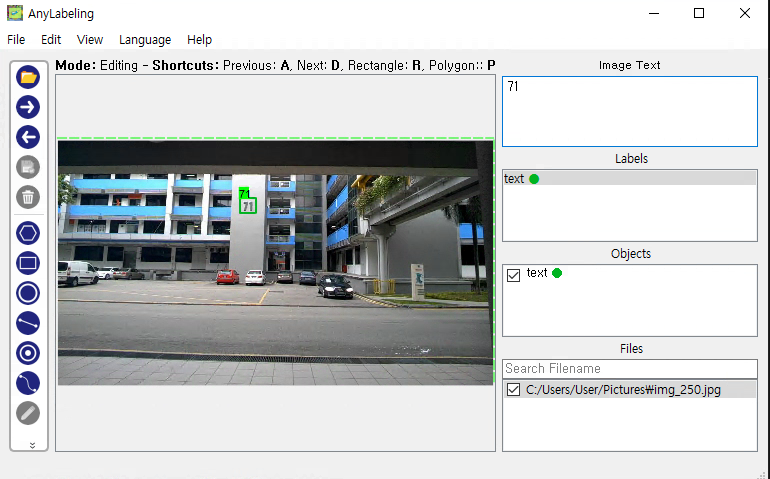
위의 화면과 같이 '71'이라는 text가 해당 Label 객체에 적용된 것을 확인하실 수 있습니다. 위의 과정으로 만든 Label 정보는 아래와 같이 json 양식으로 저장된 것을 확인하실 수 있습니다.

4. OCR 데이터셋으로 변환하기
지금까지 Anylabeling으로 이미지에 Text Labeling을 수행하는 방법에 대해 설명드렸습니다. 위의 과정으로 만든 json 파일을 MMOCR에서 학습할 수 있는 양식으로 변환하는 과정에 대해 설명드리도록 하겠습니다.
먼저, 이미지에서 Text를 찾아내는 과정인 TextDetection 데이터셋으로 변환해보도록 하겠습니다.
Anylabeling2textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import json
import random
import glob
import os
# Anylabeling으로 생성된 Label 데이터
input_path = 'Anylabeling'
# TextDetection 데이터셋으로 변환된 json 파일 저장경로
output_path = 'TextDet'
def extract_instance(shape):
instance = dict()
# 각 Instance별 Bounding Box 좌표값 추출
x1 = int(shape['points'][0][0])
y1 = int(shape['points'][0][1])
x2 = int(shape['points'][1][0])
y2 = int(shape['points'][1][1])
instance['polygon'] = [x1, y1, x2, y1, x2, y2, x1, y2]
instance['bbox'] = [x1, y1, x2, y2]
instance['bbox_label'] = 0
instance['text'] = shape['text']
instance['ignore'] = False
return instance
def create_json(json_list):
metainfo = dict()
# Text Detection 데이터셋
metainfo['dataset_type'] = 'TextDetDataset'
metainfo['task_name'] = 'textdet'
metainfo['category'] = [{'id': 0, 'name': 'text'}]
data_list = []
for file in json_list:
file_path = os.path.join(file)
file_name = os.path.splitext(os.path.basename(file))[0]
# Anylabeling에서 생성된 JSON파일 Load
with open(file_path) as f:
data = json.load(f)
img_info = dict()
# 이미지 파일 경로. 자신의 환경에 맞게 수정.
img_info['img_path'] = os.path.join(input_path, file_name + '.jpg')
img_info['height'] = int(data['imageHeight'])
img_info['width'] = int(data['imageWidth'])
img_info['instances'] = []
shapes = data['shapes']
for shape in shapes:
img_info['instances'].append(extract_instance(shape))
data_list.append(img_info)
json_text = dict()
json_text["metainfo"] = metainfo
json_text['data_list'] = data_list
return json_text
#Input 폴더내 모든 json파일을 불러옴
json_paths = glob.glob(os.path.join(input_path, "*.json"))
#Train-Test셋 데이터 생성(10:1)
random_files = random.sample(json_paths, 11)
remaining_files = [file for file in json_paths if file not in random_files]
trainset = create_json(remaining_files)
testset = create_json(random_files)
with open('textdet_test.json', 'w') as f:
json.dump(testset, f, indent=4)
with open('textdet_train.json', 'w') as f:
json.dump(trainset, f, indent=4)
|
cs |
위 소스코드를 샐행하면 아래와 같이 Text Detection Label 정보가 포함된 json 파일이 생성된 것을 확인하실 수 있습니다.
textdet_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet",
"category": [{"id":0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_250.jpg",
"height": 720,
"width": 1280,
"instances":
[
"ploygon": [536, 169, 583, 169, 583, 213, 536, 213],
"bbox": [536, 169, 583, 213],
"bbox_label": 0,
"text": "71",
"ignore": false
]
}
]
}
|
cs |
다음으로 Text Detection 데이터셋 정보를 설정해줍니다. 아래의 예제는 Text Detection 데이터셋에 대한 설정 파일입니다.
textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
textdet_data_root = 'data/textdet' #Text Detection Label JSON 폴더 위치
textdet_train = dict(
type='OCRDataset',
data_root=textdet_data_root,
ann_file='textdet_train.json',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=None)
textdet_test = dict(
type='OCRDataset'
data_root=textdet_data_root,
ann_file='textdet_test.json',
test_mode=True,
pipeline=None)
|
cs |
Text Detection 모델 중 하나인 TextSnake를 사용하여 위에서 작성한 Data Detection 데이터셋을 적용해보겠습니다.
textsnake.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
_base_ = [
'configs/text/textsnake/_base_textsnake_resnet50_fpn-unet.py',
# Text Detection 데이터셋 추가
'textdet.py',
'configs/textdet/_base_/default_runtime.py',
'configs/textdet/_base_/schedules/schedule_sgd_1200e.py',
]
# dataset settings
train_list = _base_.textdet_train
test_list = _base_.textdet_test
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_list)
val_dataloader = dict(
batch_size=1,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_list)
test_dataloader = val_dataloader
auto_scale_lr = dict(base_batch_size=4)
|
cs |
아래와 같이 한 줄의 명령어를 입력하시면 드디어 Text Detection 데이터셋이 학습되는 것을 확인하실 수 있습니다.
$ python tools/train.py textsnake.py
축하합니다! 여러분들을 드디어 Text Detection 데이터셋을 모델 학습에 적용하실 수 있게 되었습니다. Text Recognition 과정도 거의 비슷하게 진행되니, 잠시 숨을 고른 다음 Text Recognition 데이터셋 학습도 진행해보도록 합시다.
아래의 소스코드를 실행하여 Text Recognition 학습을 위한 json 파일을 생성합니다.
Anylabeling2textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import os
import copy
from PIL import Image
# Anylabeling이 생성한 json 폴더 경로
folder_path = 'Anylabeling'
# Label 저장 경로
save_path = 'output'
# folder_path 내부에 있는 json파일 모두 불러오기
json_files = [file for file in os.listdir(folder_path) if file.endswith('.json')]
# Text Recognition 양식의 JSON 파일 설정
data = {
"metainfo": {
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list": []
}
# Train Set
train = copy.deepcopy(data)
# Test Set
test = copy.deepcopy(data)
# Train-Test Set 분배를 위한 카운터
count = 0
for json_file in json_files:
# .json 확장자 제거
file_name = os.path.splitext(json_file)[0]
with open(os.path.join(folder_path, json_file), 'r', encoding='utf-8') as file:
json_data = json.load(file)
image = Image.open(os.path.join(folder_path, file_name + '.jpg'))
# 이미지에 Label이 있는지 확인
if len(json_data['shapes'] > 0:
shapes = json_data['shapes']
# 이미지 내에 각 Label을 꺼내옴
for i in range(len(shapes)):
# 원본 이미지에서 Text 정보 부분 추출
cropped_image = image.crop((shapes[i]['points'][0][0],shapes[i]['points'][0][1],shapes[i]['points'][1][0],shapes[i]['points'][1][1]))
# 추출된 Text 이미지를 별도의 폴더에 저장
cropped_image.save(os.path.join(save_path, file_name + '_' + str(i) + '.jpg'))
count+=1
# Text 정보를 TextRecognition Dataset 양식으로 저장
new_data = {
"instances": [{"text": shapes[i]['text']}],
"img_path": os.path.join(os.path.join(os.getcwd(), save_path, file_name + '_' + str(i) + '.jpg'))
}
# Train-Test Set 비율을 10:1로 저장
if count % 11 == 0:
test['data_list'].append(new_data)
else:
train['data_list'].append(new_data)
with open("textrecog_train.json", "w") as outfile:
json.dump(train, outfile, indent=4)
with open("textrecog_test.json", "w") as outfile:
json.dump(test, outfile, indent=4)
|
cs |
위 소스코드를 실행하면 Text Recognition Label 양식의 데이터가 적용된 json 파일이 생성된 것을 확인하실 수 있습니다.
textrecog_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"metainfo":
{
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list":
[
{
"img_path": "output/word_1.png",
"instances":
[
{
"text": "71"
}
]
},
]
}
|
cs |
바로 Text Recognition 데이터셋 설정 파일을 만들어줍니다.
textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
textrecog_data_root = 'data/textrecog' #Text Recognition Label JSON 폴더 위치
textrecog_train = dict(
type='OCRDataset',
data_root=textrecog_data_root,
ann_file='textrecog_train.json',
pipeline=None)
textrecog_test = dict(
type='OCRDataset'
data_root=textrecog_data_root,
ann_file='textrecog_test.json',
test_mode=True,
pipeline=None)
|
cs |
거의 다 오셨습니다! SATRN 데이터셋에 방금 만든 Text Recognition 데이터셋을 적용해줍니다.
satrn.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
_base_ = [
'textrecog.py',
'configs/textrecog/_base_/default_runtime.py',
'configs/textrecog/_base_/schedules/schedule_adam_step_5e.py',
'configs/textrecog/satrn/_base_satrn_shallow.py',
]
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=20, val_interval=1)
# dataset settings
train_list = [_base_.textrecog_train]
test_list = [_base_.textrecog_test]
train_dataset = dict(
type='ConcatDataset', datasets=train_list, pipeline=_base_.train_pipeline)
test_dataset = dict(
type='ConcatDataset', datasets=test_list, pipeline=_base_.test_pipeline)
# optimizer
optim_wrapper = dict(type='OptimWrapper', optimizer=dict(type='Adam', lr=3e-4))
train_dataloader = dict(
batch_size=128,
num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
test_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_dataset)
val_dataloader = test_dataloader
#dataset_prefixes는 임의로 설정
val_evaluator = dict(dataset_prefixes=['IC15'])
test_evaluator = val_evaluator
auto_scale_lr = dict(base_batch_size=64 * 8)
|
cs |
아래의 명령어를 통하여 SATRN 모델을 학습합니다.
