검색결과 리스트
분류 전체보기에 해당되는 글 440건
- 2023.05.20 AI로 Labeling을 자동으로 더 편하게 - AnyLabeling
- 2023.04.08 인공지능 모델 최적화 배포 라이브러리 - MMDeploy
- 2023.03.27 MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기)
- 2023.02.18 Lableme로 Coco Dataset과 VOC Dataset 만들기
- 2023.01.27 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV
- 2023.01.24 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법
- 2023.01.05 Windows에서 scann 라이브러리 설치하기
- 2022.12.23 추운 겨울 한적한 마을에 역이 다시 들어서다 - 경의선 운천역[2022.12.18]
- 2022.11.08 vscode에서 Java 클래스 경로 추가하는 방법
- 2022.10.09 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 1
- 2022.09.20 P2P 투자 법인 설립 후기(1) - 설립 준비 전 고려할 사항들 1
- 2022.08.04 VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기
글
AI로 Labeling을 자동으로 더 편하게 - AnyLabeling
지난달 메타(페이스북)에서 학습되지 않은 물체(Unlabeled object)도 감지하여 이를 디테일하게 나타내는 Segment Anything 모델(SAM)이 공개된지 불과 1개월이 지난 현재 무려 피인용수가 50을 돌파할 정도로 Semantic Segmentation 분야에서 상당한 주목을 받고 있습니다. 실제 성능을 보았을 때 이미지 내의 Object들을 상당히 디테일하게 찾아주는 점이 상당히 놀라웠습니다. Vision 분야를 연구하는 저에게 있어 SAM 알고리즘은 ChatGPT에 버금갈 정도로 놀라운 성능을 보였습니다.
이러한 SAM 모델을 사용하여 Labeling 작업을 대신 할 수 있으면 편하겠다고 생각을 해보았었는데 이러한 상상을 벌써 하신 분이 계시다니! 어떤 똑똑한 개발자 분께서 SAM 알고리즘을 사용하여 자동으로 Labeling 작업을 수행할 수 있게 해주는 훌륭한 Tool인 AnyLabeling을 무려 오픈소스로 공개하였습니다.
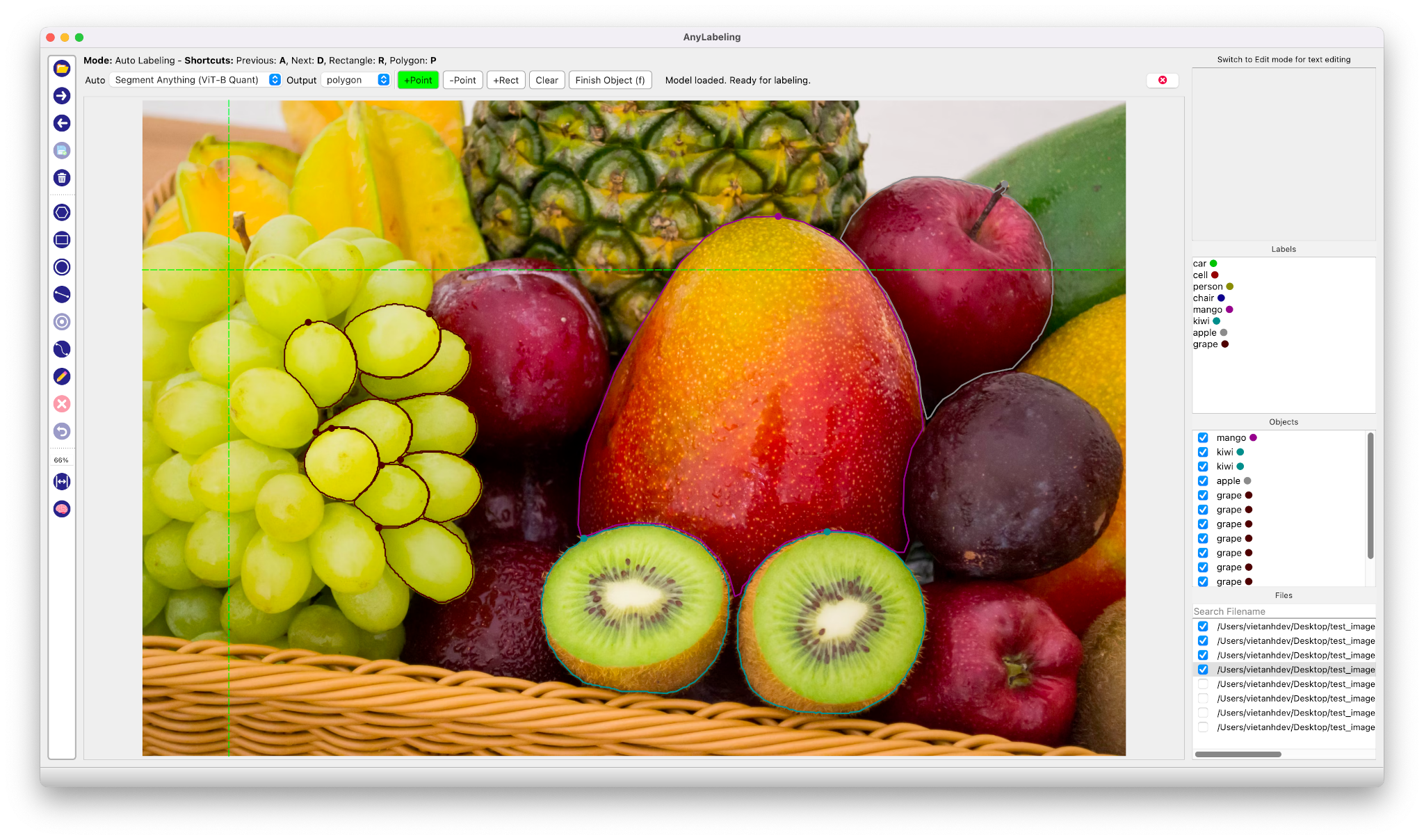
인터페이스는 전반적으로 기존의 Labeling 오픈소스인 Labelimg과 Labelme와 같은 구성으로 기존에 해당 Tool을 사용해보셨던 분들이라면 금새 익숙하게 AnyLabeling을 사용할 수 있도록 설계되었습니다. 즉, 기존의 Labeling 방식대로 Bounding box나 Polygon 방식으로 Labeling을 할 수 있습니다.
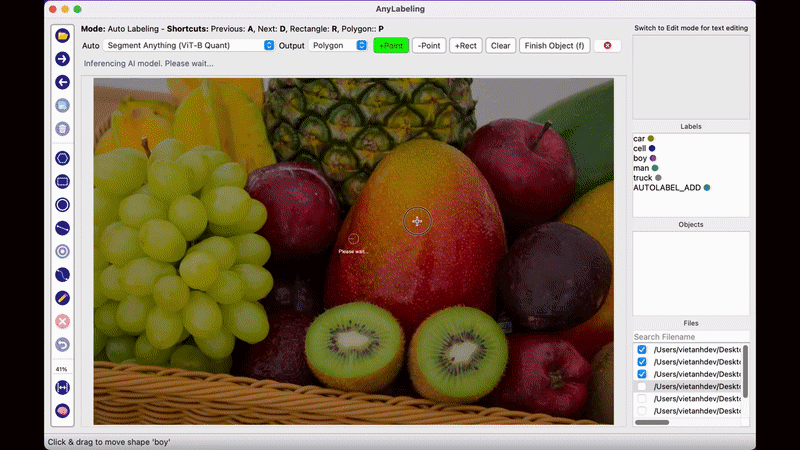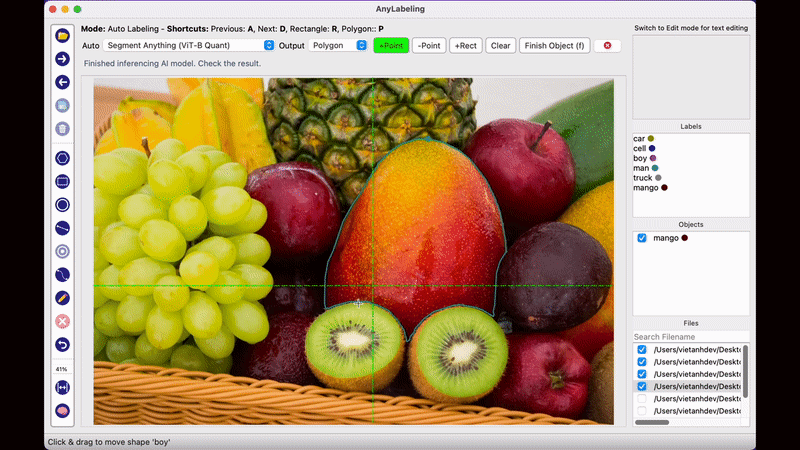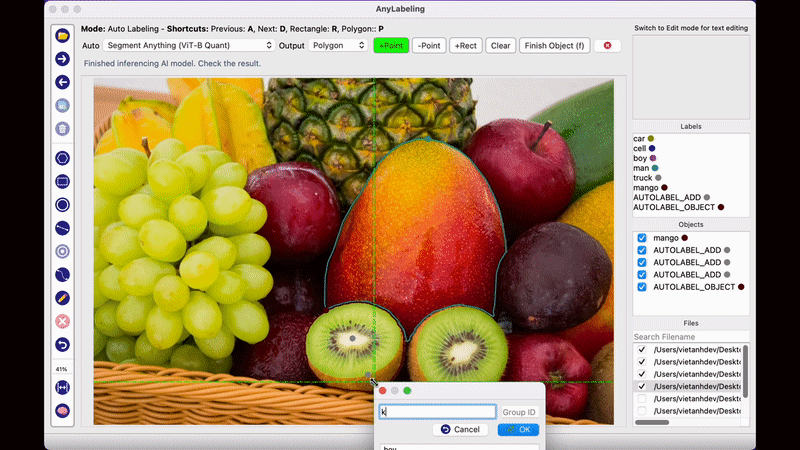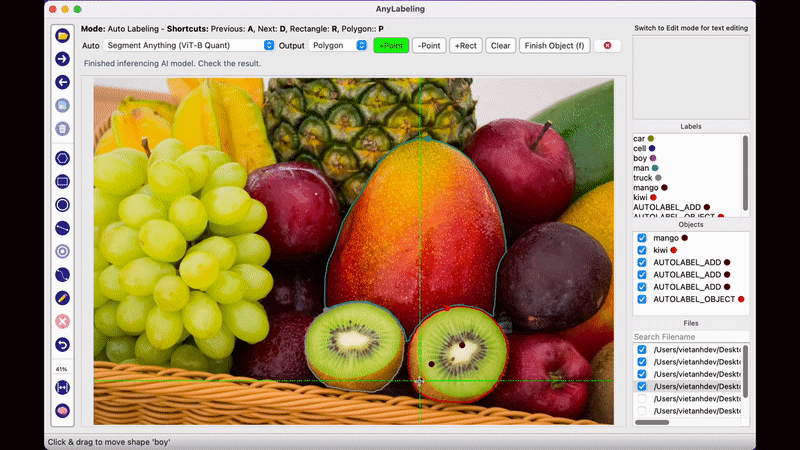
AnyLabeling의 가장 두드러지는 장점이라면 메타AI에서 공개한 Segment Anything 모델을 사용하여 단지 이미지를 클릭하는 것만으로도 물체를 자동으로 Segmentation Labeling 작업을 해준다는 점입니다. 생각보다 Labeling의 품질도 만족스러워 이전처럼 Labeling을 하기 위해 점을 한땀 한땀 클릭하는 작업을 많이 줄일 수 있을 것으로 보입니다.
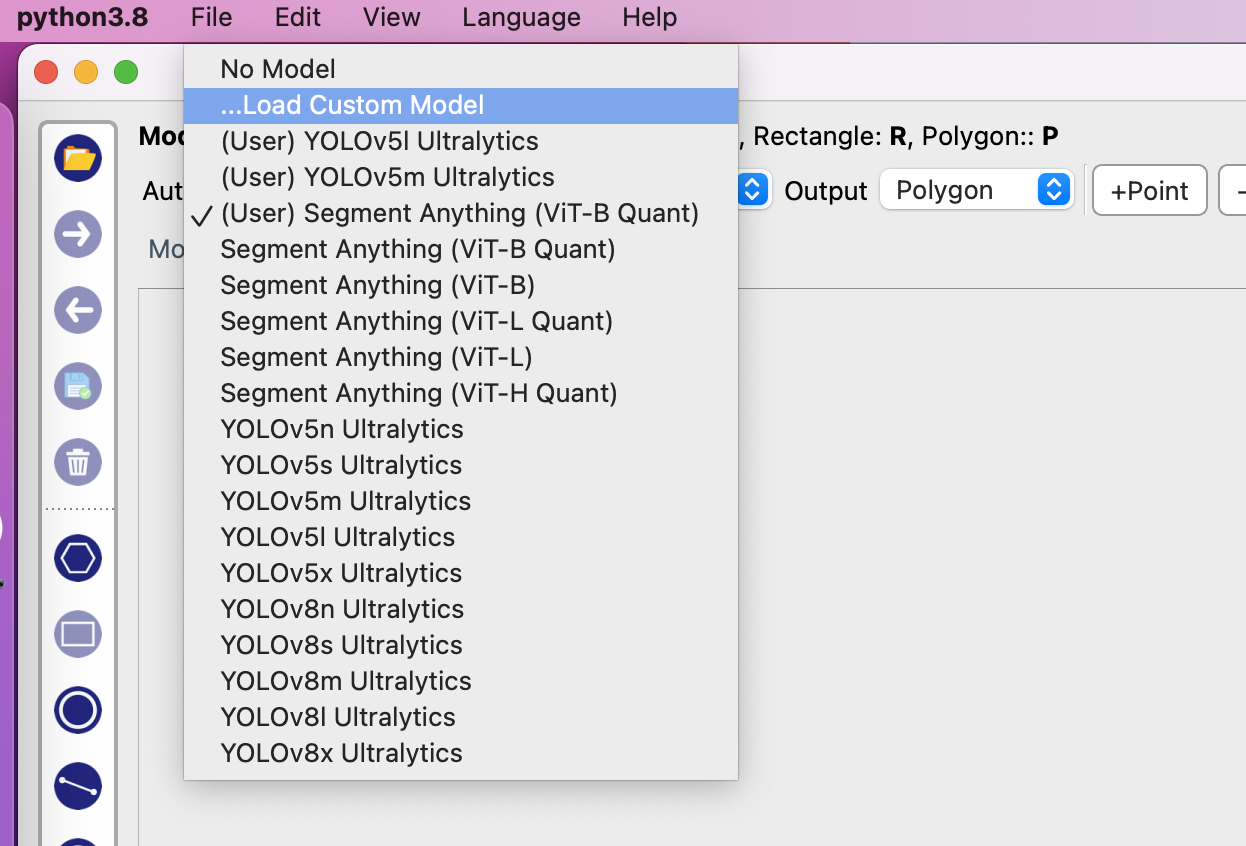
2023년 5월 시점에서 AnyLabeling은 SAM과 YOLOv5, YOLOv8 알고리즘을 제공하고 있으며, 자신이 원하는 모델을 추가하여 자동 Labeling 작업을 수행할 수 있습니다.
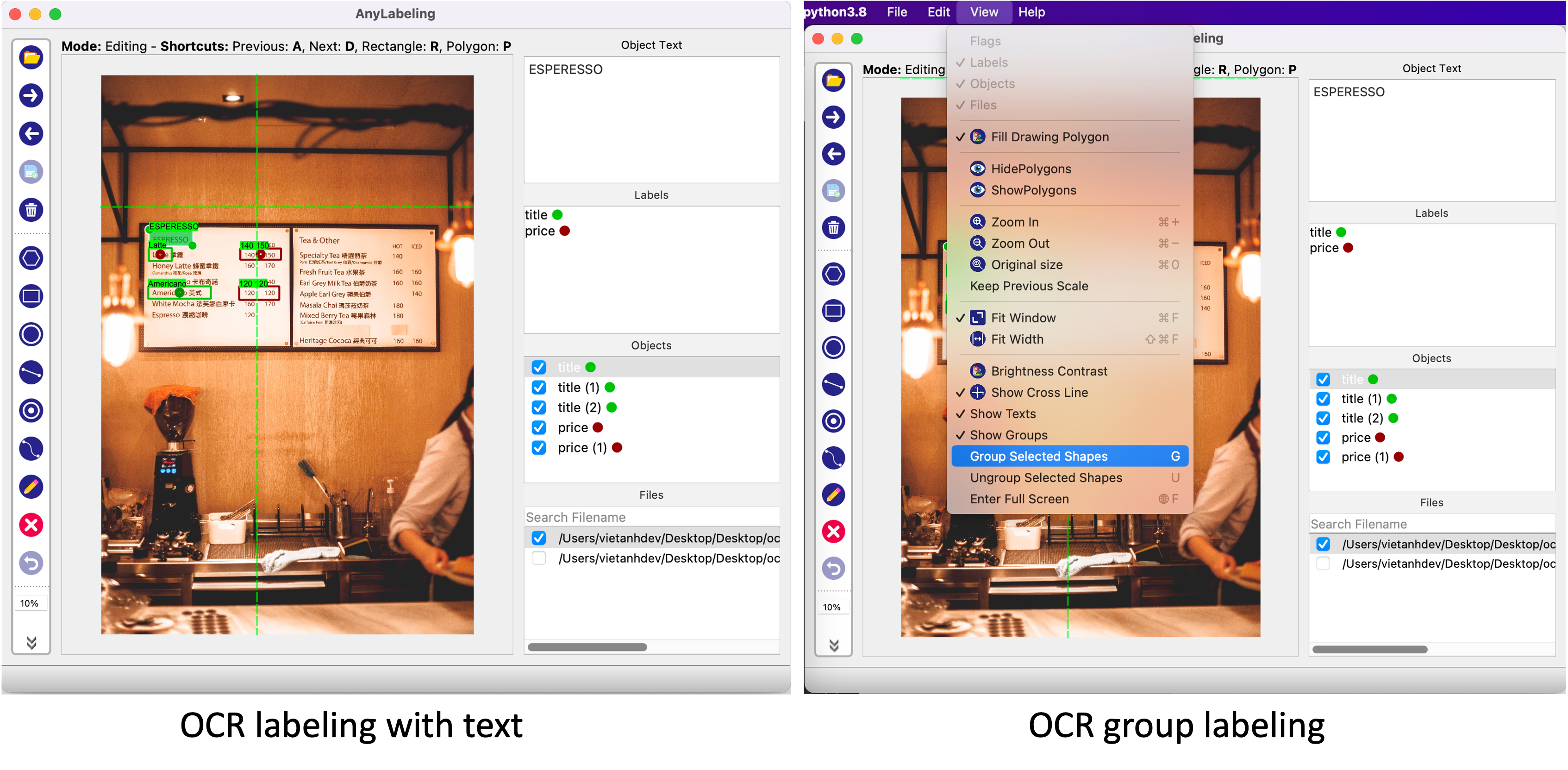
Anylabeling의 또다른 특징 중 하나는 Label에 텍스트 데이터를 남길 수 있다는 점입니다. 단순히 해당 객체의 특징을 설명하기 위한 목적으로도 사용할 수 있지만, 글자 판독 기술인 OCR 데이터를 구축하기 위해 사용하는 방법으로 사용할 수 있습니다. 지금까지 공개된 오픈소스 Labeling Tool 중에서 OCR을 위한 텍스트 데이터를 기록하 수 있는 Tool은 Anylabeling이 그나마 사용하기 편한 것 같습니다.
AnyLabeling은 모든 종류의 운영체제(Windows, Linux, MacOS)에서 사용하실 수 있습니다. AnyLabeling Github 사이트에서 아래의 주소를 통해 자신의 운영체제에 맞는 최신 버전을 설치하여 사용하시기 바랍니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from Segment Anything and YOLO! - vietanhdev/anylabeling
github.com
AnyLabeling에 대해 좀 더 자세한 내용을 알고 싶으신 분은 아래의 공식 페이지를 참조해주시기 바랍니다.
AnyLabeling - Smart Image Labeling Tool – AnyLabeling
Effortless data labeling With AI support from Segment Anything and YOLO models. Get started →
anylabeling.com
'공대생의 팁' 카테고리의 다른 글
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
|---|---|
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
설정
트랙백
댓글
글
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오래 걸리는 경우가 있습니다. 이는 개발 단계에서 아무리 좋은 GPU를 사용한다 하더라도 해당 GPU에 모델이 최적화 되어있지 않은 경우 GPU의 성능 대비 좋은 성능을 기대하기 어려운 현상이 있습니다.
개발 단계에서 만들어지는 모델은 다양한 환경에서도 실행될 수 있는 소스코드로 배포되어 어떤 환경에서도 구동될 수 있도록 할 수 있습니다. Nvidia에서 공개한 TensorRT와 같은 모델 최적화 라이브러리를 사용하면 특정 환경의 GPU에서 모델의 Inference 속도가 향상되는 것을 확인할 수 있습니다.

