검색결과 리스트
분류 전체보기에 해당되는 글 440건
- 2024.04.07 게임큐브 컨트롤러를 PC에 연결해 Dolphin 에뮬레이터에서 사용해보기
- 2024.03.31 [mmcv] AssertionError: only one of size and size_divisor should be valid
- 2024.03.26 LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법
- 2024.02.25 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg
- 2024.01.31 MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기
- 2023.12.30 P2P 투자 법인 설립 후기(2) - 1년반만에 폐업합니다
- 2023.11.05 MMCV에서 사용되는 pretrained model 주소 알아내는 방법
- 2023.10.31 Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++)
- 2023.09.10 Android에서 Glib 사용하기(NDK)
- 2023.08.12 PowerShell에서 Visual Studio x64 환경으로 개발하기
- 2023.07.29 Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법
- 2023.06.24 MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
글
게임큐브 컨트롤러를 PC에 연결해 Dolphin 에뮬레이터에서 사용해보기
얼마전 Aliexpress에서 게임큐브 컨트롤러와 PC에 연결하여 사용할 수 있게 해주는 어댑터를 구매했습니다. 본래 일본에 방문했을 때 게임샵에서 구매하려 했습니다만, 발매된지 20년이 지난 게임큐브임에도 중고 컨트롤러 가격이 3천엔이며, 심지어 닌텐도 스위치에 연결하여 사용할 수 있는 컨트롤러 어댑터도 정품은 우리나라 돈으로 10만원이 넘는 가격이어서 감히 살 엄두가 나지 않았는데, Ailexpress에서 개당 5천원에 판매하고 있어 망설임 없이 구매하였습니다.
이번에 구매한 GameCube Controllers Adapter는 품명 FY-L-1208 인 제품으로, Aliexpress에서 개당 7천원에 구매하였습니다. 정품 가격을 생각하면 이 가격에 구매한 것이 살짝 믿어지지 않아 혹시나 싼게 비지떡인 상황이 발생하지 않을까 걱정이 되기도 했습니다.

둘다 닌텐도 정품은 아니지만 품질은 생각보다 정품과 비슷했습니다. 흡사 외관상 정품로고만 없는 정품같아 보이기도 합니다. 싼 맛에 Aliexpress에서 구매한다지만 이정도면 가성비가 상당히 좋아보입니다.
지금 당장은 닌텐도 스위치를 구매하지 않은 상황이어서 PC에 돌핀 에뮬레이터를 설치하고 한 번 플레이 해보고자 컨트롤러 어댑터를 PC모드로 한 다음 PC에 연결하였습니다.

컴퓨터 설정 메뉴에서 장치를 확인하였을 때 기타 디바이스로 'WUP-028'로 나타나 정상적으로 설치가 된 것으로 보였습니다.
게임을 플레이하기에 앞서 구매한 게임큐브 컨트롤러가 정상적으로 동작을 확인하기 위해 관련 설정에서 '장치 및 프린터'를 클릭합니다.

장치 및 프린터에서 'WUP-0228' 장치를 확인 후 우클릭 하여 '게임 컨트롤러 설정'을 클릭해주시면

아래와 같이 게임 컨트롤러 설정창이 나타납니다.
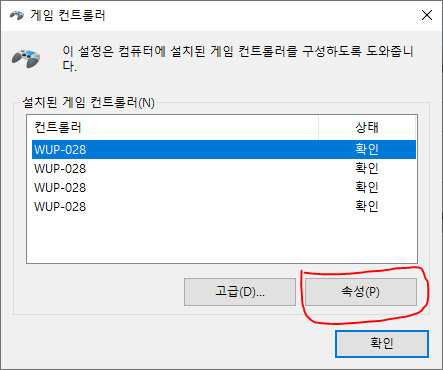
4개의 컨트롤러는 각각 1P에서 부터 4P까지 나타내는 것으로, 자신이 연결한 컨트롤러를 클릭해주시면 컨트롤러가 정상적으로 동작하는지 확인하실 수 있습니다.