$ python tools/train.py satrn.py
이제 여러분께서는 MMOCR을 사용하여 Text Detection과 Text Recognition 데이터셋을 만들고 모델을 학습시키는 방법을 터득하였습니다!
'공대생의 팁' 카테고리의 다른 글
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
|---|---|
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
MMCV에서 사용되는 pretrained model 주소 알아내는 방법
mmsegmenataion으로 모델을 학습하는 과정에서 가끔씩 난처한 상황을 맞이하는 경우가 있습니다. 아래와 같이 소스코드 내부를 살펴보았을 때 Pretrained 모델이 경로로 설정되어 있는데 만약 pretrained=None로 설정을 할 경우 모델 학습이 전혀 진행되지 않는 경우가 발생합니다.
|
1
2
3
4
5
|
model = dict(
data_preprocessor=data_preprocessor,
pretrained='pretrain/vit_base_patch16_224.pth',
text_encoder=dict(dataset_name='voc'),
decode_head=dict(num_classes=20))
|
cs |
이 문제를 근본적으로 해결할 수 있는 방법은 해당 Pretrained 모델을 다운로드 받아 사용하는 것인데 mmsegmentation 공식 사이트에서는 해당 내용을 찾기가 어려웠습니다. 혹시나 싶어 구글에 'openmmlab vit_base_patch16_224.pth'와 같이 mmsegmenatation에 국한하지 않고 openmmlab 전체에서 해당 사전학습 모델을 찾을 수 있는지 검색해 보았습니다.
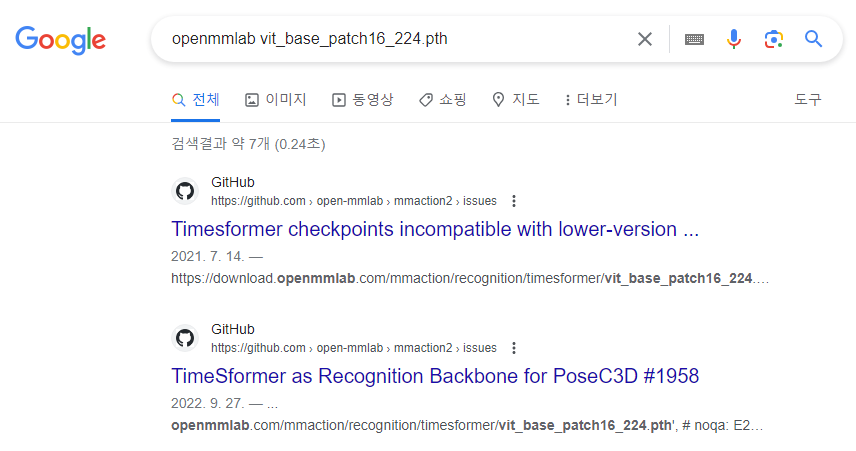
검색 결과 뭔가 힌트가 될 만한 주소가 얼핏 보이는 것이 확인되어 아래와 같이 검색을 시도해보았고...
https://download.openmmlab.com/mmaction/recognition/timesformer/vit_base_patch16_224.pth
다행히도 해당 Weight 모델이 다운로드 되는 것을 확인하였습니다.
'공대생의 팁' 카테고리의 다른 글
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
설정
트랙백
댓글
글
PowerShell에서 Visual Studio x64 환경으로 개발하기
최근 Windows 환경에서 개발을 진행하다보니 자연스레 MSVC 환경에서 동작하는 프로그램을 설계하는 일을 하게 되었습니다. 기존에 Linux 환경에서 개발하던 소스코드를 관리하다보니 Visual Studio에서 보다 Terminal 환경에서 개발을 하다보니 골때리는 경우가 한두가지가 아닙니다..
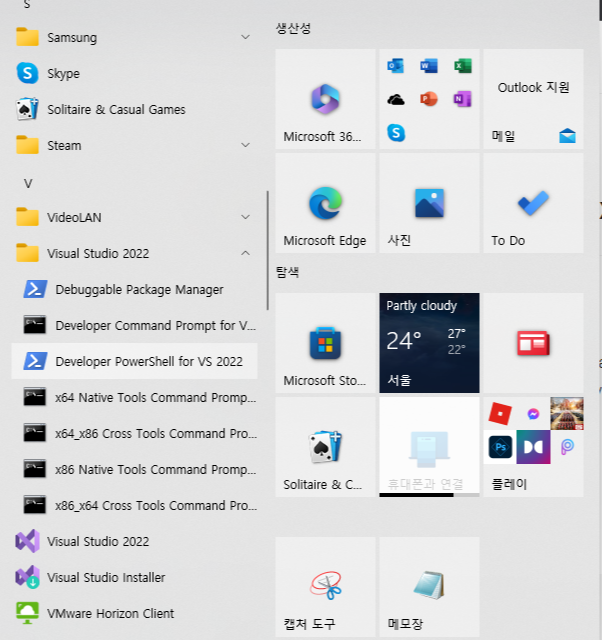
Windows 11에서 부터는 공식적으로 32비트 환경에서의 개발이 중단되면서 64비트 환경의 개발환경이 필요했습니다. 물론 Visual Studio에서는 여전히 32비트 환경 개발을 지원합니다.
문제는 Visual Studio를 설치하였을 때 제공하는 Developer Command 환경이 PowerShell에서는 32비트만 기본으로 실행됩니다. Cmd 환경에서는 32비트와 64비트 모두 제공하는데 말이죠.
물론 Cmd 환경에서 64비트 환경을 개발하는 방법이 있으나 제가 PowerShell이 더 익숙하다보니 Visual Studio에서 기본 제공하는 환경에서는 개발이 어려운 상황입니다.
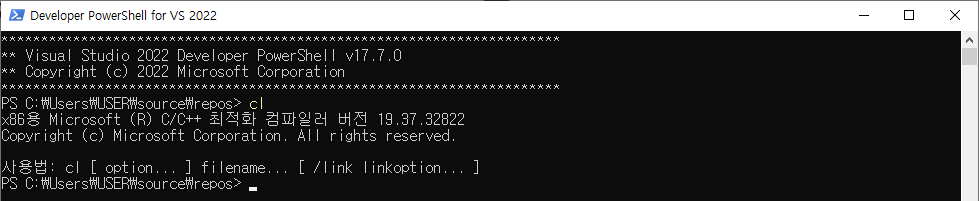
PowerShell에서 64비트 환경을 구현하려면 직접 PowerShell에서 명령어를 구현해야 합니다. 다행히도 Microsoft에서 Command 개발 환경 설정 방법에 대해 설명한 자료가 있었습니다.
명령줄에서 Microsoft C++ 도구 집합 사용
Visual Studio IDE 외부의 명령줄에서 Microsoft C++ 컴파일러 도구 집합(MSVC)을 사용합니다.
learn.microsoft.com
개발자용 명령줄 셸 및 프롬프트 - Visual Studio (Windows)
도구 > 명령줄 메뉴에서 시작합니다. .NET 및 C++ 도구를 더 쉽게 사용하려면 Visual Studio 개발자 명령 프롬프트나 개발자 PowerShell 또는 터미널을 선택합니다.
learn.microsoft.com
자신의 컴퓨터 환경에 맞추어 Visual Studio에서 제공하는 'Launch-VsDevShell.ps1'을 실행하면서 64비트의 환경을 설정해주면 PowerShell에서도 64비트 환경의 프로그램 수행을 하실 수 있습니다.
powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'C:\Program` `Files\Microsoft` `Visual` `Studio\2022\Community\Common7\Tools\Launch-VsDevShell.ps1' -Arch amd64 -HostArch amd64;"
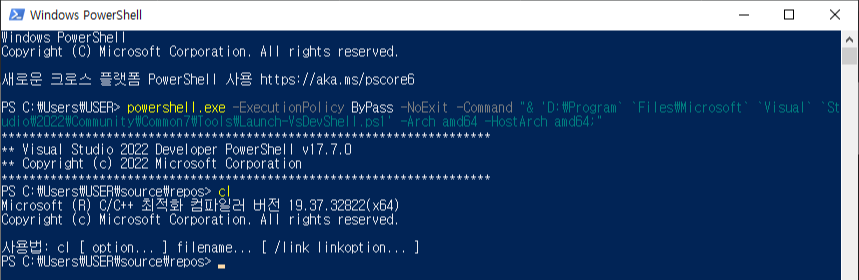
'공대생의 팁' 카테고리의 다른 글
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
|---|---|
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
설정
트랙백
댓글
글
Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법
Visual Studio 에서 제공하는 MSVC를 Powershell에서 실행하기 위해 'Developer Powershell for VS 2022'를 실행하려 하는데 분명 바로가기 설정대로 명령어를 입력했음에도 실행이 되지 않는 문제가 발생하였다.
원인을 확인해보니 Powershell에서 경로명 사이에 스페이스 공백이 있을 때, 별개의 Command로 취급하는 바람에 발생하는 문제였다. 전체 경로명에 작은 따옴표 (')로 감싸줬더니 실행이 잘 되는 것을 확인하였다.
powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& Import-Module 'C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\Tools\Microsoft.VisualStudio.DevShell.dll'; Enter-VsDevShell cecdefe2;"
'공대생의 팁' 카테고리의 다른 글
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
|---|---|
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
설정
트랙백
댓글
글
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적용되면서 생성형 인공지능의 성능은 더 빠르게 발전하는 양상을 보이는 가운데 지식 업무를 수행하는 화이트칼라 사무직들 조차 AI시대에 일자리를 뺏길 위기를 걱정을 하게 되는 세상이 도래하려나 싶은 생각이 드는 요즈음입니다.
다행히도(?) 사람처럼 현실세계에서 길거리의 간판을 쉽게 읽고 이해하는 로봇은 보이지 않는 듯 합니다. 분명 인공지능은 오직 사람만이 구현하리라 믿었던 상상력을 발휘하는 듯 함에도 현실 세계에서 이러한 기능을 실제 로봇에 구현하기에는 시간이 더 필요할 것으로 보입니다.

이번 포스팅에서는 인공지능이 현실세계에서 접할 수 있는 글씨들을 감지하고 이를 해석하는 장면 글자 인식(Scene Text Recognition, 혹은 광학 글자 인식 - Optical Text recognition)에 대해 이해하고 지금까지 공개된 글자 인식 알고리즘들을 총망라한 MMOCR에 대해 소개드리도록 하겠습니다.
사람의 도움 없이 스스로 글자를 읽는 기계?
OCR(Optical Character Recognition) 기술은 이름 그대로 광학 문자 인식 기술을 의미하며, 마치 사람이 글자를 이해하듯이 컴퓨터가 글씨를 사람처럼 읽을 수 있는 기술을 일컫는 말입니다.