그러므로 설계가 완료된 모델을 배포할 때, 모델이 배포되는 환경에서 최적화되어 좋은 성능을 발휘할 수 있도록 관리하는 과정 또한 매우 중요합니다. OpenMMLab에서 공개한 MMDeploy는 지금까지 OpenMMLab에서 공개한 MMDetection, MMSegmentation등과 같은 딥러닝 라이브러리를 특정 환경에서 최적화 설계되어 배포할 수 있도록 해주는 라이브러리입니다.

MMDeploy를 사용하여 MMCV로 설계된 모델들을 범용 딥러닝 모델인 ONNX로 변환하여 다른 딥러닝 라이브러리로 변환하여 사용하거나 TensorRT를 사용해 자신이 사용하고자 하는 GPU에 모델을 최적화하여 사용할 수도 있습니다.
MMDeploy는 아래의 Github 사이트를 통해 소스코드를 다운로드 받으실 수 있습니다.
https://github.com/open-mmlab/mmdeploy
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
Github 공식 사이트를 통해 자신이 구현하고자 하는 환경의 운영체제(Linux, Windows, macOS 등)에서 직접 설치하실 수 있습니다.
다만, 직접 설치하는 과정이 상당히 복잡하기 때문에 만약 Linux 환경에서 사용하고자 하시는 분은 Docker를 사용하여 설치하시는 것을 적극적으로 권장드립니다. Ubuntu에서 Docker를 설치하는 방법은 아래의 사이트를 참조해주시기 바랍니다.
https://dongle94.github.io/docker/docker-ubuntu-install/
[Docker] Ubuntu에 Docker 설치하기
리눅스 OS 중 우분투 OS에서 도커(Docker) 프로그램을 설치하는 방법을 알아본다.
dongle94.github.io
Docker 환경에서 GPU 버전의 MMDeploy 설치를 시도하면 아래와 같은 에러가 발생하는 경우가 있습니다.
docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
이 경우 아래의 블로그에서 소개하는 방법과 같이 nvidia-container-toolkit을 설치해주면 쉽게 해결하실 수 있습니다.
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
https://bluecolorsky.tistory.com/110
[정보] docker: Error response from daemon: could not select device driver with capabilities: [[gpu]] 문제 해결하기
도커를 사용하다 보면 다양한 문제에 맞닥뜨리게 된다. 해결하기 쉬운 문제부터 어려운 문제까지 수많은 문제들이 존재하는데 사용할때마다 항상 다른 오류가 발생하여 문제가 발생할때마다
bluecolorsky.tistory.com
'프로그래밍 팁' 카테고리의 다른 글
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
|---|---|
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
설정
트랙백
댓글
글
MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기)
제가 인공지능에 대해 한창 공부를 할때마다 가장 아쉬웠던 점 중 하나는 자신이 구현하고자 하는 모델에 적합한 데이터를 구하는 것이 어려웠던 것이었습니다. 단지 사람을 감지해내는 기술이 필요한 것이라면 SOTA 알고리즘을 찾은 다음 고성능의 기학습된 모델을 적용하는 것이 가장 좋고 실제로도 제가 다시 재학습 해서 만든 모델보다도 성능이 뛰어나기 때문에 굳이 데이터셋을 직접 만드는 고생을 할 이유가 없기도 합니다.
그러나 내가 구현하고자 하는 물체가 기존의 모델들에 구현되어 있지 않는 경우에는 어쩔수없이 데이터를 수집하여 나만의 데이터셋을 만들어야만합니다. 그러나 기존의 모델들의 성능에 준하는 새로운 모델을 만들기 위해서는 무려 수십만장의 데이터를 수집해야 하는데 이를 개인이 직접 수집하기에는 시간과 비용이 만만치 않습니다.
그렇다면, 내가 원하는 데이터셋을 만들어 이를 테스트해 볼 수 있는 방법은 없는걸까요? 이번 포스팅에서는 Custom Dataset을 본인이 직접 제작하는 방법과 이 데이터셋을 사용하여 MMCV 기반 딥러닝 모델(MMDetection, MMSegmentation)에서 Custom Dataset을 학습해보고자 합니다.