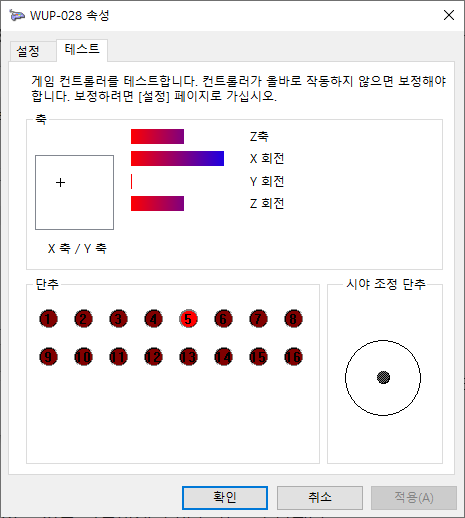
위의 방법을 통해 Aliexpress에서 구매한 게임큐브 컨트롤러 및 어댑터가 정상적으로 동작하는 것을 확인하였습니다. 그런데 이상하게도 돌핀 에뮬레이터에서는 게임큐브 컨트롤러를 인식하지 못하고 있는 것이었습니다.
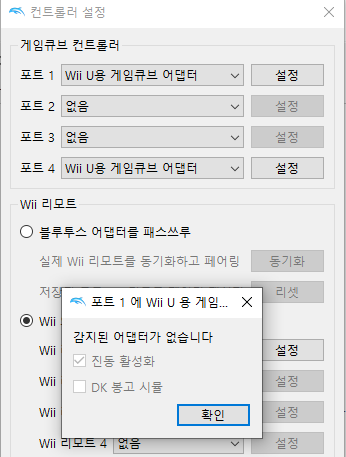
확인해보니 Dolphin 에뮬레이터에서 게임큐브 컨트롤러 어댑터를 통해 조작이 가능함을 확인할 수 있었는데, Windows 환경에서는 USB 설정을 변경해서 사용할 수 있다고 합니다. 이번에 제가 구매하였던 어댑터같은 경우, 어댑터 모드를 PC모드와 Wii U(닌텐도 스위치)모드를 스위치로 설정할 수 있도록 구성되어 있는데, Dolphin 에뮬레이터에서 사용하기 위해서는 PC모드가 아닌 Wii U(닌텐도 스위치) 모드로 설정해서 연결한 다음, USB 드라이버를 변경해주면 된다고 합니다.
앞에서 진행하였을 때 설치하였던 'WUP-028' 장치를 우클릭하여 '장치 제거'를 해주신 후 어댑터의 스위치를 Wii U(닌텐도 스위치) 모드로 변경후 다시 연결해주시면

위의 그림처럼 지정되지 않은 드라이버로 나타나는 것을 확인하실 수 있습니다. 드라이버의 설정을 변경하기 위해 아래의 Zadig을 다운로드하여 실행해줍니다.
Zadig - USB driver installation made easy
Zadig USB driver installation made easy Zadig is a Windows application that installs generic USB drivers, such as WinUSB, libusb-win32/libusb0.sys or libusbK, to help you access USB devices. It can be especially useful for cases where: you want to access
zadig.akeo.ie
Zadig를 다운로드 후 실행하면 아래와 같은 화면이 나오는 것을 확인하실 수 있습니다.
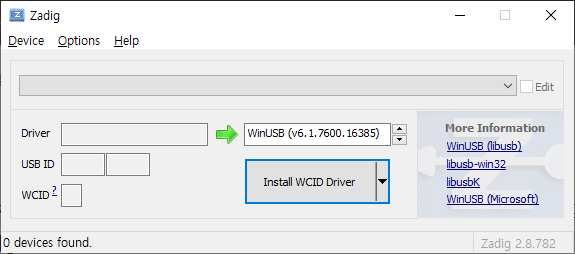
Option → List All Device를 선택하여 PC에 연결된 USB 기기들의 리스트를 모두 확인합니다.
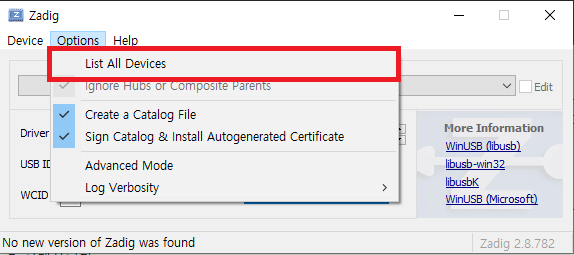
List에서 게임큐브 컨트롤러 어댑터 기기명인 'WUP-028'을 선택하신 다음, USB ID가 057E 0037인지 확인해줍니다. 만약 목록에 'WUP-028'이 나타나지 않을 경우, USB를 다른 포트에 연결해봅니다.