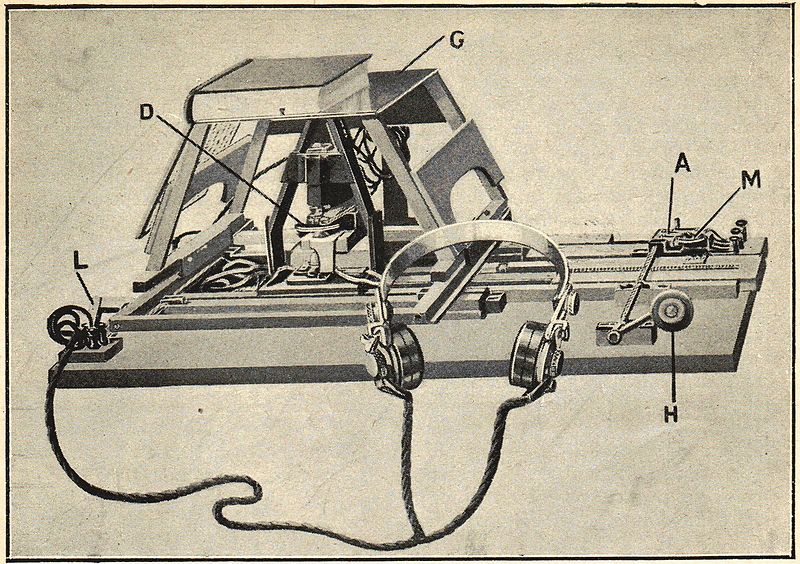
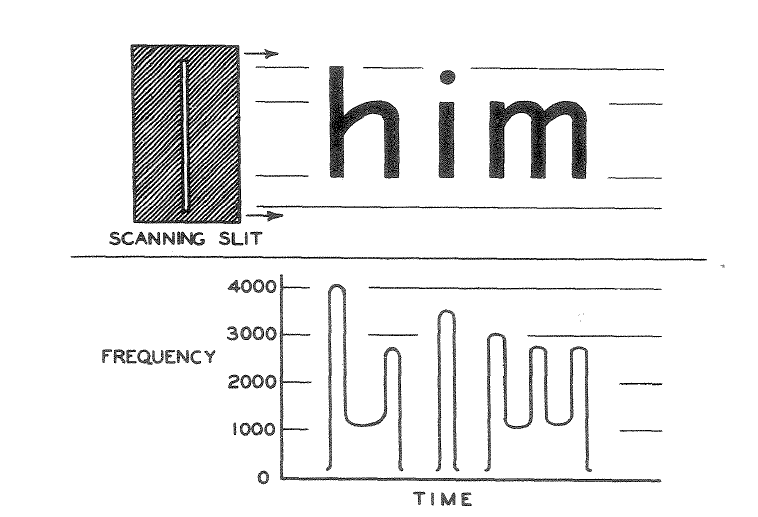
딥러닝 기반 인공지능 기술이 활발하게 사용되고 있는 오늘날 관점에서 보면 놀랍게도 OCR 기술은 생각보다 오래전부터 연구된 분야입니다. 초창기의 OCR 기술은 글을 볼 수 없는 시각장애인들을 위해 종이에 적혀있는 글씨를 인식하는 기기에서 에서 시작되었습니다. 1913년, 아일랜드의 물리학자이자 화학자였던 에드먼드 에드워드 푸르니에 달베(Edmund Edward Fournier d'Albe, 1868년 – 1933년 6월 29일)가 발명한 옵토폰(Optophone)의해 OCR 기술이 처음으로 세상에 등장하였습니다.

옵토폰은 이름 그대로 빛을 소리로 바꾸어주는 기기로서 광학 센서에 의해 글자의 세로 두께에 해당되는 주파수를 내면 이를 사람이 듣고 어떤 글자인지 알 수 있는 방법으로 발명되었습니다.
이후에도 인쇄물의 글자를 인식하는 기능들이 지속적으로 발전해왔으며, 오늘날 주로 사용되는 광학 문자 인식기는 로버트 노이스(Robert Norton Noyce, 1927년 12월 12일 - 1990년 6월 3일)가 1977년 발명한 OCR 리더기로서 그 모습을 갖추었습니다. 종이에 적힌 글자를 OCR 리더기로 스캔하면 컴퓨터에 해석된 글자를 전송하는 방식으로 동작하며, 손쉽게 책의 내용을 컴퓨터가 읽을 수 있는 시스템을 갖출 수 있게 되었습니다.

2023년 기준 최근에는 OCR Reader에 인공지능 번역 기능까지 갖춘 상품이 등장하였습니다. 책의 사진을 찍으면 인공지능 번역기로 번역을 해주던 기능은 기존에도 존재했지만 책을 촬영할때 빛과 손떨림 등으로 인해 초점이 맞지 않아 글자가 제대로 보이지 않는 문제점이 있지요. 이러한 단점을 OCR Reader를 사용하여 정확도를 높였고, OCR리더기를 사용하여 글자를 직접 스캔한 다음 이를 번역기에 넣어 돌린다는 아이디어는 상당히 참신해 보입니다.
MMOCR

MMOCR은 OpenMMLab에서 제작한 MM시리즈 중 하나로 공개된 OCR 알고리즘들을 통합한 프로젝트입니다. mmcv, mmdet 라이브러리와 mmocr 소스코드에 맞추어진 모델을 다운로드하여 명령어 단 한줄만으로 손쉽게 ocr을 경험해보실 수 있습니다.
MMOCR은 OCR 모델의 주요한 알고리즘인 Text Detection, Text Recognition을 제공합니다. Text Detection 과정을 통해 이미지에서 글자가 위치한 부분을 Segmentation 방식으로 표시하고, Recognition 단계에서는 Detection 과정에서 찾아낸 글자를 인식하는 과정을 거칩니다.

MMOCR에서 제공하는 예제를 실행하여 OCR의 원리를 빠르게 이해해봅니다. Github에서 MMOCR 소스코드를 다운로드합니다.
$ git clone https://github.com/open-mmlab/mmocr
MMOCR 소스코드를 다운로드한 다음 아래의 명령어를 입력하면 MMOCR에서 기본 설정한 OCR 모델이 자동으로 다운로드 되며 바로 실행되는 것을 확인하실 수 있습니다.
$ python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result
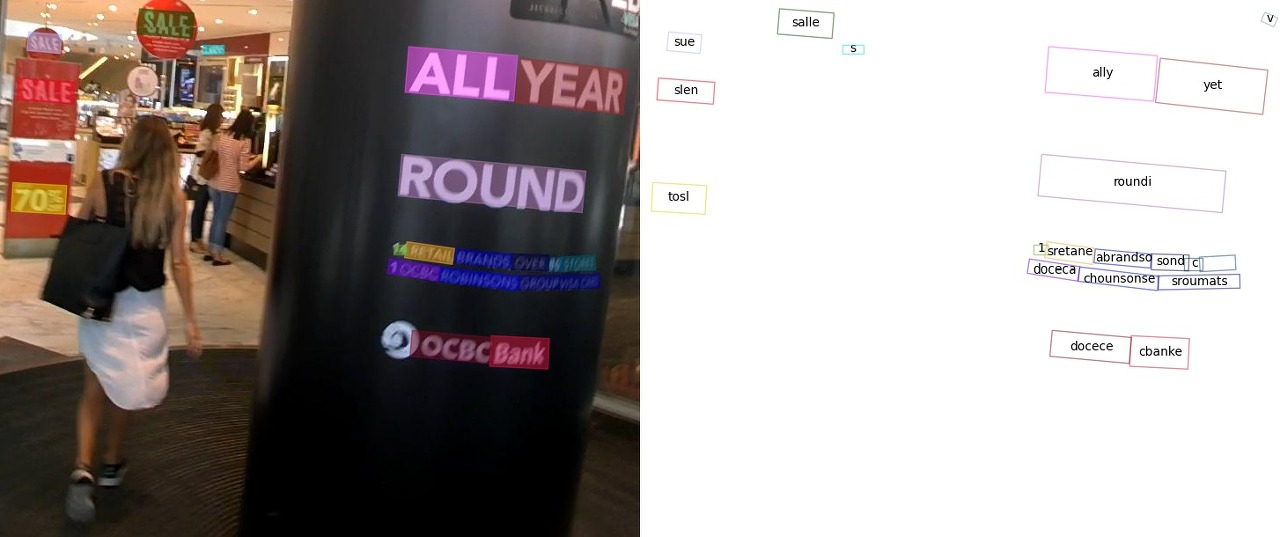
왼쪽의 사진은 이미지에서 글자의 위치를 찾아 표시하는 Text Detection, 오른쪽의 사진은 Text Detection 과정에서 찾은 Text의 글자를 해석하는 Text Recognition 과정을 나타내고 있습니다. 아래는 Text Recognition 결과를 Text로 출력되는 것을 보실 수 있습니다.
# Inference result
{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year',
'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores':
[...]}]}
'공대생의 팁' 카테고리의 다른 글
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
|---|---|
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
설정
트랙백
댓글
글
AI로 Labeling을 자동으로 더 편하게 - AnyLabeling
지난달 메타(페이스북)에서 학습되지 않은 물체(Unlabeled object)도 감지하여 이를 디테일하게 나타내는 Segment Anything 모델(SAM)이 공개된지 불과 1개월이 지난 현재 무려 피인용수가 50을 돌파할 정도로 Semantic Segmentation 분야에서 상당한 주목을 받고 있습니다. 실제 성능을 보았을 때 이미지 내의 Object들을 상당히 디테일하게 찾아주는 점이 상당히 놀라웠습니다. Vision 분야를 연구하는 저에게 있어 SAM 알고리즘은 ChatGPT에 버금갈 정도로 놀라운 성능을 보였습니다.
이러한 SAM 모델을 사용하여 Labeling 작업을 대신 할 수 있으면 편하겠다고 생각을 해보았었는데 이러한 상상을 벌써 하신 분이 계시다니! 어떤 똑똑한 개발자 분께서 SAM 알고리즘을 사용하여 자동으로 Labeling 작업을 수행할 수 있게 해주는 훌륭한 Tool인 AnyLabeling을 무려 오픈소스로 공개하였습니다.