1. 데이터 수집 및 Labeling
원하는 모델 설계에 앞서 자신이 감지하고자 하는 물체가 실제 학습이 가능한지 우선 확인해 볼 필요가 있습니다. 우선 자신이 학습하고자 하는 이미지를 100장 정도 수집한 후 Labeling 작업을 수행합니다. 최근에는 Labeling 작업을 쉽고 효율적으로 수행할 수 있는 Tool들이 많아졌지만 Tutorial 목적으로 작업을 하고자 하시는 분들께서는 추가 비용을 요구하지 않는 오픈소스인 LableMe를 사용해보는 것을 추천 드립니다.
LabelMe를 사용하는 방법에 대해 제가 이전에 정리하였던 자료가 있으니 아래의 포스팅을 참조해주시길 바랍니다.
Lableme로 Coco Dataset과 VOC Dataset 만들기
고성능의 인공지능을 만들기 위한 가장 중요한 작업 중 하나는 최대한 많은 양질의 데이터를 확보하는 것입니다. 상상을 뛰어넘는 인공지능의 놀라운 발전을 보았을 때 마치 AI를 연구하는 사람
elecs.tistory.com
2. 보편적으로 사용되는 Custom Dataset 양식으로 변환
지금까지 공개된 인공지능 모델들의 대부분은 많은 사람들이 자신들이 개발한 소스코드를 쉽게 사용할 수 있도록 설계되어 있습니다. 특히 기존에 공개된 COCO 데이터셋과 PascalVOC는 대중적으로 공개된 퍼블릭 데이터셋으로 누구가 쉽게 접할 수 있어 인공지능에 입문하는 사람들이 처음으로 사용하게 되는 데이터셋이기도 합니다.
위에서 언급한 제 이전의 포스팅 자료에서 소개드렸던 LabelMe로 Labeling 작업을 수행한 다음 COCO 혹은 PascalVOC 데이터셋 양식으로 변경하는 내용에 대해 다루었으니 해당 부분을 참조해주시길 바랍니다.
3. MMCV에서 사용하기
위의 과정을 통해 Custom 데이터셋을 만드셨다면 이를 가지고 OpenMMLab에서 제작한 MMCV에서 바로 사용하실 수 있습니다. LableMe를 통해 제작한 Custom Dataset으로 MMDetection과 MMSegmentation에서의 동작을 확인하였습니다. 각 프로젝트에 바로 사용할 수 있는 데이터셋 양식은 다음과 같습니다. 나머지 데이터셋 양식의 경우 추가적인 설정을 해주시면 사용하실 수 있습니다.
MMDetection: COCO Dataset
LabelMe를 기준으로 Custom Dataset을 Coco 방식으로 변활할 때 Label을 수행한 Json 파일을 Train 용도와 Test 용도로 구분한 다음 각 용도별 Dataset을 Coco로 변환하면 Train 그리고 Test 수행을 위한 Annotation.json 파일을 생성할 수 있습니다.
위의 과정을 통해 생성된 Coco Dataset은 MMDetection에서 제공되는 config 파일에 있는 기본 dataset을 수정하여 자신의 환경에 맞도록 고쳐주시면 바로 사용하실 수 있습니다.
/mmdetection/configs/_base_/datasets/coco*.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/' #Custon Coco Dataset의 폴더 위치
....
#Train, Val, Test 데이터의 Json 및 이미지 파일 경로
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/train.json',
img_prefix=data_root + 'train/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json',
img_prefix=data_root + 'val/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/test.json',
img_prefix=data_root + 'test/',
pipeline=test_pipeline))
....
|
cs |
MMSegmentation: PascalVOC
LableMe에서 labelme2voc로 변환한 데이터들은 MMSegmentation에서 바로 사용하실 수 있습니다. 여기서 만들어진 Segmentation 이미지들 중에서 train.txt, val.txt, test.txt로 사용하고자 하는 파일들의 제목들을 작성해주시고 아래와 같이 Custom Dataset으로 구성하실 수 있습니다.
/mmsegmentation/configs/_base_/datasets/custom_voc12.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
# dataset settings
dataset_type = 'PascalVOCDataset'
data_root = 'data/VOCdevkit/VOC2012' # Custom Voc 데이터셋의 폴더 위치
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='test.txt',
pipeline=test_pipeline))
|
cs |
'프로그래밍 팁' 카테고리의 다른 글
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
|---|---|
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
설정
트랙백
댓글
글
Lableme로 Coco Dataset과 VOC Dataset 만들기
고성능의 인공지능을 만들기 위한 가장 중요한 작업 중 하나는 최대한 많은 양질의 데이터를 확보하는 것입니다. 상상을 뛰어넘는 인공지능의 놀라운 발전을 보았을 때 마치 AI를 연구하는 사람들이 고상한 기술을 사용하여 인공지능을 만드는 것처럼 보이지만 안타깝게도 학습 데이터가 확보되지 않은 인공지능은 고성능을 발휘하기 어렵습니다.
그렇다고 해서 데이터만 잔뜩 확보했다고 하여 고성능의 인공지능 기술이 뚝딱 하고 만들어지는 것은 결코 아닙니다. 확보된 데이터를 인공지능이 학습할 수 있도록 전처리 하는 과정이 필요한데 주어진 사진에서 학습하고자 하는 물체의 이름과 위치 등을 표시하여 인공지능이 이를 학습할 수 있도록 만들어주어야 합니다. 흔히 이 전처리 과정을 '레이블링(Labeling)이라고 합니다.
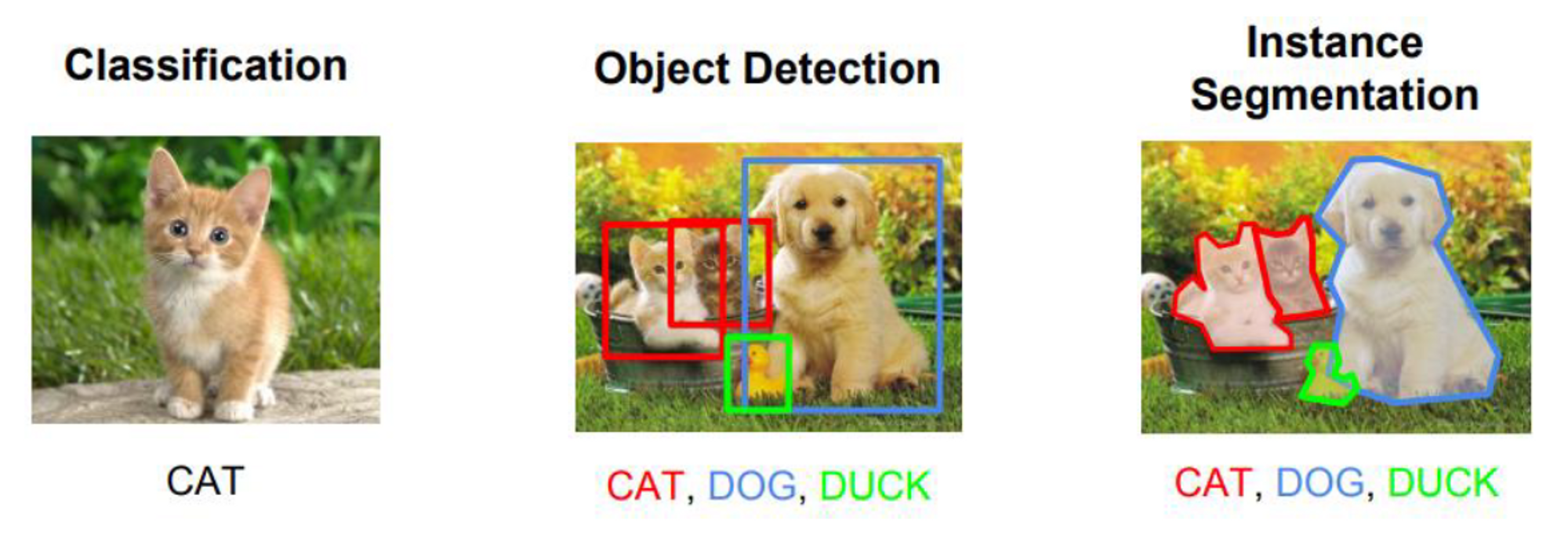
산업 분야에서 인공지능의 활용 영역이 확대됨에 따라 수집된 데이터의 전처리를 전문으로 하는 기술에 대한 수요가 늘어났고, 이를 처리할 수 있는 성능 좋은 Labeling 기술들이 소개되고 있습니다. 단지 사진을 선택했을 뿐인데 사진 속 특성(Feature)을 추출하고 이에 맞는 Labeling 작업까지 자동으로 해주는 기술이 등장할 만큼 지금 이 순간에도 좋은 도구들이 소개되고 있습니다.
하지만, 인공지능을 시범 도입하기 위해 고가의 Labeling tool을 구매하여 사용하는 것은 상당히 부담스러울 수 밖에 없습니다. 다행히도, 자신의 Field에 인공지능 적용 실용성 여부를 검토할 수 있는 데이터셋 전처리를 가능하게 해주는 무료 도구들이 오픈소스로 공개되어있습니다. 이번 포스팅에서는 지금 이 순간에도 무료로 공개되어 있으며, 누구나 쉽게 어떤 환경에서도 사용할 수 있는 LabelMe를 소개드리도록 하겠습니다.

LabelMe는 pip로 설치하여 바로 사용하실 수 있습니다.
$ pip install labelme pyqt5 pyside2
혹은 아래의 사이트를 통해 소스코드를 직접 설치하실 수 있습니다.
https://github.com/wkentaro/labelme
GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation). - GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, recta...
github.com
labelme를 실행하면 상당히 직관적인 UI툴을 갖추고 있는 것을 보실 수 있습니다.
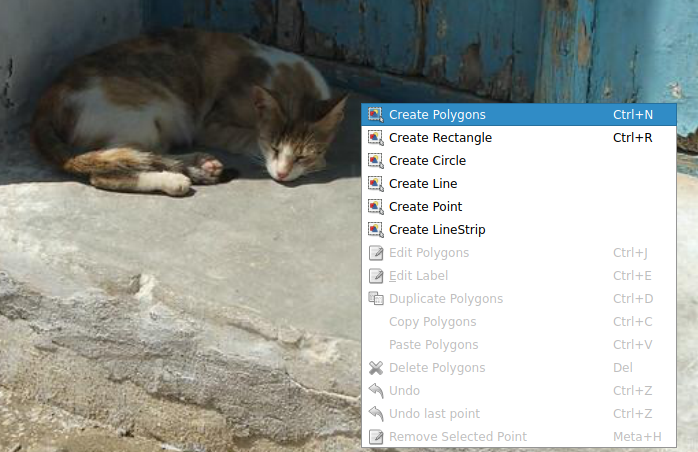
레이블링을 수행하고자 하는 이미지를 불러온 다음 마우스 오른쪽 버튼을 클릭하여 'Create Polygons'를 클릭하여 이미지의 객체 주변에 점을 찍어가며 객체를 표시해줍니다.
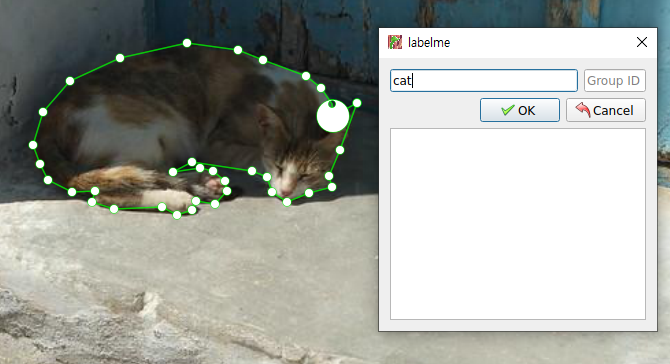
주변에 점을 찍다 한 바퀴 정도 돌게되여 처음 찍은 점으로 돌아오게 되었을 때 1개의 폴리곤이 완성되며 이 때 표시한 객체의 속성을 입력해줍니다.