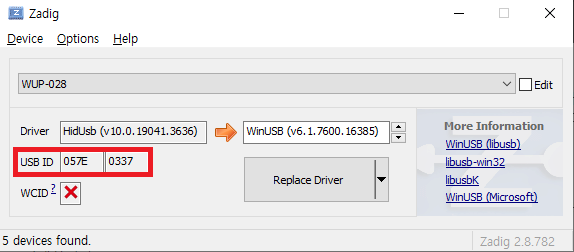
확인하셨다면, WinUSB를 선택한 다음 Replace Driver를 선택합니다.
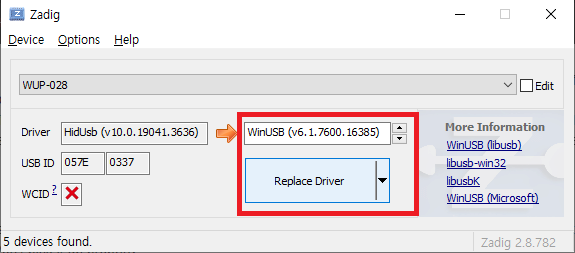
아래와 같이 Warning - System Driver 경고문이 나타나면 '예(Y)'를 클릭해줍니다.
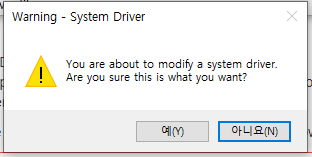
아래와 같은 화면이 나오고 약 5분 정도 기다려주시면
아래와 같이 설치가 완료된 것을 확인하실 수 있습니다.
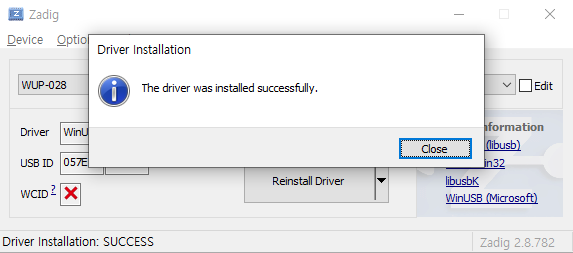
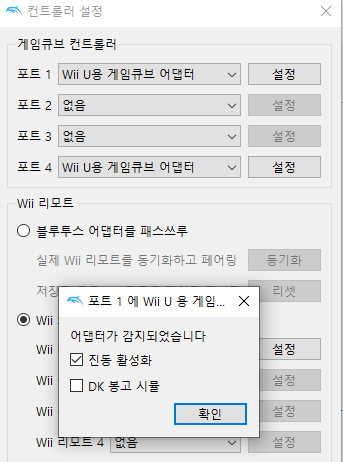
다시 Dolphin 에뮬레이터를 켠 다음 컨트롤러 설정에서 포트를 'Wii U용 게임큐브 어댑터'로 설정 후 '설정' 버튼을 클릭하시면 '어댑터가 감지되었습니다'가 표시됨을 확인하실 수 있습니다.
참고자료: https://ko.dolphin-emu.org/docs/guides/how-use-official-gc-controller-adapter-wii-u
돌핀 에뮬레이터 - How to use the Official GameCube Controller Adapter for Wii U in Dolphin
Official GameCube Controller Adapter for Wii U As of 4.0-4599, Dolphin has built in support for Nintendo's GameCube controller adapters for the Wii U and Switch, the only official USB GameCube adapters available. With Dolphin's implementation, the GameCube
ko.dolphin-emu.org
'흔치않은일상' 카테고리의 다른 글
| P2P 투자 법인 설립 후기(2) - 1년반만에 폐업합니다 (0) | 2023.12.30 |
|---|---|
| P2P 투자 법인 설립 후기(1) - 설립 준비 전 고려할 사항들 (1) | 2022.09.20 |
| 누적방문객수 100만명 돌파했습니다! (0) | 2022.05.30 |
| 코로나19와의 사투(3) - 5일만에 퇴원하다 (0) | 2022.03.19 |
| 코로나19와의 사투(2) - 퇴소 그리고 입원 (0) | 2022.03.13 |
설정
트랙백
댓글
글
[mmcv] AssertionError: only one of size and size_divisor should be valid
MMSegmentation으로 딥러닝 모델을 실행하는 과정에서 종종 아래와 같은 에러를 접하곤 합니다.