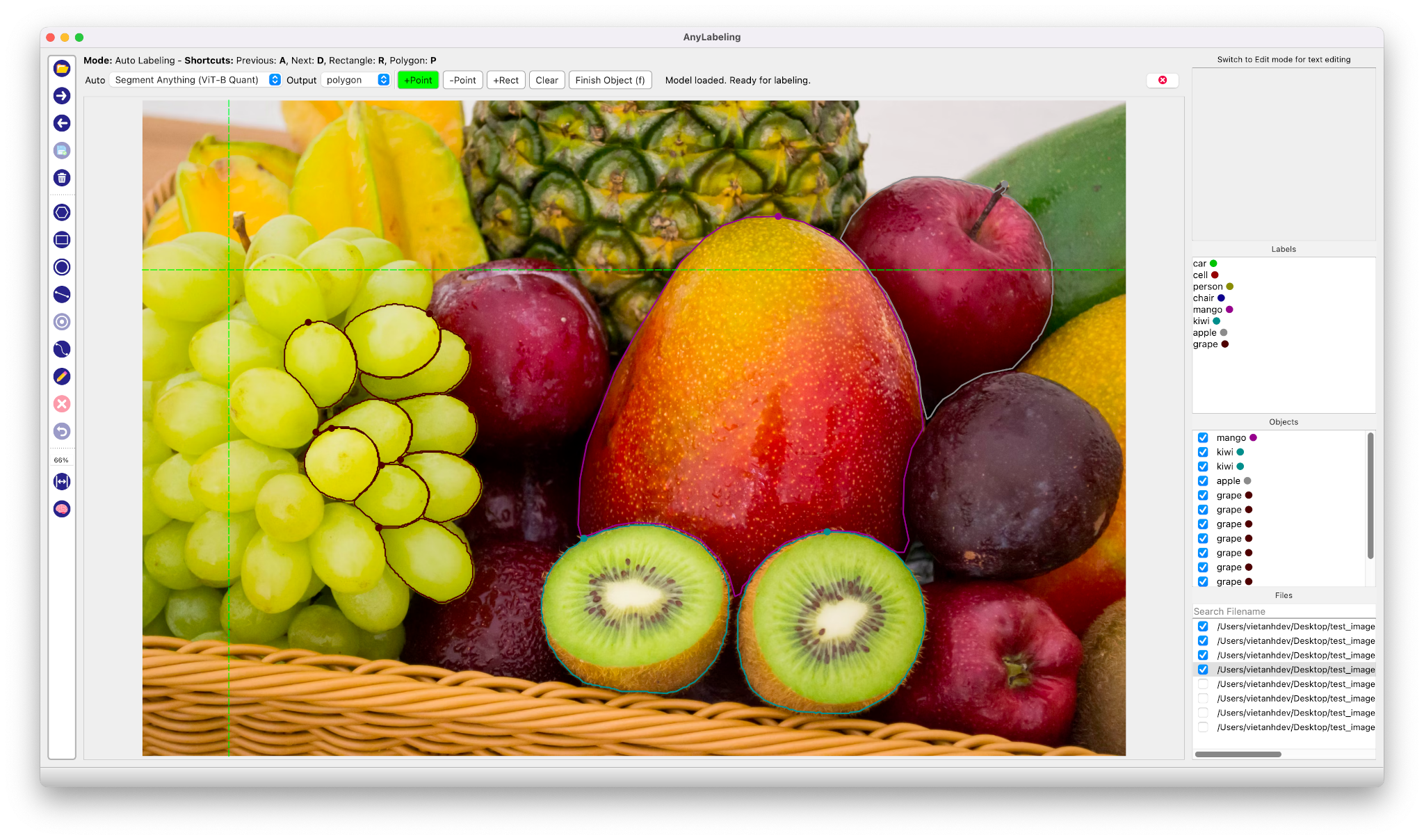
인터페이스는 전반적으로 기존의 Labeling 오픈소스인 Labelimg과 Labelme와 같은 구성으로 기존에 해당 Tool을 사용해보셨던 분들이라면 금새 익숙하게 AnyLabeling을 사용할 수 있도록 설계되었습니다. 즉, 기존의 Labeling 방식대로 Bounding box나 Polygon 방식으로 Labeling을 할 수 있습니다.
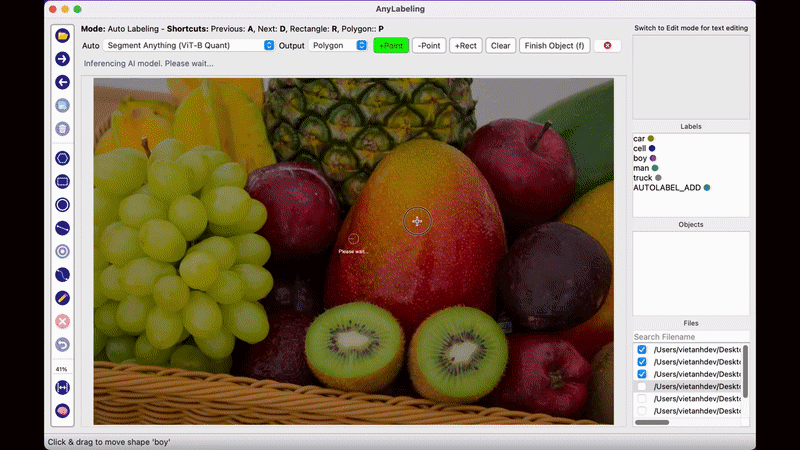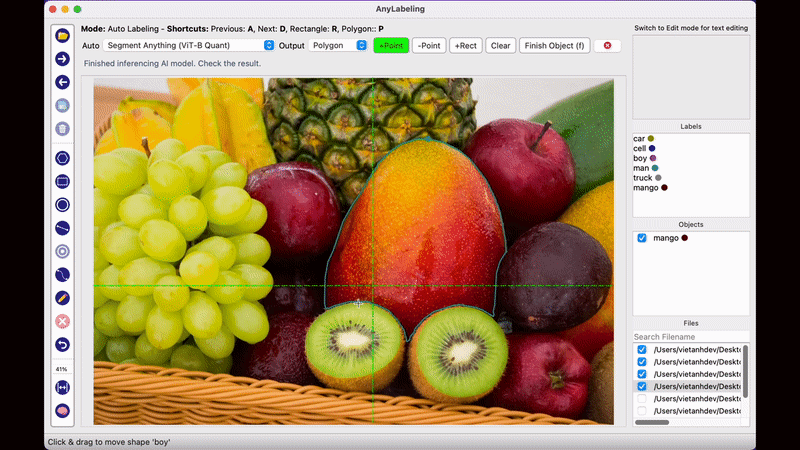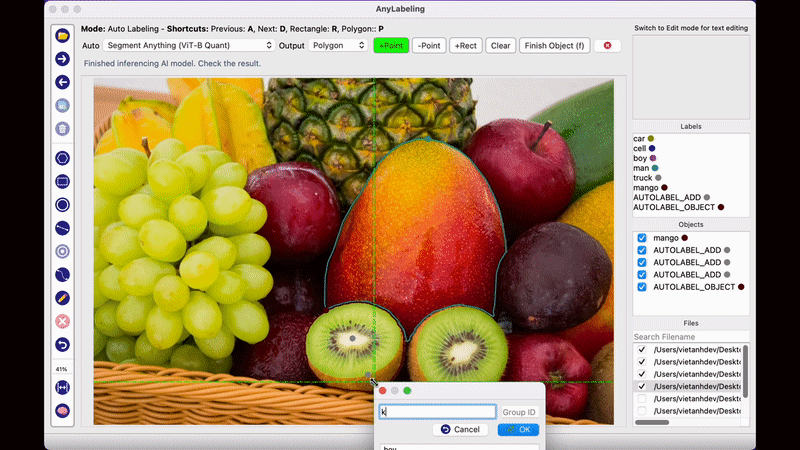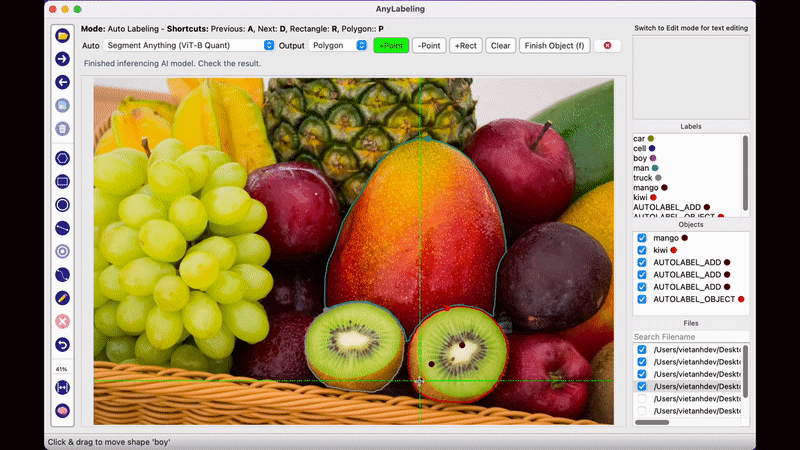
AnyLabeling의 가장 두드러지는 장점이라면 메타AI에서 공개한 Segment Anything 모델을 사용하여 단지 이미지를 클릭하는 것만으로도 물체를 자동으로 Segmentation Labeling 작업을 해준다는 점입니다. 생각보다 Labeling의 품질도 만족스러워 이전처럼 Labeling을 하기 위해 점을 한땀 한땀 클릭하는 작업을 많이 줄일 수 있을 것으로 보입니다.