Labeling이 완료되면 위와 같이 작업이 완료된 모습을 확인하실 수 있습니다. 혹시 표시하고자 하는 객체를 네모 모양으로 하고싶으신 분은 'Create Rectangle'을 선택하여 표시할 수 도 있습니다.
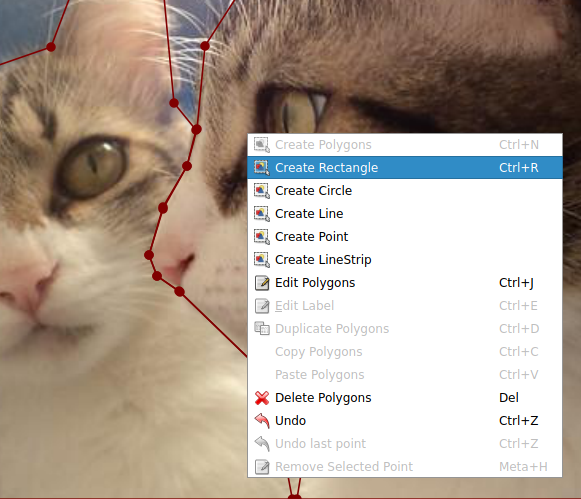
Object Detection을 수행하는 방법과 같이 Rectangle로 객체를 감싼 다음 Label을 붙여주면 됩니다.
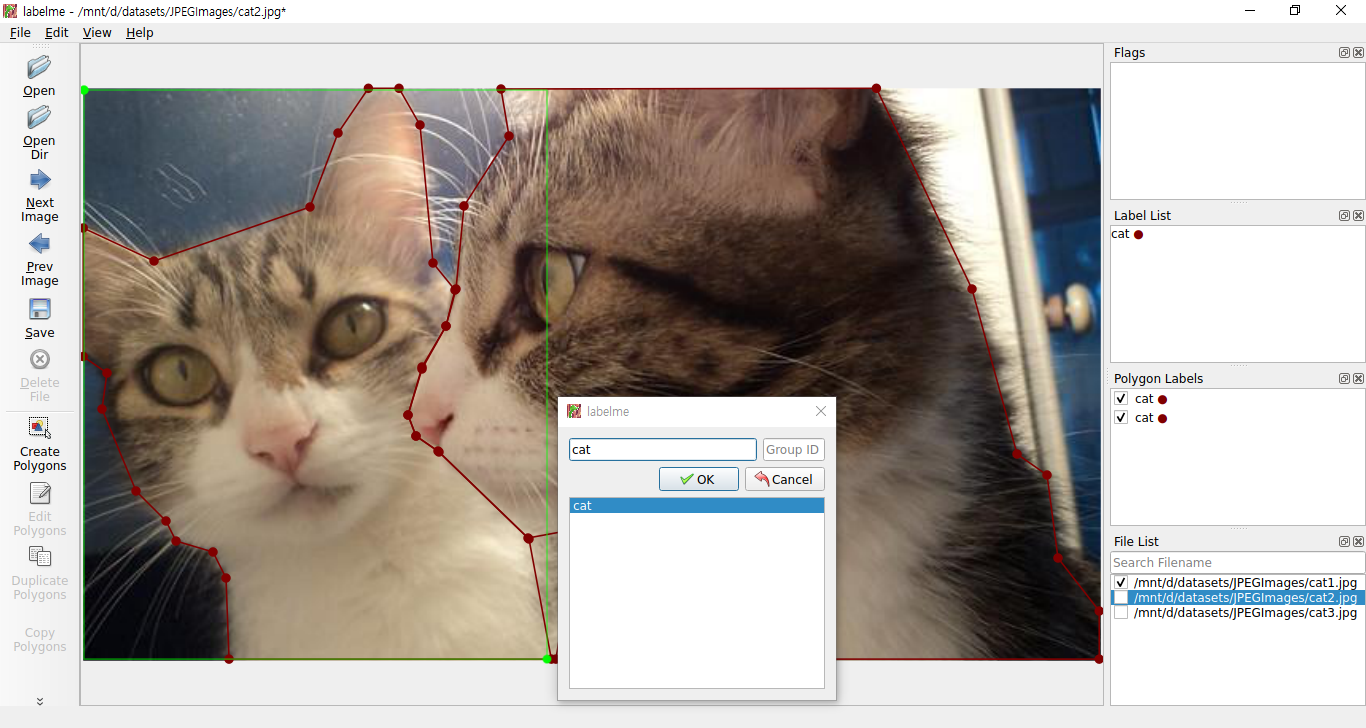
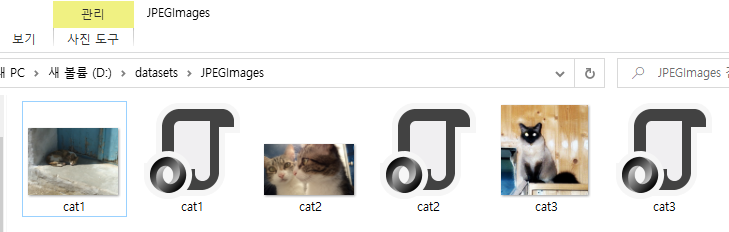
지금까지 진행한 작업들을 확인해봅니다. LabelMe로 작업하였던 내용들이 이미지 폴더에 함께 들어있는 것을 확인하실 수 있습니다.
Pascal VOC 방식의 Dataset 만들기
지금부터 LabelMe로 만든 Label 정보들을 인공지능이 학습할 수 있도록 전처리과정을 통해 Dataset을 만드는 과정을 설명드리도록 하겠습니다. 데이터를 학습할 때 보통 COCO 와 Pascal VOC 방식의 Dataset이 주로 사용되고 있습니다. LabelMe 저자는 LabelMe로 Label을 적용한 정보를 COCO 혹은 Pascal VOC로 변환해주는 소스코드를 제공하고 있습니다. 아래 링크를 통해 다운로드 받으실 수 있습니다.
https://github.com/wkentaro/labelme/tree/main/examples/instance_segmentation
1. Pascal VOC로 변환(labelme2voc.py)
먼저 자신이 Label한 클래스의 명단을 labels.txt 파일로 아래와 같이 작성해주세요. 저의 경우 객체가 고양이 단 하나 뿐이므로 class는 cat 하나입니다.
|
1
2
3
|
__ignore__
_background_
cat
|
cs |
다음으로 lableme2voc.py를 실행하여 이미지와 Label정보가 담긴 폴더의 내용으로 VOC 데이터셋을 생성합니다.
$ python labelme2voc.py '이미지와Label정보가 담긴 폴더명' 'VOC데이터셋 폴더명' --labels labels.txt
해당 명령어를 수행하면 아래와 같이 폴더들이 생성되는 것을 확인하실 수 있습니다.
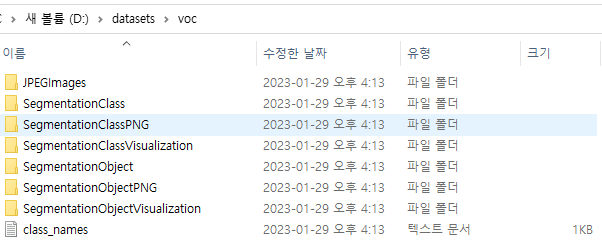
SegmentationObjectVisualization 폴더의 내용을 보시면 아래와 같이 Label이 잘 되어있는 것을 확인하실 수 있습니다.



2. COCO로 변환(labelme2coco.py)
다음으로 Coco Dataset으로 변환하는 방법을 살펴보겠습니다. 위에서 VOC Dataset을 만들때 사용하였던 label.txt에 자신이 만든 Label의 클래스를 적어주신 다음 labelme2coco.py를 사용하여 다음과 같이 실행해줍니다.
$ python labelme2voc.py '이미지와Label정보가 담긴 폴더명' 'VOC데이터셋 폴더명' --labels labels.txt
위 명령어를 실행하면 COCO 양식의 데이터셋이 생성된 것을 확인하실 수 있습니다.

Visualization 폴더 내용을 보면 Label이 적용된 것을 확인하실 수 있습니다.



'공대생의 팁' 카테고리의 다른 글
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
|---|---|
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
설정
트랙백
댓글
글
영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV
2022년 이미지 창작 알고리즘인 Dalle-2의 등장은 학계를 너머 일반인들에게도 상당히 뜨거운 기술이었습니다. 단지 비슷한 사진을 생성하는 GAN의 한계를 뛰어넘어 오직 인간의 창의력으로만 가능할 것만 같았던 창작의 영역까지 인공지능이 정복했다는 것은 인공지능의 기술이 어디까지 발전하였는지 심지어 사람의 한계를 뛰어넘었는지 확인할 수 있던 순간이었습니다. 반면, 오직 인간만의 영역이라 생각했던 미술 분야 마저 인공지능이 정복하지는 않을까 우려하는 분위기도 보입니다.
이토록 AI의 발전속도는 다른 분야와는 비교할 수 없을 정도로 빠르게 변화하고 있는데다 불과 몇 달 만에 더 좋은 성능의 알고리즘이 등장하는 것은 AI학계에서는 일상이 되었습니다. 그러다보니 종종 좋은 아이디어를 가진 알고리즘도 등장하였지만, 빠른 변화 속에 묻혀버린 경우도 없지 않아 있습니다.
이번에 소개드리고자 하는 MMCV는 흔히 MMDetection라는 이름의 알고리즘으로 사람들에게 알려져있으며 지금까지 선보인 Vision 인공지능 알고리즘들을 모아서 단 하나의 프로젝트로 여러 종류의 모델을 사용할 수 있게 해줍니다.
사실 이렇게 여러 종류의 알고리즘들을 종합하여 활용할 수 있게 하는 프로젝트는 메타(페이스북) AI연구소에서 만든 Detectron의 사례가 있습니다. Detectron 또한 MMCV처럼 모든 종류의 알고리즘을 하나의 프로젝트로 사용할 수 있다는 장점이 있으나 Detectron이 Linux 기반에서 만들어져 Windows에서 사용하기 위해서는 일부 코드를 손봐야 하는 불편함이 있었습니다. 하지만 MMCV는 Windows는 물론 Linux, MacOS 등 어떠한 환경을 가리지 않고 사용할 수 있도록 만든 점이 MMCV의 큰 장점이라 할 수 있습니다.