assert (size is not None) ^ (size_divisor is not None),
AssertionError: only one of size and size_divisor should be valid
MMSegmentation github 사이트에서 관련 이슈로 등록된 글을 통해 확인해본 결과, data_preprocessor에서 size 혹은 size_divisor가 설정되어 있지 않아 발생하는 오류라고 합니다. 아래와 같이 data_preprocessor에 size를 추가 설정해주니 소스코드가 정상적으로 동작하는 것을 확인하였습니다.
crop_size = (512, 512)
data_preprocessor = dict(
# ....
size=crop_size)
참고자료: https://github.com/open-mmlab/mmsegmentation/issues/3425
AssertionError: only one of size and size_divisor should be valid · Issue #3425 · open-mmlab/mmsegmentation
I am trying to use mmsegmentation for segmentation of pathology images on my own new dataset. I have 512x512 patches of images and annotations. I am representing four classes of my new dataset as g...
github.com
'공대생의 팁' 카테고리의 다른 글
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법
요새 Dataset Lebeling 작업을 수행하는 과정에서 다양한 방식의 Label 구조 형식들을 접해보고 있습니다. Bounding Box 방식과 같이 단지 마우스 2번의 클릭으로 끝나는 경우가 있는가 하면, Polygon 방식과 같이 사진 내에 있는 모든 Object의 테두리에 점을 하나하나 공들여서 표시해보기도 합니다. Labeling 작업에 왕도는 없지만, 좀 더 데이터를 다루는 것에 초점을 맞추어 데이터의 속성을 이해하여 좀 더 적합한 모델을 찾는데 도움이 되기도 합니다.
2024년 현재도 좋은 AI 모델이 소개되고는 있지만 정제되지 않은 데이터로는 좋은 성능의 AI 모델을 구현할 수 없습니다. 비록 데이터셋 제작에 많은 시간이 소모되더라도 결국은 데이터셋의 품질이 AI모델의 성능을 좌우하는 데엔 그 누구도 이견이 없을 것입니다.
평소와 다름없이 LabelMe로 Labeling한 JSON 파일들을 Coco Dataset으로 변환한 다음, MMDetection으로 모델을 학습시키려 하는 과정에서 다음과 같은 에러를 접하게 되었습니다.
ValueError: need at least one array to concatenate
해당 오류의 원인을 찾아보니 MMDetection에서 원본 coco 데이터셋의 category를 기준으로 설정되어 있어서 우리들이 직접 만든 custom coco dataset의 class명이 원본 coco 데이터셋의 class명과 다를 경우 위와 같은 오류가 나타나는 것이었습니다. 이 문제는 LabelMe로 만든 coco 데이터셋의 class명을 원본 coco 데이터셋과 일치시키면 바로 해결됩니다.
비록 학습시에는 원본 coco 데이터셋의 class명이 출력되시만, 모델 Deploy 수행시 class명을 변경해서 사용할 수 있기 때문에, 학습이 진행되는 동안 출력되는 class명이 다르게 되는 불편함을 감수하실 수 있다면 아래의 소스코드를 다운로드 받은 다음 LabelMe로 작업한 JSON 파일을 변환하여 사용해보시기 바랍니다.
If you get an error like the one above when training mmdetecton on a coco dataset that you converted to LabelMe, download labelme2coco.py below and convert it to that file, and you should be able to train mmdetection cleanly and without errors.
위 소스코드를 다운로드 받으신 다음 LabelMe에서 사용하던 대로 명령어를 입력합니다.
python labelme2coco.py [변환할 이미지 및 JSON 폴더] [coco 데이터셋 변환 폴더명] --labels labels.txt
아래는 LabelMe에서 제공하는 예제입니다.
python labelme2coco.py data_annotated data_dataset_coco --labels labels.txt
'공대생의 팁' 카테고리의 다른 글
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg
최신 인공지능 기술이 고도로 발전하여 뚜렷한 성과들이 눈앞에 펼쳐지고 있지만, 현업에서 최신 기술을 적용하는 것은 결코 쉽지 않습니다. 데이터 별로 각각의 특성이 존재하고, 그 데이터에 적합한 인공지능 기술이 반드시 최신 기술이어야만 하는 것은 아닙니다. 즉, SOTA 모델이 특정 데이터에서 가장 좋은 성능을 내지 못할 수도 있다는 것입니다. 다시 말해, 기업에서 수익을 목적으로 데이터에 AI를 적용하기 위해 가장 좋은 AI 모델을 찾는 것이 매우 중요하다는 것입니다.