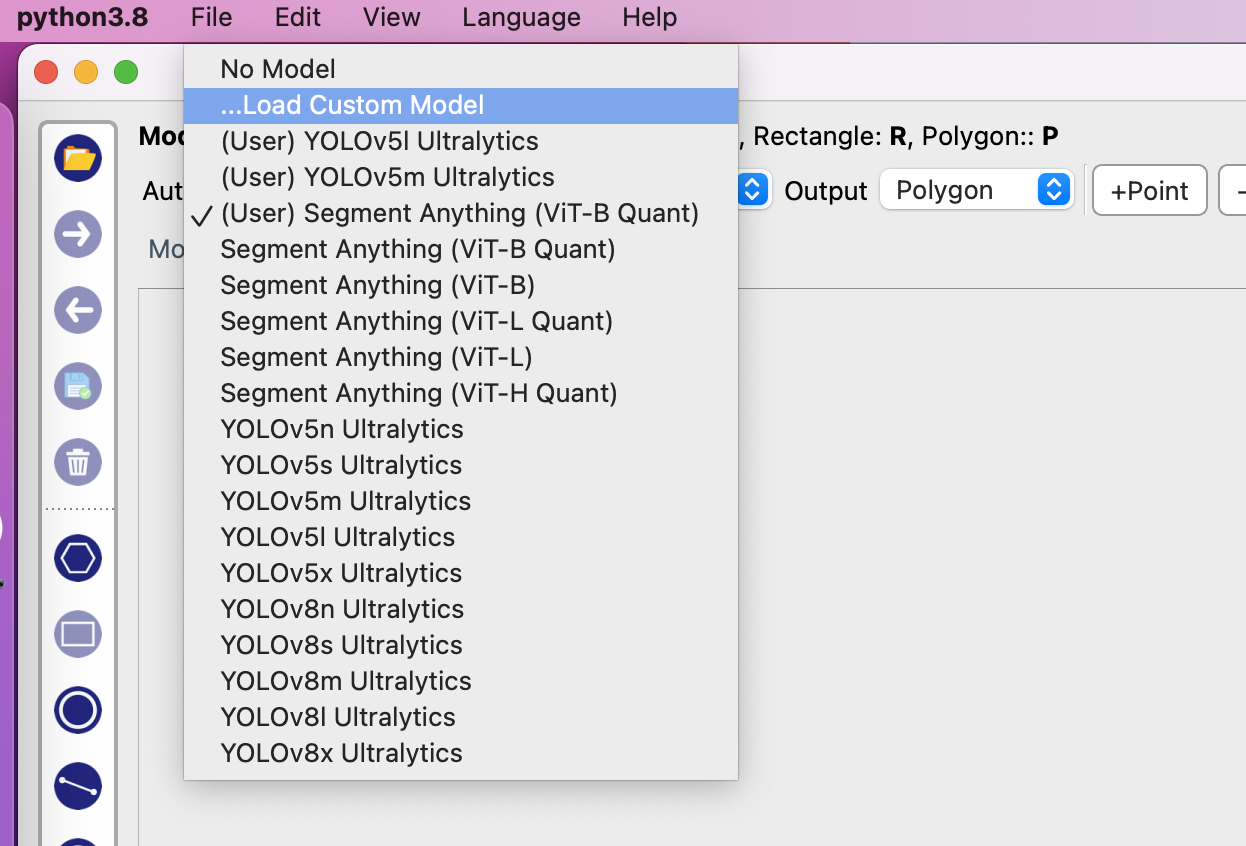
2023년 5월 시점에서 AnyLabeling은 SAM과 YOLOv5, YOLOv8 알고리즘을 제공하고 있으며, 자신이 원하는 모델을 추가하여 자동 Labeling 작업을 수행할 수 있습니다.
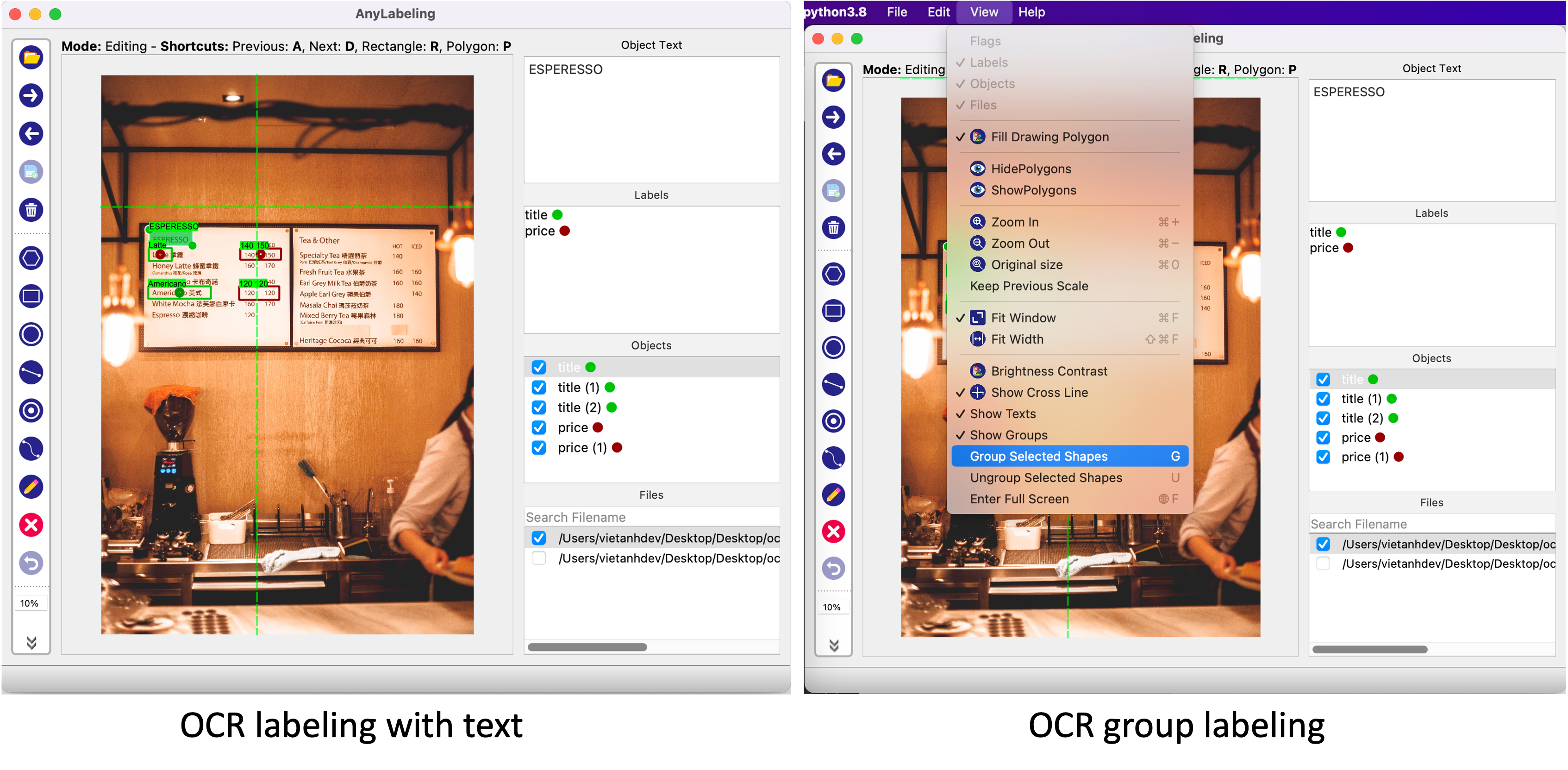
Anylabeling의 또다른 특징 중 하나는 Label에 텍스트 데이터를 남길 수 있다는 점입니다. 단순히 해당 객체의 특징을 설명하기 위한 목적으로도 사용할 수 있지만, 글자 판독 기술인 OCR 데이터를 구축하기 위해 사용하는 방법으로 사용할 수 있습니다. 지금까지 공개된 오픈소스 Labeling Tool 중에서 OCR을 위한 텍스트 데이터를 기록하 수 있는 Tool은 Anylabeling이 그나마 사용하기 편한 것 같습니다.
AnyLabeling은 모든 종류의 운영체제(Windows, Linux, MacOS)에서 사용하실 수 있습니다. AnyLabeling Github 사이트에서 아래의 주소를 통해 자신의 운영체제에 맞는 최신 버전을 설치하여 사용하시기 바랍니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from Segment Anything and YOLO! - vietanhdev/anylabeling
github.com
AnyLabeling에 대해 좀 더 자세한 내용을 알고 싶으신 분은 아래의 공식 페이지를 참조해주시기 바랍니다.
AnyLabeling - Smart Image Labeling Tool – AnyLabeling
Effortless data labeling With AI support from Segment Anything and YOLO models. Get started →
anylabeling.com
'공대생의 팁' 카테고리의 다른 글
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
|---|---|
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
설정
트랙백
댓글
글
Lableme로 Coco Dataset과 VOC Dataset 만들기
고성능의 인공지능을 만들기 위한 가장 중요한 작업 중 하나는 최대한 많은 양질의 데이터를 확보하는 것입니다. 상상을 뛰어넘는 인공지능의 놀라운 발전을 보았을 때 마치 AI를 연구하는 사람들이 고상한 기술을 사용하여 인공지능을 만드는 것처럼 보이지만 안타깝게도 학습 데이터가 확보되지 않은 인공지능은 고성능을 발휘하기 어렵습니다.
그렇다고 해서 데이터만 잔뜩 확보했다고 하여 고성능의 인공지능 기술이 뚝딱 하고 만들어지는 것은 결코 아닙니다. 확보된 데이터를 인공지능이 학습할 수 있도록 전처리 하는 과정이 필요한데 주어진 사진에서 학습하고자 하는 물체의 이름과 위치 등을 표시하여 인공지능이 이를 학습할 수 있도록 만들어주어야 합니다. 흔히 이 전처리 과정을 '레이블링(Labeling)이라고 합니다.
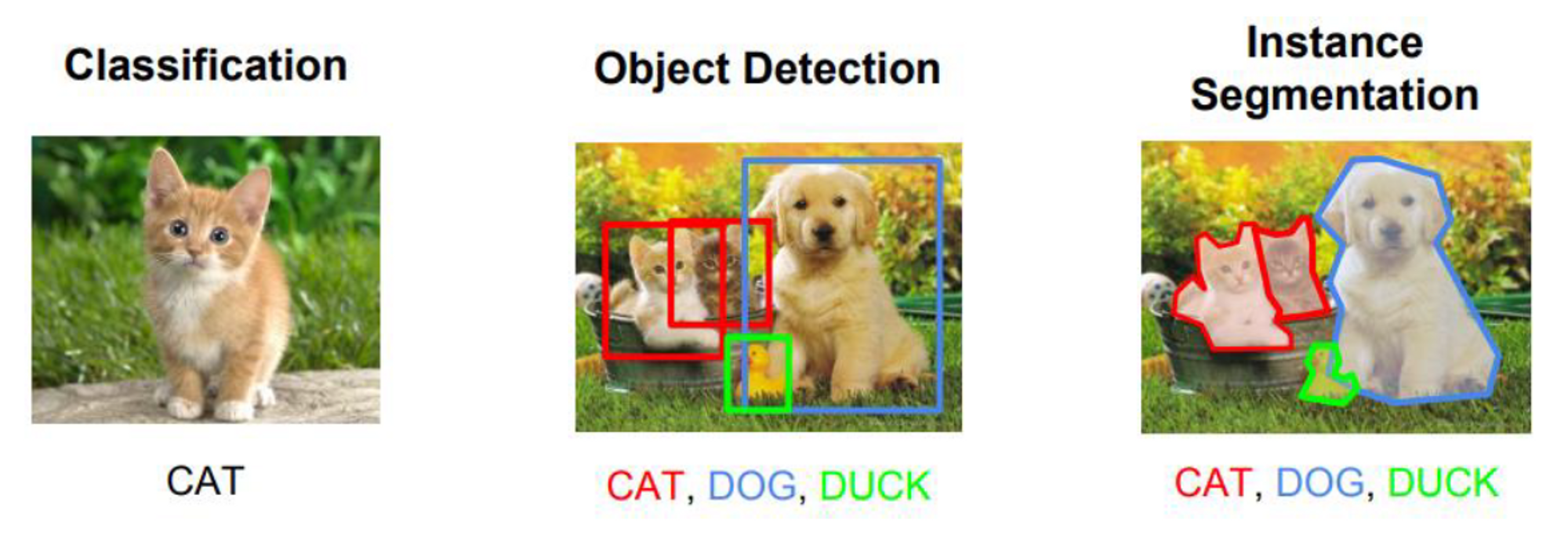
산업 분야에서 인공지능의 활용 영역이 확대됨에 따라 수집된 데이터의 전처리를 전문으로 하는 기술에 대한 수요가 늘어났고, 이를 처리할 수 있는 성능 좋은 Labeling 기술들이 소개되고 있습니다. 단지 사진을 선택했을 뿐인데 사진 속 특성(Feature)을 추출하고 이에 맞는 Labeling 작업까지 자동으로 해주는 기술이 등장할 만큼 지금 이 순간에도 좋은 도구들이 소개되고 있습니다.