MMCV는홍콩중문대학(The Chinese University of Hong Kong) 멀티미디어 연구실(MMLab)에서 박사과정이었던 카이첸의 주도로 개발되었으며, 2018년 MMDetection과 함께 공개되었습니다. 현재 그는 홍콩중문대학을 졸업하여 상하이 AI Laboratory에서 일하고 있으며, 그가 만든 MMCV 프로젝트는 OpenMMLab의 맴버로서 지금까지 전세계의 인공지능 개발자들이 사용하고 있습니다.
Kai Chen
Kai Chen is currently a Research Scientist & PI at Shanghai AI Laboratory. He is leading the OpenMMLab team, which targets at developing state-of-the-art computer vision algorithms for research and industrial applications, as well as building influential o
chenkai.site
MMCV 설치
MMCV를 설치하기에 앞서 자신의 개발 환경에서 Pytorch를 설치한 다음 MMCV를 설치합니다. 자신의 환경에 적합한 MMCV 환경을 구축해주는 Openmim을 설치합니다.
$ pip install openmim
자신이 설치하고자 하는 MMCV의 버전이 1.x일 경우 mmcv-full을 설치합니다.
$ mim install mmcv-full
만약 자신이 설치하고자 하는 MMCV의 버전이 2.x 이상일 경우 mmcv를 설치해주세요.
$ mim install mmcv
Python을 실행하여 mmcv가 잘 설치되었는지 확인합니다.
import mmcv
print(mmcv.__version__)
축하합니다! 지금부터 여러분은 MMCV를 사용할 수 있게 되었습니다.
Config
MMCV을 원하는 목적에 맞게 사용하기 위해서는 MMCV 라이브러리에서 제공하는 Config의 구조를 이해하는 것이 매우 중요합니다.
MMCV의 Config는 자신이 설계하고자 하는 모델을 직접 설정할 수 있게 해주는 설계도라 할 수 있습니다. MMCV의 라이브러리에서 직접 설정한 기존 모델들은 모두 Config파일로 제공되며 자신이 원하는 모델의 Config 파일을 원본대로 학습할 수도 있고, 자신이 원하는 성능이 구현될 수 있도록 Fine tuning하여 사용할 수도 있습니다.
Config의 기초 원리를 자세하게 정리되어 있는 포스팅이 있어 아래의 링크를 통해 학습하실 수 있습니다.
https://better-tomorrow.tistory.com/entry/MMCV-%EC%9D%98-Config
MMCV 의 Config
# G.py _base_ = ['./base.py'] item = dict(a = {{ _base_.item1 }}, b = {{ _base_.item2.item3 }}) https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html Config — mmcv 1.3.16 documentation Config Config class is used for manipulating config and c
better-tomorrow.tistory.com
MMDetection에 설정된 모델들은 config 폴더에 있으며 자신이 원하는 모델의 config를 찾아서 사용하면 됩니다. 아래의 코드는 Mask R-CNN의 config 파일 중 하나입니다.
mmdetection/configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py
|
1
2
3
4
5
|
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/coco_instance.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
|
cs |
config 파일의 소스코드를 확인해보면 _base_를 통해 config 설정들을 상속하고 있는 것을 확인하실 수 있습니다. 각 소스코드를 간단히 설명드리자면
../_base_/models/mask_rcnn_r50_fpn.py
학습하고자 하는 모델의 구조를 나타냅니다.
../_base_/datasets/coco_instance.py
학습하고자 하는 데이터셋을 설정합니다.
../_base_/schedules/schedule_1x.py
optimizer, epoch 등의 학습 정책을 설정합니다.
../_base_/default_runtime.py
학습 방식(Single, Multiple)등을 설정합니다.
지금까지 MMCV에 대해 기본적인 내용들을 설명드렸습니다. MMlab에서 공개중인 MMDetection과 MMSegmentation등의 라이브러리를 사용하여 다양한 인공지능 모델들을 체험해보시길 바랍니다!
'공대생의 팁' 카테고리의 다른 글
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
|---|---|
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
설정
트랙백
댓글
글
웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법
멜론, 유튜브뮤직 등 요즘은 음원 스트리밍 서비스들이 워낙 많아 인터넷 초창기 시절처럼 불법으로 mp3를 다운로드 받을 필요 없이 월 구독비용만 지불하면 인터넷이 되는 어느곳이든지 음악을 들을 수 있는 세상을 살고 있습니다.
그렇지만 종종 인터넷이 되지 않는 기기와 같이 스트리밍 서비스를 사용할 수 없는 환경에서는 부득이하게 음원을 mp3로 변환해서 사용해야 하는 경우가 있습니다. y2mate와 같이 유튜브 영상에서 음원을 추출해주는 서비스가 있기에 음원을 확보하는 것은 어렵지만은 않습니다.
음원파일을 구할 수 있는 사이트 중 하나였던 브금저장소(BGM Store)에서도 과거에는 다운로드를 할 수 있었으나 최근에는 회원 외에는 다운로드가 제한된 것을 확인할 수 있습니다.
Chrome(Microsoft Edge) 웹브라우저에서 자신이 확보하고 싶은 음원 페이지에 접속 하신 후 해당 음원의 재생 버튼을 클릭하신 다음 F12 버튼을 클릭합니다.
아래와 같은 설정 창이 나타나면 점 세개(…) 버튼을 클릭하신 다음 도크 사이드(별도의 창으로 도킹 해제)를 설정하여 넓은 화면으로 설정창을 변경해줍니다.
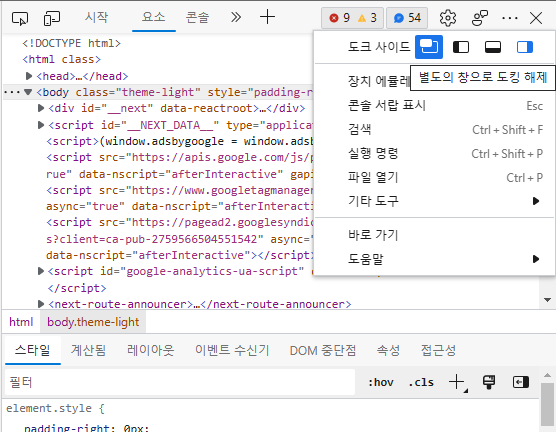
넓어진 도구 창에서 '응용 프로그램' 탭 선택 후 '프레임→top→미디어 ' 메뉴를 탐색하시면 재생중인 음원의 mp3 파일이 있는 것을 확인하실 수 있습니다.
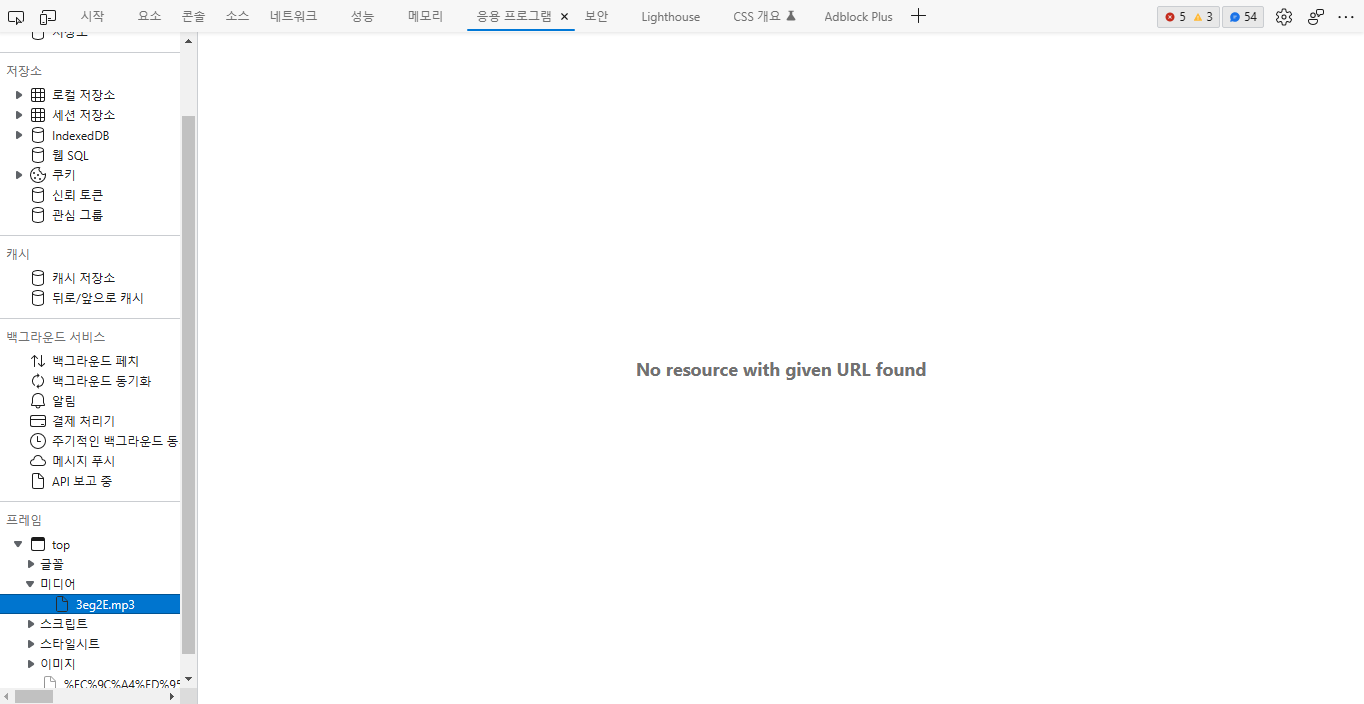
미디어 메뉴에 있는 mp3 파일 부분을 더블클릭하면 웹브라우저에서 mp3 파일의 다운로드가 시작됩니다.
'공대생의 팁' 카테고리의 다른 글
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
|---|---|
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
| Windows Powershell로 긴 명령어를 짧게 만드는 function 함수 사용 (0) | 2022.05.12 |
설정
트랙백
댓글
글
Windows에서 scann 라이브러리 설치하기
인공지능 프로그래밍 개발을 하다보면 거의 대부분의 라이브러리가 Linux를 기반으로 설계되어 있습니다. 그러다보니 Windows 환경에서 개발을 시도하려 하다보면 Ubuntu에서 단지 한 줄의 명령어 입력으로 해결되는 과정이 번거롭게 되는 일들이 많습니다. 특히 특정 패키지에 종속된 패키지를 설치할 때 이를 해결하는 것이 상당한 시간이 소요 되는 경우가 많습니다.
이번 포스팅에서는 Google Research에서 개발한 scann 라이브러리를 Windows 환경에 맞추어 설치하는 방법에 대해 소개드리고자 합니다.
ScaNN
ScaNN(Scalable Nearest Neighbors)은 규모에 따라 효율적인 벡터 유사성 검색을 수행할 수 있는 라이브러리입니다.
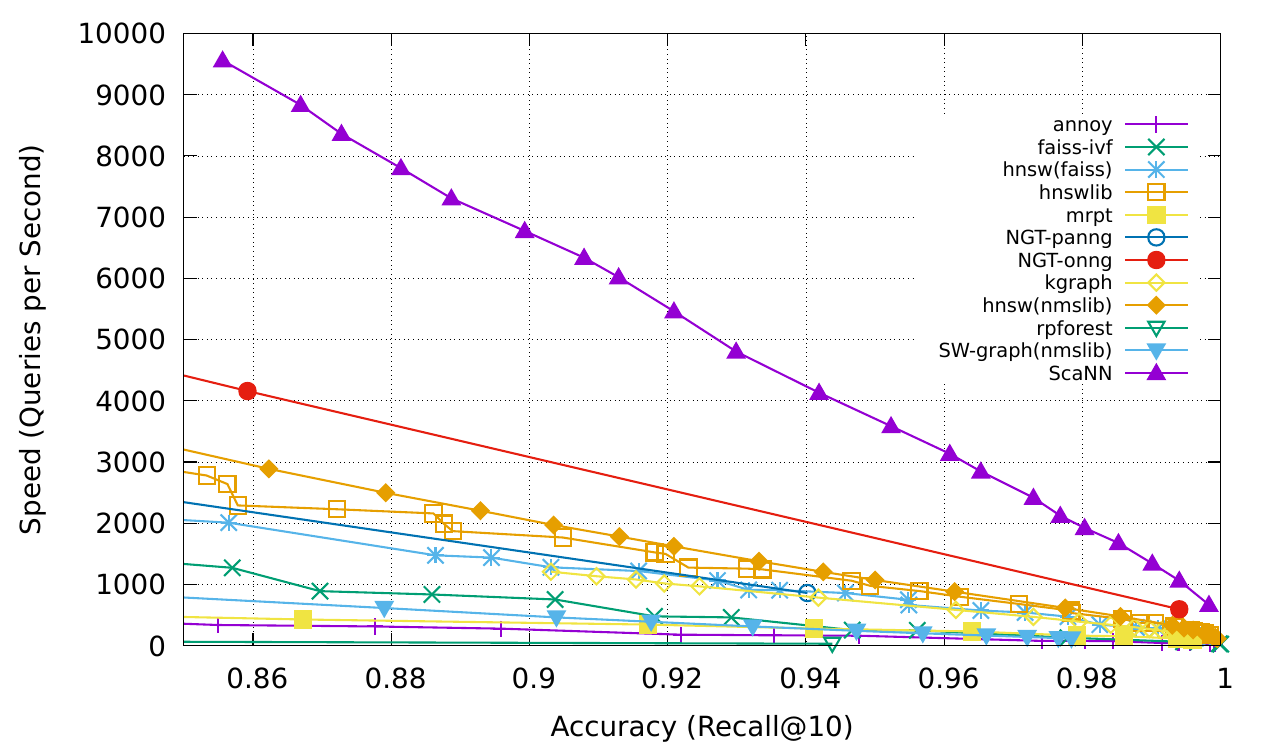
ScaNN은 크기와 분포가 다른 데이터셋에 맞도록 구성할 수 있습니다. Tensorflow와 Python API를 모두 갖추고 있으며, 라이브러리가 대규모 데이터셋에서 강력한 성능을 발휘할 수 있게 해줍니다
Linux 환경에서 ScaNN은 다음과 같은 명령어 단 한줄로 바로 설치가 가능합니다.
$ pip install scann
그러나 Windows에서는 ScaNN 라이브러리가 별도로 설치되어 있지 않아 직접 패키지를 다운로드 하여 설치해야 합니다. 지금부터는 Windows 환경에 맞추어 ScaNN을 설치하는 방법에 대해 다루어보도록 하겠습니다.
----------------
1. 아래의 Google Research의 github 웹페이지에서 소스코드를 다운로드 받습니다.
https://github.com/google-research/google-research/archive/refs/heads/master.zip
※TensorFlow 2.10 버전까지 Windows 로컬 환경의 GPU를 사용할 수 있습니다. 2.11 버전 이후부터 Windows에서 GPU를 사용하기 위해서는 Docker에 설치하여 사용할 수 있으나 Windows 10의 경우 Insider Preview 모드에서만 Docker에서 GPU를 사용할 수 있습니다.
이 포스팅에서는 TensorFlow 2.10 버전을 기준으로 설명드릴 예정이며 만약 Windows 로컬 환경에서 GPU 사용을 원하시는 분은 TensorFlow 2.10 버전에서 사용할 수 있는 ScaNN 1.2.8 버전을 첨부드리오니 해당 소스코드를 활용하시길 권장드립니다.
2. ScaNN 버전에서 호환되는 TensorFlow 버전을 설치합니다. ScaNN 1.2.8 버전을 기준으로 TensorFlow 2.10 버전을 설치합니다. TensorFlow 2.10 버전의 경우 Python 3.10 이하 3.7 이상의 버전을 지원하므로 Python 또한 적합한 버전으로 설치해줍니다.
pip install tensorflow==2.10 python<=3.10
3. 자신이 설치하는 TensorFlow와 호환되는 Cuda와 Cudnn 버전을 아래의 사이트에서 확인하여 cudatoolkit과 cudnn을 설치합니다.
https://www.tensorflow.org/install/source_windows#tested_build_configurations
Windows의 소스에서 빌드 | TensorFlow
Check out sessions from the WiML Symposium covering diffusion models with KerasCV, on-device ML, and more. Watch on demand 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English Windows의 소스에서 빌드 컬렉션을
www.tensorflow.org
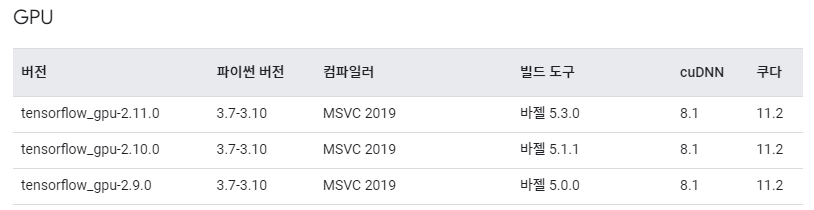
TensorFlow 2.10을 기준으로 cuda 11.2 버전과 cudnn 8.1 버전이 호환됨을 확인할 수 있습니다. 자신이 설치하는 TensorFlow의 호환 버전에 맞추어 cuda와 cudnn 및 msvc를 설치해줍니다.
conda install cudatoolkit=11.2 cudnn=8.1
MSVC2019는 아래의 링크를 통해 설치하실 수 있습니다.
https://aka.ms/vs/17/release/vs_BuildTools.exe
4. ScaNN 소스코드 설치
지금까지의 진행을 통해 ScaNN 소스코드를 빌드할 수 있는 환경을 갖추었습니다. 다음으로 ScaNN 소스코드를 아래의 명령어를 통해 설치를 완료하실 수 있습니다.
> cd scann
> pip install -e .
'공대생의 팁' 카테고리의 다른 글
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
|---|---|
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
| vscode에서 Java 클래스 경로 추가하는 방법 (0) | 2022.11.08 |
| Windows Powershell로 긴 명령어를 짧게 만드는 function 함수 사용 (0) | 2022.05.12 |
| Cannot Run Git 오류 발생시 해결 방법(PyCharm, AndroidStudio, Intellij IDEA) (0) | 2022.01.07 |
설정
트랙백
댓글
글
추운 겨울 한적한 마을에 역이 다시 들어서다 - 경의선 운천역[2022.12.18]
지난 2019년 10월 2일 열차가 정차하였던 경의선 운천역이 통근열차가 폐지된 이후 운행되던 DMZ트레인의 운행이 사실상 종료되면서 사실상 역으로서의 기능을 상실하였습니다. 심지어 전동열차가 임진강역으로 연장됨에도 불구하고 중간역이었던 운천역이 배제됨으로서 폐역 수순에 들어갈 것 처럼 보였습니다.
하지만 인근 주민들의 항의와 동시에 전동열차 정차 요구 등 지속적인 요청들이 지속되었고 결국 운천역에서 전동열차를 사용할 수 있도록 역을 개량하기로 결정되었습니다.
그러나 사실상 운천역이 임시승강장 형식으로 지어진 역이어서 기차를 탈 수 있는 저상승강장 구조였기 때문에 고상홈을 사용하는 전동열차에 대응하기 위해 사실상 신축을 해야 하는 상황이었습니다. 다만, 최근에 지어지는 전철역이 아무리 깡촌이어도 으리으리하게 짓던 관행이 있어 주변 인구가 희박한 운천리 일대에 역을 짓는다는 것이 수요에 비해 예산만 과다하게 쓴 안좋은 사례가 되지 않을까 저는 우려스러운 관점이 없지 않아 있었습니다.
그렇게 2022년 12월 17일 운천역이 다시 개통되어 승객을 맞이하게 되었습니다. 다행히도 지금까지 터무니없이 거대한 역사를 짓던 사례들과는 이례적으로 운천역은 전동열차 전용의 아담한 간이역으로 지어졌습니다.
2022년 12월 18일 아침기온이 무려 -17도까지 떨어진 한파를 뚫고 운천역에 다녀와보았습니다.