현업에서 사용하는 데이터를 가공하다 보니, 회전된 이미지가 어느 정도 기울어져 있는지 확인할 수 있는 방법을 찾아야 하는 상황이 생겼습니다. 관련 연구가 있는지 확인해보니 영상에서 기울어진 Object를 Bounding Box를 기울여서 표시하는 연구들이 진행되고 있는 것을 알게 되었습니다.
AI모델을 찾았으니 이 모델에서 학습할 수 있는 데이터를 만들어야겠지요? 이번 포스팅에서는 기울어진 물체를 Labeling할 수 있는 roLabelImg를 사용하는 방법에 대해 다루어보도록 하겠습니다.
https://github.com/cgvict/roLabelImg
GitHub - cgvict/roLabelImg: Label Rotated Rect On Images for training
Label Rotated Rect On Images for training. Contribute to cgvict/roLabelImg development by creating an account on GitHub.
github.com
1. python을 설치합니다. roLabelImg는 python 3.9 이하의 버전에서 구동이 가능합니다.
> conda create -n python3.9 -c conda-forge python=3.9
2. roLabelImg 프로그램 실행시 필수 패키지인 lxml과 pyqt를 설치합니다.
> conda install -c conda-forge lxml pyqt
2. git으로 roLabelImg를 다운로드합니다.
> git clone https://github.com/cgvict/roLabelImg
3. 설치된 pyqt에 포함된 pyrcc로 roLabelImg를 설정합니다. 자신이 설치한 pyqt버전이 5일 경우 pyrcc5를 실행합니다.
> pyrcc5 -o resources.py resources.qrc
4. roLabelImg를 실행합니다.
> python roLabelImg.py
위 과정대로 진행하셨다면 roLabelImg 프로그램이 실행되는 것을 확인하실 수 있습니다. 자신이 Label을 하고자 하는 이미지룰 불러봅니다.

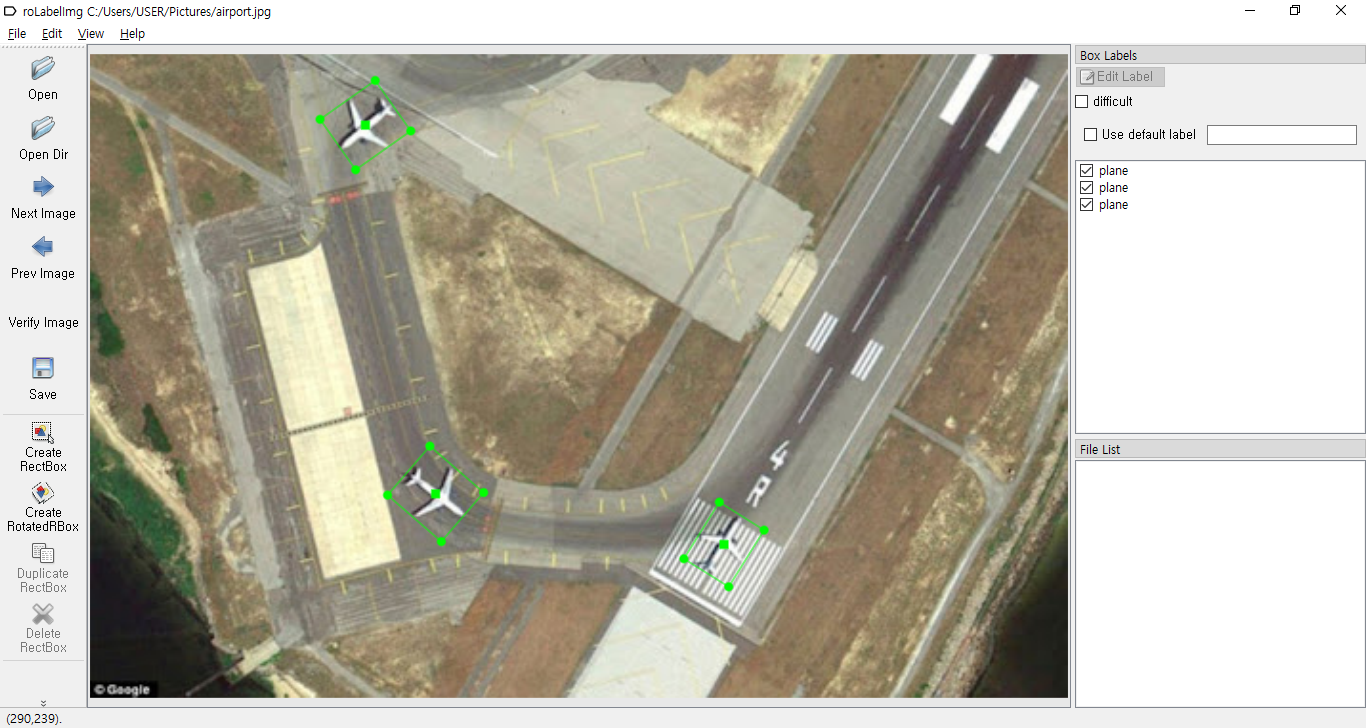
위성으로 찍은 공항 사진에서 비행기가 향하는 방향대로 Label을 진행해보겠습니다. 'Create Rotated RBox'를 클릭하여 아래와 같이 비행기를 전체적으로 Bounding합니다.