하지만, 인공지능을 시범 도입하기 위해 고가의 Labeling tool을 구매하여 사용하는 것은 상당히 부담스러울 수 밖에 없습니다. 다행히도, 자신의 Field에 인공지능 적용 실용성 여부를 검토할 수 있는 데이터셋 전처리를 가능하게 해주는 무료 도구들이 오픈소스로 공개되어있습니다. 이번 포스팅에서는 지금 이 순간에도 무료로 공개되어 있으며, 누구나 쉽게 어떤 환경에서도 사용할 수 있는 LabelMe를 소개드리도록 하겠습니다.

LabelMe는 pip로 설치하여 바로 사용하실 수 있습니다.
$ pip install labelme pyqt5 pyside2
혹은 아래의 사이트를 통해 소스코드를 직접 설치하실 수 있습니다.
https://github.com/wkentaro/labelme
GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation). - GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, recta...
github.com
labelme를 실행하면 상당히 직관적인 UI툴을 갖추고 있는 것을 보실 수 있습니다.
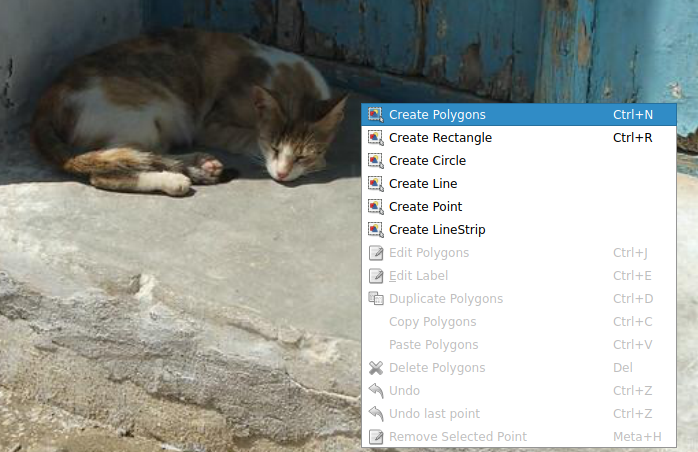
레이블링을 수행하고자 하는 이미지를 불러온 다음 마우스 오른쪽 버튼을 클릭하여 'Create Polygons'를 클릭하여 이미지의 객체 주변에 점을 찍어가며 객체를 표시해줍니다.
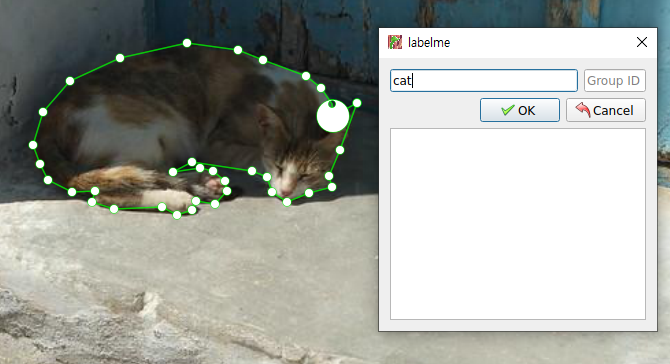
주변에 점을 찍다 한 바퀴 정도 돌게되여 처음 찍은 점으로 돌아오게 되었을 때 1개의 폴리곤이 완성되며 이 때 표시한 객체의 속성을 입력해줍니다.

Labeling이 완료되면 위와 같이 작업이 완료된 모습을 확인하실 수 있습니다. 혹시 표시하고자 하는 객체를 네모 모양으로 하고싶으신 분은 'Create Rectangle'을 선택하여 표시할 수 도 있습니다.
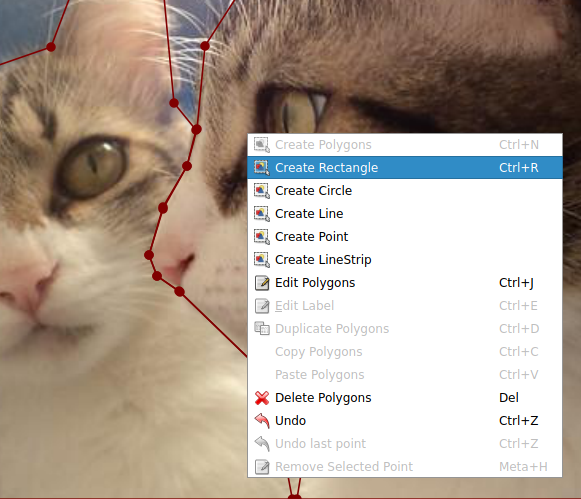
Object Detection을 수행하는 방법과 같이 Rectangle로 객체를 감싼 다음 Label을 붙여주면 됩니다.
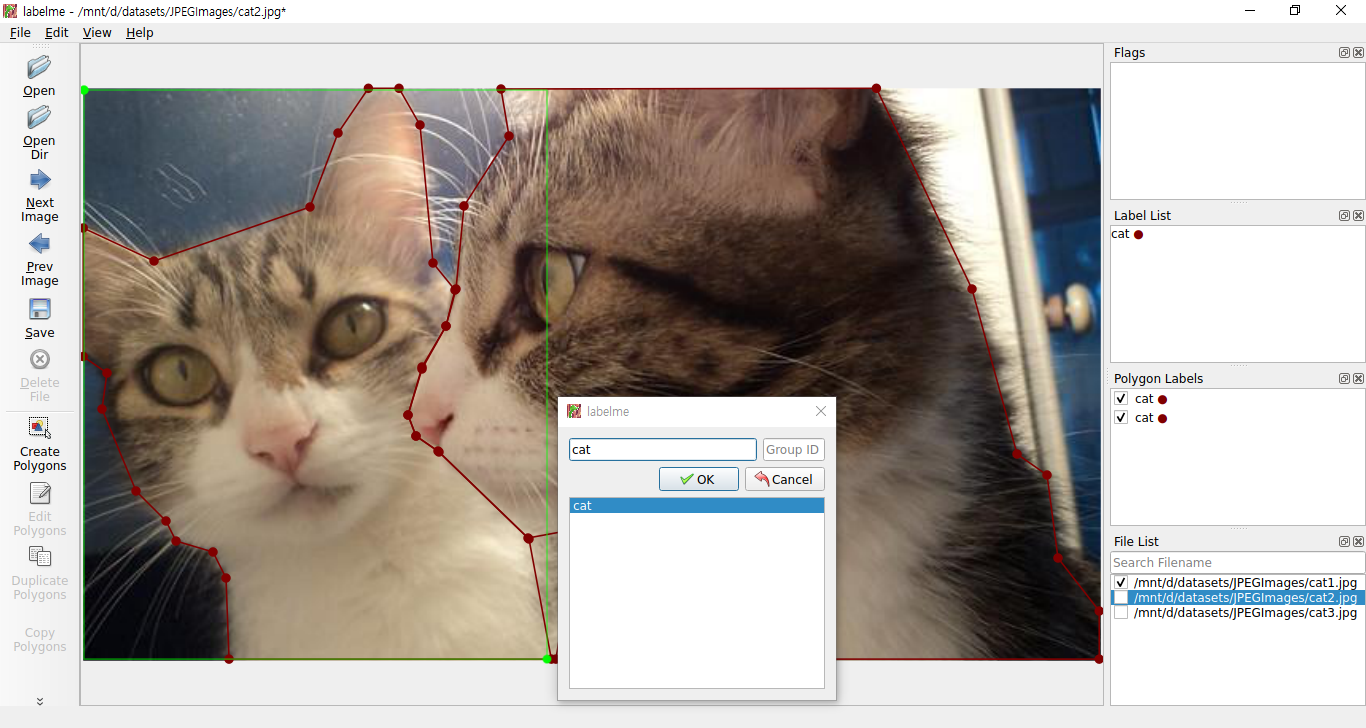
지금까지 진행한 작업들을 확인해봅니다. LabelMe로 작업하였던 내용들이 이미지 폴더에 함께 들어있는 것을 확인하실 수 있습니다.
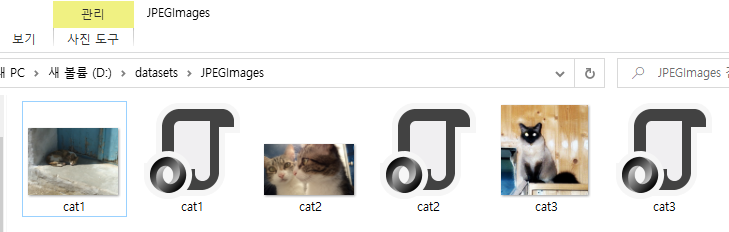
Pascal VOC 방식의 Dataset 만들기
지금부터 LabelMe로 만든 Label 정보들을 인공지능이 학습할 수 있도록 전처리과정을 통해 Dataset을 만드는 과정을 설명드리도록 하겠습니다. 데이터를 학습할 때 보통 COCO 와 Pascal VOC 방식의 Dataset이 주로 사용되고 있습니다. LabelMe 저자는 LabelMe로 Label을 적용한 정보를 COCO 혹은 Pascal VOC로 변환해주는 소스코드를 제공하고 있습니다. 아래 링크를 통해 다운로드 받으실 수 있습니다.
https://github.com/wkentaro/labelme/tree/main/examples/instance_segmentation
1. Pascal VOC로 변환(labelme2voc.py)
먼저 자신이 Label한 클래스의 명단을 labels.txt 파일로 아래와 같이 작성해주세요. 저의 경우 객체가 고양이 단 하나 뿐이므로 class는 cat 하나입니다.
|
1
2
3
|
__ignore__
_background_
cat
|
cs |
다음으로 lableme2voc.py를 실행하여 이미지와 Label정보가 담긴 폴더의 내용으로 VOC 데이터셋을 생성합니다.