문산 - 임진강 구간을 운행하는 전동열차에 탑승합니다.
날씨가 워낙 추워서인지 마지막칸 맨 끝 출입문만 개방한 상황이었습니다.

운천역으로 운행하는 열차에는 단 6명의 승객만이 타고 있었습니다.

문산역을 출발한 전동열차가 운천역에 도착하였습니다.

승강장의 끝에는 과거 임시승강장 시절 운천역의 흔적이 고스란히 남아있었습니다.

놀랍게도 운천역 승강장의 전체 모습이 사진 한 장에 다 들어옵니다.

나름 동네의 큰 이벤트이다 보니 마을 사람들이 화환을 갖다두었습니다.

같은 플랫폼에서 정 반대 방면의 행선지가 걸려있다는 것이 신기하군요

이촌역에서도 승강장 끝에서 건널목을 볼 수 있었지요?

작은 역에 갖출건 다 갖추고 있었습니다.

역에서 나오자마자 바로 출구입니다.

심지어 타는곳에서도 역 내부를 다 볼 수 있습니다.

이용 주민은 얼마 되지 않겠지만 그래도 주차장도 갖추고 있었습니다.

심지어 개통 전날에는 준공식도 진행했군요

작은 역이지만 무려 대기실도 갖추고 있습니다!

적어도 전철역으로서 갖추어야할 시설들은 모두 있는 것 같네요

승차권 사는 곳 이라는 표현이 흡사 기차역에 온 듯한 기분입니다.

이 추운날 화장실이 훨씬 따뜻한 듯 합니다


폴사인 바로 옆에는 경쟁상대인 버스정류장과 함께 있습니다.

워낙 작은 동네이다 보니 열차 한 편이라도 탈 수 있는 것 만으로도 상당히 큰 차이가 나는듯합니다.

과연 운천역의 주차장이 만차가 되는 날이 있을까요?

뭔가 역을 아담하게 만든 모습이 기존 역과 차이가 나다 보니

역명판만 없었다면 단지 건물만 세워진 신호장처럼 보이기도 합니다.

과연 운천역의 미래는 어떤 모습일까요?

사실 가장 우려스러운 점은 열차가 평일에는 왕복 2회, 주말에는 왕복 4회가 전부입니다.

한때 평일에 4회만 운행하였던 지평역이 지금은 6회나 운영하고 있습니다만
과연 운천역은 몇 명이 찾아오는 역이 될까요?