마우스를 Drag하여 Bounding Box를 만드는 작업이 완료되면 아래와 같이 방금 만든 Label의 속성을 설정할 수 있습니다.
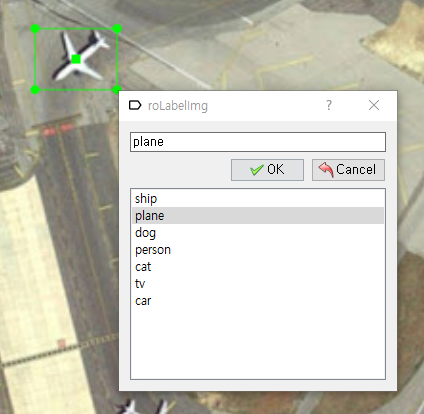
방금 만든 Rotated RBox를 회전시켜 원하는 방향으로 Bounding Box를 돌려보겠습니다. 방금 만든 Bounding Box의 모서리 중 하나에 마우스를 이동시킨 다음 마우스 우측 버튼을 클릭후 드래그를 하면 Bounding Box가 회전하는 것을 확인하실 수 있습니다.

아래 화면과 같이 Bounding Box가 비행기가 향하는 방향으로 회전된 것을 확인하실 수 있습니다.
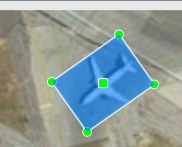
위와 같은 과정대로 이미지에 있는 3개의 비행기에 Rotated RBox를 모두 적용된 것을 확인하실 수 있습니다.
'프로그래밍 팁' 카테고리의 다른 글
| Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++) (0) | 2023.10.31 |
|---|---|
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
설정
트랙백
댓글
글
MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기
지난 포스팅에서 OCR(STR)의 개념과 발전 과정에 대해 설명드린 후, MMOCR의 동작 원리에 대해 설명을 드렸습니다. 이번 포스팅에서는 MMOCR에서 사용하고자 하는 데이터셋을 직접 제작하는 방법에 대해 소개드리도록 하겠습니다.
혹시 OCR의 기본 개념 및 원리에 대해 자세히 알고 싶으신 분은 아래 포스팅을 참조해주세요!
https://elecs.tistory.com/434
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적
elecs.tistory.com
1. OCR 데이터셋의 구조
딥러닝 분야에서 OCR은 이미지 내에서 글자를 찿아내는 Text Detection 과정과 이미지내 글자의 의미를 해석하는 Text Recognition 과정으로 분류됩니다. 쉬운 설명을 위해 사진으로 예시를 보여드리겠습니다.
Text Detection은 이미지를 모델에 입력하였을 때, 이미지에서 글자의 위치를 찾아내는 단계라고 보시면 됩니다 예를 들어 아래와 같은 사진이 모델의 Input으로 들어왔다고 가정합니다.

우리들의 눈으로 보았을 때, 위의 이미지에서 Text 정보로는 전철역 출입구 위에 적혀있는 'CC23', 'one-north'을 확인할 수 있습니다. OCR 모델의 출력은 사람이 글씨를 찾아내는 것과 같이 해당 글자 부분을 Object Detection처럼 표시해줄 것입니다.