$ python labelme2voc.py '이미지와Label정보가 담긴 폴더명' 'VOC데이터셋 폴더명' --labels labels.txt
해당 명령어를 수행하면 아래와 같이 폴더들이 생성되는 것을 확인하실 수 있습니다.
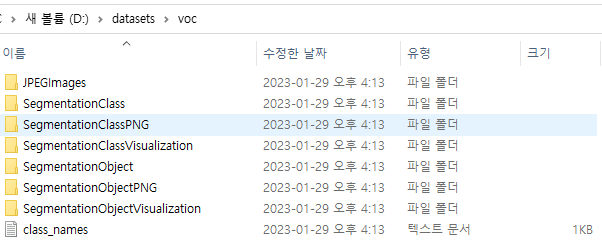
SegmentationObjectVisualization 폴더의 내용을 보시면 아래와 같이 Label이 잘 되어있는 것을 확인하실 수 있습니다.



2. COCO로 변환(labelme2coco.py)
다음으로 Coco Dataset으로 변환하는 방법을 살펴보겠습니다. 위에서 VOC Dataset을 만들때 사용하였던 label.txt에 자신이 만든 Label의 클래스를 적어주신 다음 labelme2coco.py를 사용하여 다음과 같이 실행해줍니다.
$ python labelme2voc.py '이미지와Label정보가 담긴 폴더명' 'VOC데이터셋 폴더명' --labels labels.txt
위 명령어를 실행하면 COCO 양식의 데이터셋이 생성된 것을 확인하실 수 있습니다.

Visualization 폴더 내용을 보면 Label이 적용된 것을 확인하실 수 있습니다.



'공대생의 팁' 카테고리의 다른 글
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
|---|---|
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
설정
트랙백
댓글
글
영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV
2022년 이미지 창작 알고리즘인 Dalle-2의 등장은 학계를 너머 일반인들에게도 상당히 뜨거운 기술이었습니다. 단지 비슷한 사진을 생성하는 GAN의 한계를 뛰어넘어 오직 인간의 창의력으로만 가능할 것만 같았던 창작의 영역까지 인공지능이 정복했다는 것은 인공지능의 기술이 어디까지 발전하였는지 심지어 사람의 한계를 뛰어넘었는지 확인할 수 있던 순간이었습니다. 반면, 오직 인간만의 영역이라 생각했던 미술 분야 마저 인공지능이 정복하지는 않을까 우려하는 분위기도 보입니다.
이토록 AI의 발전속도는 다른 분야와는 비교할 수 없을 정도로 빠르게 변화하고 있는데다 불과 몇 달 만에 더 좋은 성능의 알고리즘이 등장하는 것은 AI학계에서는 일상이 되었습니다. 그러다보니 종종 좋은 아이디어를 가진 알고리즘도 등장하였지만, 빠른 변화 속에 묻혀버린 경우도 없지 않아 있습니다.
이번에 소개드리고자 하는 MMCV는 흔히 MMDetection라는 이름의 알고리즘으로 사람들에게 알려져있으며 지금까지 선보인 Vision 인공지능 알고리즘들을 모아서 단 하나의 프로젝트로 여러 종류의 모델을 사용할 수 있게 해줍니다.
사실 이렇게 여러 종류의 알고리즘들을 종합하여 활용할 수 있게 하는 프로젝트는 메타(페이스북) AI연구소에서 만든 Detectron의 사례가 있습니다. Detectron 또한 MMCV처럼 모든 종류의 알고리즘을 하나의 프로젝트로 사용할 수 있다는 장점이 있으나 Detectron이 Linux 기반에서 만들어져 Windows에서 사용하기 위해서는 일부 코드를 손봐야 하는 불편함이 있었습니다. 하지만 MMCV는 Windows는 물론 Linux, MacOS 등 어떠한 환경을 가리지 않고 사용할 수 있도록 만든 점이 MMCV의 큰 장점이라 할 수 있습니다.

MMCV는홍콩중문대학(The Chinese University of Hong Kong) 멀티미디어 연구실(MMLab)에서 박사과정이었던 카이첸의 주도로 개발되었으며, 2018년 MMDetection과 함께 공개되었습니다. 현재 그는 홍콩중문대학을 졸업하여 상하이 AI Laboratory에서 일하고 있으며, 그가 만든 MMCV 프로젝트는 OpenMMLab의 맴버로서 지금까지 전세계의 인공지능 개발자들이 사용하고 있습니다.
Kai Chen
Kai Chen is currently a Research Scientist & PI at Shanghai AI Laboratory. He is leading the OpenMMLab team, which targets at developing state-of-the-art computer vision algorithms for research and industrial applications, as well as building influential o
chenkai.site
MMCV 설치
MMCV를 설치하기에 앞서 자신의 개발 환경에서 Pytorch를 설치한 다음 MMCV를 설치합니다. 자신의 환경에 적합한 MMCV 환경을 구축해주는 Openmim을 설치합니다.
$ pip install openmim
자신이 설치하고자 하는 MMCV의 버전이 1.x일 경우 mmcv-full을 설치합니다.
$ mim install mmcv-full
만약 자신이 설치하고자 하는 MMCV의 버전이 2.x 이상일 경우 mmcv를 설치해주세요.
$ mim install mmcv
Python을 실행하여 mmcv가 잘 설치되었는지 확인합니다.
import mmcv
print(mmcv.__version__)
축하합니다! 지금부터 여러분은 MMCV를 사용할 수 있게 되었습니다.
Config
MMCV을 원하는 목적에 맞게 사용하기 위해서는 MMCV 라이브러리에서 제공하는 Config의 구조를 이해하는 것이 매우 중요합니다.
MMCV의 Config는 자신이 설계하고자 하는 모델을 직접 설정할 수 있게 해주는 설계도라 할 수 있습니다. MMCV의 라이브러리에서 직접 설정한 기존 모델들은 모두 Config파일로 제공되며 자신이 원하는 모델의 Config 파일을 원본대로 학습할 수도 있고, 자신이 원하는 성능이 구현될 수 있도록 Fine tuning하여 사용할 수도 있습니다.
Config의 기초 원리를 자세하게 정리되어 있는 포스팅이 있어 아래의 링크를 통해 학습하실 수 있습니다.
https://better-tomorrow.tistory.com/entry/MMCV-%EC%9D%98-Config
MMCV 의 Config
# G.py _base_ = ['./base.py'] item = dict(a = {{ _base_.item1 }}, b = {{ _base_.item2.item3 }}) https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html Config — mmcv 1.3.16 documentation Config Config class is used for manipulating config and c
better-tomorrow.tistory.com
MMDetection에 설정된 모델들은 config 폴더에 있으며 자신이 원하는 모델의 config를 찾아서 사용하면 됩니다. 아래의 코드는 Mask R-CNN의 config 파일 중 하나입니다.
mmdetection/configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py
|
1
2
3
4
5
|
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/coco_instance.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
|
cs |
config 파일의 소스코드를 확인해보면 _base_를 통해 config 설정들을 상속하고 있는 것을 확인하실 수 있습니다. 각 소스코드를 간단히 설명드리자면
../_base_/models/mask_rcnn_r50_fpn.py
학습하고자 하는 모델의 구조를 나타냅니다.
../_base_/datasets/coco_instance.py
학습하고자 하는 데이터셋을 설정합니다.
../_base_/schedules/schedule_1x.py
optimizer, epoch 등의 학습 정책을 설정합니다.
../_base_/default_runtime.py
학습 방식(Single, Multiple)등을 설정합니다.
지금까지 MMCV에 대해 기본적인 내용들을 설명드렸습니다. MMlab에서 공개중인 MMDetection과 MMSegmentation등의 라이브러리를 사용하여 다양한 인공지능 모델들을 체험해보시길 바랍니다!
'공대생의 팁' 카테고리의 다른 글
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
|---|---|
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
설정
트랙백
댓글
글
웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법
멜론, 유튜브뮤직 등 요즘은 음원 스트리밍 서비스들이 워낙 많아 인터넷 초창기 시절처럼 불법으로 mp3를 다운로드 받을 필요 없이 월 구독비용만 지불하면 인터넷이 되는 어느곳이든지 음악을 들을 수 있는 세상을 살고 있습니다.
그렇지만 종종 인터넷이 되지 않는 기기와 같이 스트리밍 서비스를 사용할 수 없는 환경에서는 부득이하게 음원을 mp3로 변환해서 사용해야 하는 경우가 있습니다. y2mate와 같이 유튜브 영상에서 음원을 추출해주는 서비스가 있기에 음원을 확보하는 것은 어렵지만은 않습니다.
음원파일을 구할 수 있는 사이트 중 하나였던 브금저장소(BGM Store)에서도 과거에는 다운로드를 할 수 있었으나 최근에는 회원 외에는 다운로드가 제한된 것을 확인할 수 있습니다.
Chrome(Microsoft Edge) 웹브라우저에서 자신이 확보하고 싶은 음원 페이지에 접속 하신 후 해당 음원의 재생 버튼을 클릭하신 다음 F12 버튼을 클릭합니다.
아래와 같은 설정 창이 나타나면 점 세개(…) 버튼을 클릭하신 다음 도크 사이드(별도의 창으로 도킹 해제)를 설정하여 넓은 화면으로 설정창을 변경해줍니다.
넓어진 도구 창에서 '응용 프로그램' 탭 선택 후 '프레임→top→미디어 ' 메뉴를 탐색하시면 재생중인 음원의 mp3 파일이 있는 것을 확인하실 수 있습니다.