너무나도 추운 날씨에 차가워진 몸을 급히 열차에 태워 다시 문산역으로 돌아갑니다.
'좌충우돌 여행기 > 국내여행' 카테고리의 다른 글
| 열차가 멈추지 않는 정원속 간이역 - 경전전 남평역[2022.06.01] (0) | 2022.06.14 |
|---|---|
| 도심속 꼬마열차가 다니는 작은 간이역 - 광주선 극락강역[2022.06.01] (0) | 2022.06.11 |
| 석탑, 금성(탑리)버스터미널, 그리고 탑리역[2022.03.26] (1) | 2022.04.06 |
| 한적한 마을에 열차가 머물다 가는곳 - 중앙선 신녕역[2022.03.27] (0) | 2022.03.30 |
| KTX-이음을 타고 중부내륙선을 달리다 - 부발역 ~ 충주역[2022.01.01] (0) | 2022.01.11 |
설정
트랙백
댓글
글
vscode에서 Java 클래스 경로 추가하는 방법
Eclipse로 설계된 Java를 Pycharm이나 vscode로 실행하다 보면 기존의 Class 경로 설정이 맞지 않아 분명 같은 패키지 안에 있는 파일이 인식되지 않는 문제를 최근 경험하곤 합니다.
vscode에서 path를 설정하는 방법이 있는지 열심히 찾아보니 그냥 프로젝트 내에 있는 파일인 '.classpath'를 수정하면 된다는군요.
일단 .classpath가 목록에 보이지 않는 분께서는 아래 주소를 통해 .classpath를 찾아보도록 합니다.
https://hyunchang88.tistory.com/320
[ vscode ] .classpath가 안보일때 보이게 하는 방법
vscode를 사용한지 얼마 안되어서 검색을 해봤는데 .classpath 에서 뭔가를 수정하라고 해서 수정하려고 보니 .classpath가 안보임... 여기 있던데 왜 안보임?????? 맥북이라 익숙하지도 않고 툴도 처음써
hyunchang88.tistory.com
다음으로 '.classpath' 파일에 자신이 추가하고자 하는 경로를 다음과 같이 추가합니다.
<classpathentry kind="src" path="추가하고자 하는 경로"/>
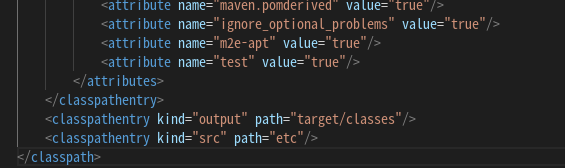
위와 같이 추가하면 vscode에서 Java를 Run 하였을 때 추가한 경로가 인식되는 것을 확인하실 수 있습니다.
'공대생의 팁' 카테고리의 다른 글
| 웹사이트(브금저장소)에서 재생되는 배경음악을 다운로드 하는 방법 (0) | 2023.01.24 |
|---|---|
| Windows에서 scann 라이브러리 설치하기 (0) | 2023.01.05 |
| Windows Powershell로 긴 명령어를 짧게 만드는 function 함수 사용 (0) | 2022.05.12 |
| Cannot Run Git 오류 발생시 해결 방법(PyCharm, AndroidStudio, Intellij IDEA) (0) | 2022.01.07 |
| VMware Android x86을 안드로이드 스튜디오 디버깅 환경으로 연결하여 사용하는 방법 (0) | 2021.12.31 |
설정
트랙백
댓글
글
복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기
업무 목적으로 EsperTech사의 Esper를 개발하게 되면서 오랜만에 Java를 사용하게 되었습니다. 학생때 Android 프로그래밍을 하면서 Java를 애용했던 기억이 있고, 그 당시 안드로이드 애플리케이션 개발을 열정적으로 했던 경험이 생생합니다.
어느샌가 안드로이드 앱 개발 환경은 Kotlin으로 재편되면서 자바의 입지는 예전보다 줄어든 경향이 있어보입니다. 그러나 운영체제와 상관 없이 자바 가상머신(JVM)만 설치되어 있으면 그 어떤 기기에서도 Java를 사용할 수 있다는 매력 만큼은 무시할 수 없기에 Java는 2022년 현재에도 애용되는 언어입니다. Espertech의 Esper는 Java로 설계되어 있으며 그 덕에 운영체제를 가리지 않고 손쉽게 사용할 수 있다는 점은 개발자의 관점에서는 편하다고 할 수 있지요.

Espertech사의 esper는 복합 이벤트 처리(Complex Event Processing)를 위한 라이브러리로, 영상, 센서 등에서 복합적으로 발생하는 데이터를 수신하여 이벤트가 발생하였을 때, 각 센서에서 수신되는 데이터 값을 esper가 수신하였을 때 각 센서의 값들을 복합적으로 판단하여 해당 이벤트의 속성을 분석하여 이를 올바르게 판단하는 것을 목표료 합니다.
예를 들어, 공사 현장에 카메라와 마이크가 설치되어 있을 때, 현장에서 작업자가 쓰러지는 모습과 그 과정에서 발생하는 소음들을 카메라와 마이크가 해당 영상 및 소리를 데이터화 하여 esper에 전달하였을 때, esper는 이 이벤트를 위급한 상황이라 판단하고 이를 조치하기 위한 요청을 발생하는 것을 목표로 한다고 생각하시면 되겠습니다.

복합 이벤트 처리 라이브러리인 esper를 Visual Studio code에서 실행해보도록 합니다. 먼저 esper 공식사이트 혹은 공식 github 사이트를 통해 esper 라이브러리를 다운로드 받습니다.
https://www.espertech.com/esper/esper-downloads/
Downloads - EsperTech
Esper is distributed in several packaged formats for your convenience. […]
www.espertech.com
https://github.com/espertechinc/esper
GitHub - espertechinc/esper: Esper Complex Event Processing, Streaming SQL and Event Series Analysis
Esper Complex Event Processing, Streaming SQL and Event Series Analysis - GitHub - espertechinc/esper: Esper Complex Event Processing, Streaming SQL and Event Series Analysis
github.com
다음으로 자신이 esper를 사용하고자 하는 환경에 맞추어 Java, Maven, Visual Studio Code를 설치합니다.
VS Code를 설치한 다음 확장 탭에서 Debugger for Java를 설치해주세요.

이어서 EsperEPL 확장 프로그램을 추가로 설치합니다.

다음으로 설정 탭에서 Maven for Java 탭을 선택한 후 Maven > Executable: Path 메뉴에서 설치된 maven의 bin 경로를 입력해줍니다.
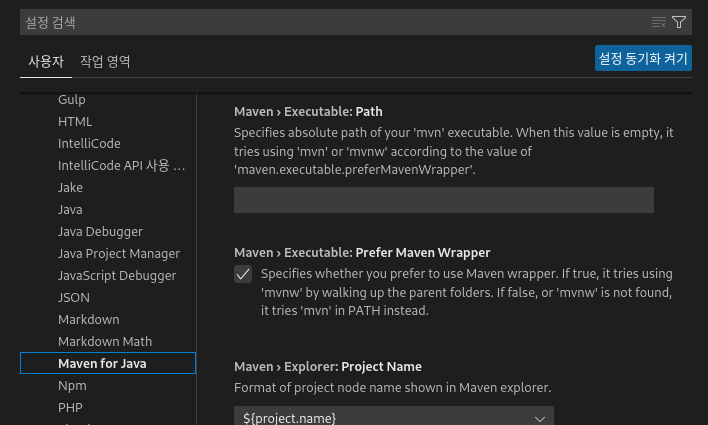
다음으로 esper 소스의 example 폴더를 엽니다.

이제 Example 소스코드들을 컴파일 해봅니다. test모드를 적용하기 위해 탐색기의 maven 탭에서 Lifecycle > test-compile 버튼을 클릭하여 아래와 같이 예제 코드가 컴파일 되는 것을 확인합니다.

이제 컴파일된 esper 예제 코드를 실행해봅니다. Ctrl+F5를 누르면 실행하고자 하는 메인함수를 선택할 수 있으며 선택된 예제 코드가 실행되는 것을 확인하실 수 있습니다.

'프로그래밍 팁' 카테고리의 다른 글
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
|---|---|
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
| IP 주소를 통해 위치 정보 얻기(IP-API.com) (0) | 2016.11.09 |
설정
트랙백
댓글
글
P2P 투자 법인 설립 후기(1) - 설립 준비 전 고려할 사항들
지난 2020년 코로나19 바이러스가 전세계를 휩쓸면서 각국의 증시가 폭락하는 유래없는 사태가 있었고, 각 국가들은 경제 회복을 위한 양적완화 정책으로 시장에 많은 돈이 풀리면서 주식 및 부동산 가치가 폭등하였고, 이 시기동안 사람들은 흔치 않는 수익 창출을 경험할 수 있었습니다.
그러나 과도하게 시장에 풀린 돈으로 인하여 돈의 가치는 낮아지고 과격한 인플레이션의 압박으로 물가가 무섭게 오르고 있습니다. 심지어 전 세계가 미국의 금리 정책에 주목하고 있을 정도로 대출 이자마저 감당할 수 없을 만큼 늘어가고 있는 상황인데다 러시아-우크라이나 전쟁으로 촉발된 식량난은 차후 몇년간은 증시 전망이 밝지만은 않습니다.

물론 금리 인상으로 2022년 9월 기준 저축은행 최고 예금 이자는 약 4%까지 올랐습니다. 하지만 요새 8%에 이르는 물가 상승률에 비해서는 크게 매력적이지만은 않습니다. 물론 경기 침체로 인해 현재와 같이 주식시장이 횡보하는 상황에서는 좀 더 안정적인 예금도 나쁜 선택은 아닙니다. 다만 현재의 상황에서 좀 더 매력적인 금융상품에 과감하게 투자를 하고 싶지만 결코 쉽지만은 않은 상황이지요.
그러던 도중 마침 제가 투자하고 있던 P2P(온라인대출정보연계대부업) 법인 회원으로 수익을 내는 방법이 생각났습니다. 뭔가 투자회사의 대표가 되어 자산가가 될 수 있는 로망(?)에 빠져 상당히 많은 고민을 하였고 비록 소자본으로 큰 돈은 못벌지만 차후 창업을 하게 되었을 때의 과정들을 미리 경험해보고자 겁도 없이 투자 법인을 만들어보자는 생각해보았습니다.
지난 2021년 8월 27일 온라인투자연계금융업이 법의 테두리에 들어오게 되면서 P2P 투자업을 하는 업체들은 금융위원회에 등록신고를 하여 심사를 거쳐 승인을 받아야 영업을 영위할 수 있게 되었습니다. 그 덕분에 어느 정도 부실했던 업체들이 정리될 수 있는 장점이 있었으나 투자 한도가 업계 통합 3천만원으로 제한되면서 개인 회원은 많은 투자를 할 수 없게 되었습니다. 비록 투자자를 위한 안전장치로서 피해를 줄이고자 투자금액을 제한한 것은 충분히 이해되지만 더 많은 금액을 투자하고 싶은 투자자의 경우 썩 좋지만은 않은 상황입니다.
법인 투자자의 경우 투자금액의 제한은 없지만 이자 수익을 가져오는 것이 까다롭습니다. 비록 자신이 100% 지분을 소유한 법인이라 하더라도 법인은 개인과 별개의 인격체로서 법인 자산을 맘대로 썼다가는 가산세 및 가지급금(개인이 법인으로부터 빌린돈) 취급으로 법정 이자를 물어야 하는데다가 이에 대한 소득세까지 물어야 합니다.
법인 설립에 들어가기에 앞서 법인 설립시 내가 벌 수 있는 돈이 얼마인지 미리 가늠해보도록 하겠습니다.
※여기서 제시하는 예시는 세금을 가장 많이 떼는 상황을 가정한 것으로 법인 운영 방식에 따라 차이가 있음을 알립니다 P2P 법인 설립과 관련된 내용은 아래 사이트를 참조하였습니다..
※무제한 한도 P2P투자를 위한 법인 설립 및 운영 매뉴얼
1. 투자 수익 알아보기
비금융 법인사업자가 연 10% 상품에 투자하였을 경우
만약 이자 수익 10%인 상품에 투자한다고 가정해봅니다. 해당 상품을 제공하는 P2P 업체에서 가져가는 플랫폼 수수료가 1.2%라 하였을 때, 금융업을 하지 않는 법인 사업자의 경우 이자 수익의 27.5%(국세 25% + 지방세 2.5%)를 세금으로 원천징수 됩니다. 이 법인이 해당 상품에 100만원을 투자하였을 경우 1년후 예상 수익은 아래와 같습니다.
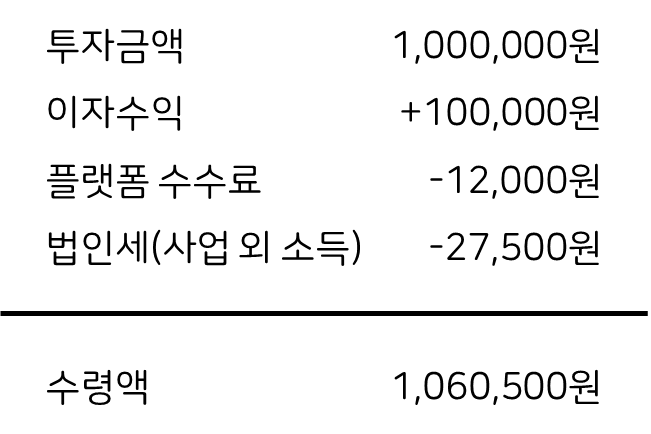
물론 법인으로부터 개인이 수익을 가져오기 위해서는 급여로 지급받거나 주식 배당금으로서 비로소 수익 실현을 할 수 있습니다. 아래의 경우 위의 과정을 통해 얻은 이자수익을 배당으로 개인이 가져가게 될 경우 원천징수 세금 27.5%가 적용되어 순수익은 아래와 같습니다.