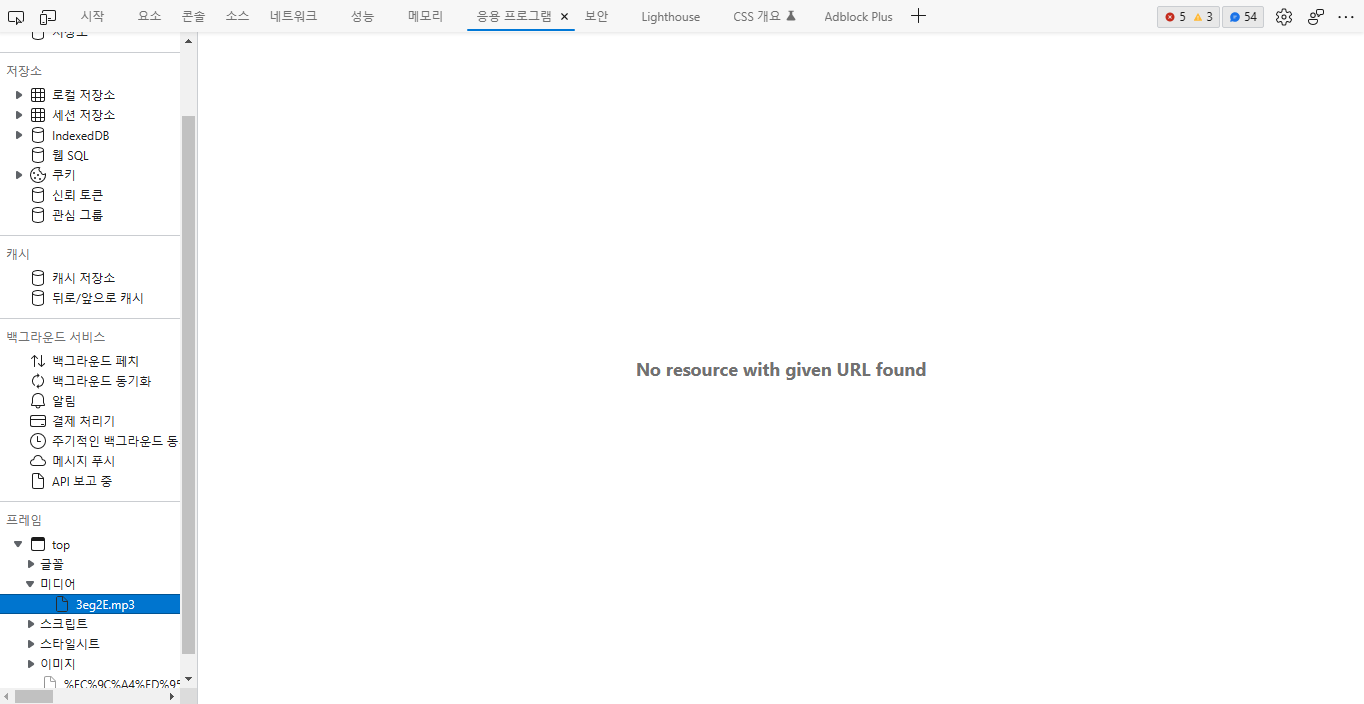
미디어 메뉴에 있는 mp3 파일 부분을 더블클릭하면 웹브라우저에서 mp3 파일의 다운로드가 시작됩니다.
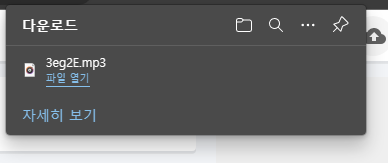
'공대생의 팁' 카테고리의 다른 글
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
|---|---|
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
| Windows Powershell로 긴 명령어를 짧게 만드는 function 함수 사용 (0) | 2022.05.12 |
설정
트랙백
댓글
글
Windows에서 scann 라이브러리 설치하기
인공지능 프로그래밍 개발을 하다보면 거의 대부분의 라이브러리가 Linux를 기반으로 설계되어 있습니다. 그러다보니 Windows 환경에서 개발을 시도하려 하다보면 Ubuntu에서 단지 한 줄의 명령어 입력으로 해결되는 과정이 번거롭게 되는 일들이 많습니다. 특히 특정 패키지에 종속된 패키지를 설치할 때 이를 해결하는 것이 상당한 시간이 소요 되는 경우가 많습니다.
이번 포스팅에서는 Google Research에서 개발한 scann 라이브러리를 Windows 환경에 맞추어 설치하는 방법에 대해 소개드리고자 합니다.
ScaNN
ScaNN(Scalable Nearest Neighbors)은 규모에 따라 효율적인 벡터 유사성 검색을 수행할 수 있는 라이브러리입니다.
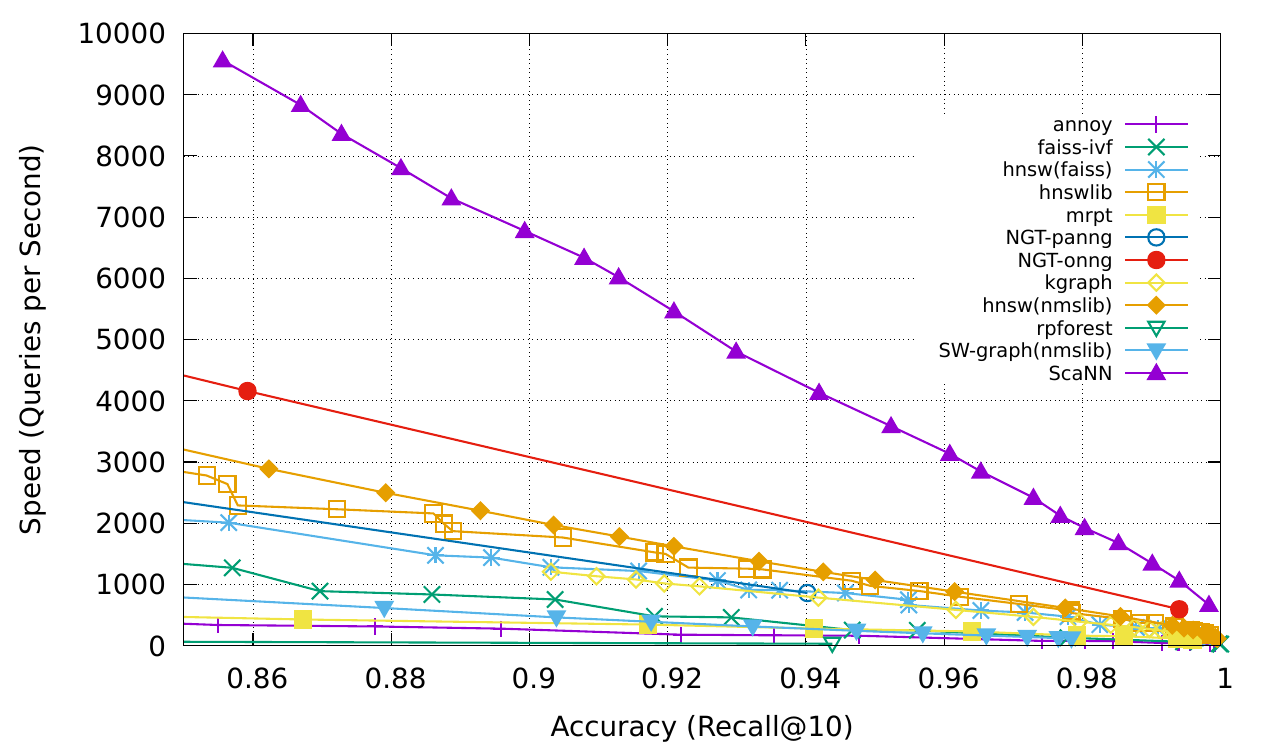
ScaNN은 크기와 분포가 다른 데이터셋에 맞도록 구성할 수 있습니다. Tensorflow와 Python API를 모두 갖추고 있으며, 라이브러리가 대규모 데이터셋에서 강력한 성능을 발휘할 수 있게 해줍니다
Linux 환경에서 ScaNN은 다음과 같은 명령어 단 한줄로 바로 설치가 가능합니다.
$ pip install scann
그러나 Windows에서는 ScaNN 라이브러리가 별도로 설치되어 있지 않아 직접 패키지를 다운로드 하여 설치해야 합니다. 지금부터는 Windows 환경에 맞추어 ScaNN을 설치하는 방법에 대해 다루어보도록 하겠습니다.
----------------
1. 아래의 Google Research의 github 웹페이지에서 소스코드를 다운로드 받습니다.
https://github.com/google-research/google-research/archive/refs/heads/master.zip
※TensorFlow 2.10 버전까지 Windows 로컬 환경의 GPU를 사용할 수 있습니다. 2.11 버전 이후부터 Windows에서 GPU를 사용하기 위해서는 Docker에 설치하여 사용할 수 있으나 Windows 10의 경우 Insider Preview 모드에서만 Docker에서 GPU를 사용할 수 있습니다.
이 포스팅에서는 TensorFlow 2.10 버전을 기준으로 설명드릴 예정이며 만약 Windows 로컬 환경에서 GPU 사용을 원하시는 분은 TensorFlow 2.10 버전에서 사용할 수 있는 ScaNN 1.2.8 버전을 첨부드리오니 해당 소스코드를 활용하시길 권장드립니다.
2. ScaNN 버전에서 호환되는 TensorFlow 버전을 설치합니다. ScaNN 1.2.8 버전을 기준으로 TensorFlow 2.10 버전을 설치합니다. TensorFlow 2.10 버전의 경우 Python 3.10 이하 3.7 이상의 버전을 지원하므로 Python 또한 적합한 버전으로 설치해줍니다.
pip install tensorflow==2.10 python<=3.10
3. 자신이 설치하는 TensorFlow와 호환되는 Cuda와 Cudnn 버전을 아래의 사이트에서 확인하여 cudatoolkit과 cudnn을 설치합니다.
https://www.tensorflow.org/install/source_windows#tested_build_configurations
Windows의 소스에서 빌드 | TensorFlow
Check out sessions from the WiML Symposium covering diffusion models with KerasCV, on-device ML, and more. Watch on demand 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English Windows의 소스에서 빌드 컬렉션을
www.tensorflow.org
TensorFlow 2.10을 기준으로 cuda 11.2 버전과 cudnn 8.1 버전이 호환됨을 확인할 수 있습니다. 자신이 설치하는 TensorFlow의 호환 버전에 맞추어 cuda와 cudnn 및 msvc를 설치해줍니다.
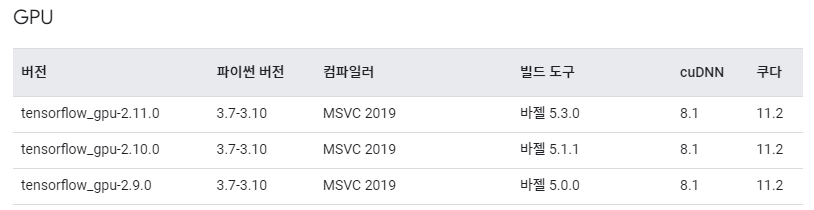
conda install cudatoolkit=11.2 cudnn=8.1
MSVC2019는 아래의 링크를 통해 설치하실 수 있습니다.
https://aka.ms/vs/17/release/vs_BuildTools.exe
4. ScaNN 소스코드 설치
지금까지의 진행을 통해 ScaNN 소스코드를 빌드할 수 있는 환경을 갖추었습니다. 다음으로 ScaNN 소스코드를 아래의 명령어를 통해 설치를 완료하실 수 있습니다.
> cd scann
> pip install -e .
'공대생의 팁' 카테고리의 다른 글
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
|---|---|
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
| Windows Powershell로 긴 명령어를 짧게 만드는 function 함수 사용 (0) | 2022.05.12 |
| Cannot Run Git 오류 발생시 해결 방법(PyCharm, AndroidStudio, Intellij IDEA) (0) | 2022.01.07 |