즉, 금융업이 아닌 법인의 경우 예상 순수익은 약 4.3%로 예상할 수 있습니다.
금융업 법인사업자가 연 10% 상품에 투자하였을 경우
반면, 금융업을 영위하는 법인사업자의 경우 이자 수익이 영업자금이므로 법인세를 10%만 내면 됩니다. 이 경우 1년 후 수령금액은 다음과 같습니다.

법인사업자로부터 배당을 받게 될 경우 27.5%의 세금을 원천징수하면 순수익은 다음과 같습니다.

기대 순수익은 약 5.6%로 금융업으로 얻을 수 있는 수익이 다소 높음을 알 수 있습니다.
2. 법인 설립하기
앞에서 설명드린 수익률만 보았을 땐 그래도 시중은행 이자보다 높은 편이고 절세 전략으로 더 많은 수익을 기대할 수 있으리라 생각할 수 있지만 법인 설립 및 운영에 지출되는 비용 또한 철저히 고려하셔야 합니다. 투자 금액이 무제한인 법인이라 할지라도 설립 및 운영 과정에서 지출되는 비용을 감당할 수 없다면 투자를 안하느니만 못하겠지요?
여기서는 간단하게 법인 설립 방법 및 비용에 대해 설명드리겠습니다. 법인 설립 방법 등은 첨부 링크를 통해 확인하시길 바랍니다.
스스로 법인 설립하기
법인설립 절차 및 셀프로 진행하기
우리나라에서 사업을 하시는 사업자의 종류는 크게 개인사업자와 법인사업자로 나눕니다. 개인사업자로 사업을 시작하시다가, 법인사업자로 전환을 하시는 분들이 계시고, 바로
run2plan.kr
법인설립 대행
등기24 - 법인설립 간소화 서비스
법인설립 절차 5분이면 충분 합니다. 무방문 무서류 법인등기. 법인설립 비용 65% 절감. 월 20,675명 사업자가 이용하고 있습니다.
deungi24.com
개인이 직접 셀프 법인 설립을 진행하는 경우가 제일 저렴하나 처음으로 법인을 설립하시는 경우 법인설립을 도와주는 사이트를 통해 도움을 받으시길 권장드립니다. 법인 설립 비용은 자본금 및 설립 장소 소재지에 따라 약 20만원 ~ 800만원의 공과금을 납부하여야 합니다.
3. 법인 운영하기
법인을 설립하고 사업자등록까지 마치셨다면 이제 법인을 운영하면서 발생하는 경우에 대해 살펴보도록 하겠습니다.
먼저 사업자등록이 가능한 사무실을 구하여야 합니다. 만약 개인이 이미 사업장을 갖고 있거나 자신의 자택에서 사업자등록이 가능한 업종의 경우 추가적인 비용이 발생하지 않으나 특정 업종의 경우 회사의 간판이 드러나있는 등의 조건이 갖추지 않을 경우 은행에서 실사 확인후 개설이 거절당할 수 있습니다. 비상주 사무실을 구하여 장소 임대만 하는 경우 실제 해당 장소에 사무실이 갖추어지지 않을 경우 사업자등록이 취소될 수 있으므로 제대로 된 사무실이 갖추어진 사업장을 구하여아 합니다. 비상주사무실로 법인을 운영할 경우 1년에 약 60만원 정도의 비용을 고려하시면 좋을 듯 합니다.
또한, 법인사업자의 경우 법인세 신고를 위해 장부(기업의 가계부)를 작성하여야 합니다. 국세청에 신고하기 위해서는 양식을 갖춘 장부를 작성하여야 하나 세무 분야에 대한 지식 없이 장부를 운영할 경우 국세청에서 무기장 가산세를 추가 부과할 수 있습니다.
법인 장부 작성을 위해 세무사에게 기장을 맡길 경우 법인 투자가 의미없을 정도로 인건비가 지출됩니다. 인터넷을 통해 기장을 작성할 수 있는 사이트를 적극적으로 사용하여 장부작성 비용을 최소화 합니다. 아래 소개드리는 사이트를 통해 1년에 22만원으로 장부 작성을 하실 수 있습니다.
디지택스 - 간편장부, 복식부기, 부가세, 소득세, 법인세, 원천징수신고, 자동장부, 전자장부, 인
dztax.com
또한, 1인 법인 사업자로 P2P 투자로만 수익을 창출하는 경우 성실신고 확인제도가 적용되며 이 경우 외부조정 수수료(최저 55만원~)에 성실신고확인수수료(최저 165만원~)가 부가됩니다. 여기서 성실신고확인수수료의 경우 60%가 세액공제 되어 실제 부담하는 수수료는 훨씬 적어지지만, 투자 금액의 규모에 따라 실제 부담하는 수수료가 달라질 수 있습니다.

지금까지 설명드린 비용들을 합산하였을 때, 법인을 운영할 때 발생하는 비용은 최소 약 300만원 이상 지출될 것으로 예상되며 세액공제 등을 고려하였을 때, 약 3500만원 이상을 투자해야 본전이라는 예상을 할 수 있습니다. 2022년 9월 기준 시중은행 예금 이자가 3.6%임을 고려하였을 때, 약 1억2천만원 이상을 투자하였을 경우 시중은행에 가입한 이자 이상의 수익을 기대할 수 있을 것으로 예상할 수 있습니다..
결론:
1. 기존의 법인 사업을 하고 계신 분이거나 2억 이상의 자본을 갖고 계신 분이 아니라면 차라리 예금 투자를 하시는 것이 속편하실 수 있습니다.
2. 만약 법인을 만들고 싶으시다면 처음부터 금융업이 아닌 다른 업종으로 설립하시고 시작하시길 바랍니다. 금융업 사업자가 법인통장 만드는게 너무 어렵습니다.
3. P2P 상품들은 원금을 절대로 보장하지 않습니다! 반드시 목돈 굴리는 목적으로 투자하시길 권고드립니다.
참고자료: https://campusfund.net/corp_convert_guide
'흔치않은일상' 카테고리의 다른 글
| 게임큐브 컨트롤러를 PC에 연결해 Dolphin 에뮬레이터에서 사용해보기 (0) | 2024.04.07 |
|---|---|
| P2P 투자 법인 설립 후기(2) - 1년반만에 폐업합니다 (0) | 2023.12.30 |
| 누적방문객수 100만명 돌파했습니다! (0) | 2022.05.30 |
| 코로나19와의 사투(3) - 5일만에 퇴원하다 (0) | 2022.03.19 |
| 코로나19와의 사투(2) - 퇴소 그리고 입원 (0) | 2022.03.13 |
설정
트랙백
댓글
글
VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기
Visual Studio code를 사용함에 있어 가장 큰 강점은 확장(Extension) 기능을 설치하여 단지 소스코드를 열람하거나 수정하는 것에서 끝나는 것이 아니라 C++, Java, Python 등 자신이 사용하고자 하는 언어를 컴파일 하고 실행까지 직접 해볼 수 있다는 점입니다.
그렇기에 저의 경우 프로그래밍을 하고자 할 때 해당 환경이 VScode에서 지원이 되는지를 먼저 확인하고 결정하는데 중요한 역할을 합니다. 심지어는 SSH를 지원하여 원격 환경에 있는 서버에 접속해 마치 자신의 컴퓨터에서 작업을 하는 것과 같이 편하게 프로그래밍을 진행할 수 있다는 점이 좋습니다.
특히 SSH 환경에서도 확장 기능을 사용할 수 있어 SSH 접속을 통해 원격 서버에 확장을 설치하면 Local에서 사용하는 것과 같이 프로그래밍을 할 수 있는데요. 이번에는 희안하게도 설정이 제대로 되지 않았는지 원격 서버에 확장 설치를 시도하려 하였으나 아래와 같은 에러가 발생하며 더이상 진행이 되지 않는 현상이 발생했습니다.
This extension is disabled in this workspace because it is defined to run in the Remote Extension Host.
이 확장은 원격 확장 호스트에서 실행되도록 정의되었기 때문에 이 작업 영역에서 사용하지 않도록 설정되어 있습니다.

정황상 모종의 사유로 인하여 원격 컴퓨터에 vscode 확장 설치가 진행되지 못한 것으로 추측됩니다. 이 경우 확장 프로그램을 서버에 직접 설치하여 문제를 해결해봅니다.
먼저 자신이 설치하고자 하는 vscode 확장 프로그램을 visual studio makret place에서 검색하신 다음 직접 다운로드 받도록 합니다.
Visual Studio Marketplace
Extensions for Visual Studio family of products on Visual Studio Marketplace
marketplace.visualstudio.com
위 링크의 웹사이트에 접속하신 다음 Visual Studio Code 탭을 선택한 다음 검색창에 자신이 원하는 확장 프로그램의 이름을 입력후 검색합니다.
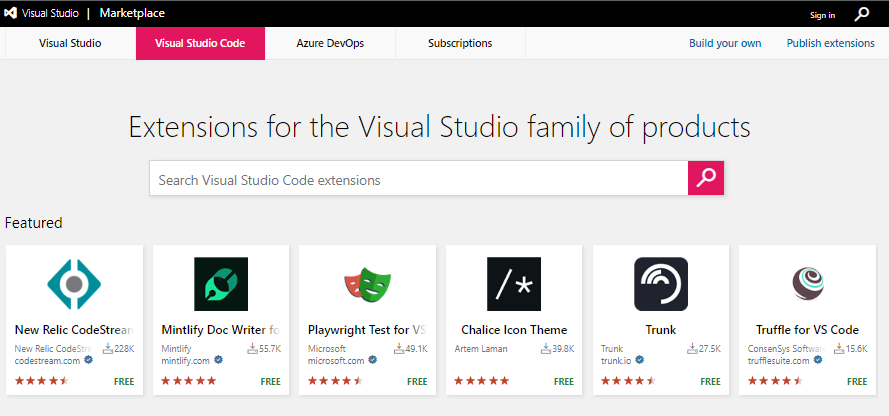
원하시는 확장 프로그램을 찾으신 다음 해당 페이지 우측에서 'Download Extension'을 클릭하여 확장 프로그램을 다운로드 받습니다.

다운로드를 완료하시면 확장명 .vsix인 설치 파일이 다운로드 된 것을 확인하실 수 있습니다.
다시 vscode를 실행한 다음 소스코드가 저장되어 있는 서버에 ssh 원격 접속하여 다운로드 받은 .vsix 파일을 서버에 전송하신 다음 vscode의 extension 탭에서 아래의 그림과 같이 클릭한 다음 'install from VSIX...' 버튼을 클릭합니다
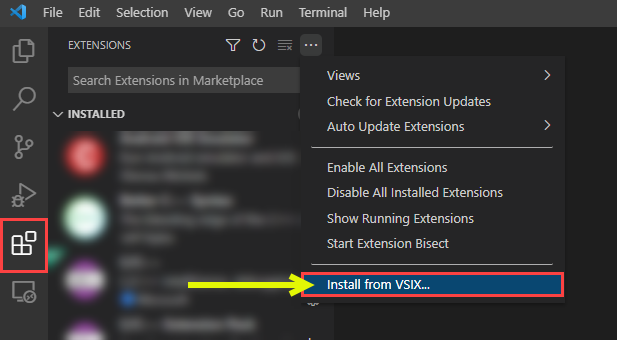
그 다음 .vsix를 저장한 폴더의 위치로 이동한 다음 .vsix를 선택하여 설치를 진행하면 서버에 확장 프로그램이 설치된 것을 확인하실 수 있습니다.
'프로그래밍 팁' 카테고리의 다른 글
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
|---|---|
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| Anaconda 사설 로컬 저장소 채널 만들기 (9) | 2022.07.27 |
| IP 주소를 통해 위치 정보 얻기(IP-API.com) (0) | 2016.11.09 |
| Fedora에 이전 버전의 OpenJDK 설치하기(Install OpenJDK 7 in Fedora 23) (0) | 2015.12.22 |