MMOCR에서 제공하는 Text Detection 데이터셋 구성은 JSON 파일로 Label이 되어 있으며, 다음과 같이 구성됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_50.jpg",
"height": 720,
"width": 1280,
"instances":
[
{
"polygon":[53.0, 137.0, 97.0, 138.0, 97.0, 153.0, 52.0, 151.0]],
"bbox": [52.0, 137.0, 97.0, 153.0],
"bbox_label": 0,
"ignore": false
},
{
"polygon":[107.0, 138.0, 217.0, 143.0, 216.0, 162.0, 106.0, 157.0]],
"bbox": [106.0, 138.0, 217.0, 162.0],
"bbox_label": 0,
"ignore": false
}
]
}
]
}
|
cs |
Text Recognition은 입력된 이미지에서 Text를 추론하는 과정으로서, Text Recognition 모델의 출력은 해당 이미지의 Text입니다.
Text Recognition 모델에 다음과 같은 이미지가 입력되었을 때,

이미지 내의 Text가 Place임을 바로 알아낼 수 있습니다. Text Recognition 데이터셋 JSON Label은 다음과 같이 나타냅니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet"
"category": [{"id:0, "name": "text"}]
},
"data_list":
[
{
"img_path": "word_25.png",
"instances":
[
{
"text": "Place
}
]
}
]
}
|
cs |
2. 기존에 공개된 OCR 데이터셋 사용하기
위에서 설명드린 양식대로 데이터셋을 직접 만들 수도 있지만, MMOCR을 처음 접하는 경우 데이셋의 구조가 바로 이해가 되지 않을 것입니다. 데이터셋을 당장 만들기 어려우신 분이라면, 기존에 공개된 OCR 데이터셋을 사용해보시는 것을 추천드립니다. MMOCR은 공개된 데이터셋을 MMOCR에서 활용할 수 있는 양식의 데이터셋으로 변환하여 사용할 수 있게 해줍니다. 변환된 데이터셋의 구조를 확인하고 이해하신다면 Custom Dataset을 만드시는데 큰 도움이 될 것입니다. MMOCR에서는 총 16개의 데이터셋의 다운로드를 제공하고 있으며, 데이터셋의 목록은 아래의 주소에서 확인하실 수 있습니다.
https://github.com/open-mmlab/mmocr/tree/main/dataset_zoo
MMOCR에서 제공하는 데이터셋 다운로드 및 변환 기능을 사용해보도록 하겠습니다. 아래의 명령어를 입력하시면 ICDAR 2015 데이터셋을 다운로드한 다음, MMOCR 양식의 데이터셋으로 변환하실 수 있습니다.
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet
위의 명령어를 실행하면, ICDAR 2015 데이터셋을 Text Detection 양식의 데이터셋으로 변환하실 수 있습니다. 만약 Text Recognition 양식의 데이터셋을 원하시는 분께서는 task 옵션에 'textrecog'를 입력하시면 됩니다. 변환된 ICDAR2015 데이터셋을 data 폴더 내에서 확인하실 수 있습니다.
data/icdar2015
├── textdet_imgs
│ ├── test
│ └── train
├── textdet_test.json
└── textdet_train.json3. Tool을 사용하여 Labeling하기(AnyLabeling)
위의 설명을 통해 MMOCR 데이터셋의 구조를 이해하셨다면, 이번에는 우리의 손으로 직접 데이터셋을 만들어보겠습니다. Image 데이터에 Text 레이블링을 할 수 있는 프로그램 중 하나인 AnyLabeling으로 데이터셋을 사용하겠습니다. AnyLabeling은 아래의 github에서 다운로드하실 수 있습니다.
https://github.com/vietanhdev/anylabeling/releases
Releases · vietanhdev/anylabeling
Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything, MobileSAM!! - vietanhdev/anylabeling
github.com
AnyLabeling을 설치하신 다음 실행하여 Labeling을 하고자 하는 이미지를 불러옵니다.

위의 사진에서 '71'이라는 텍스트가 가장 먼저 보일 것입니다. 이 부분을 Labeling해보도록 하겠습니다. 좌측에서 사각형 Labeling을 선택하신 후 71을 Bounding Box로 표시해줍니다.
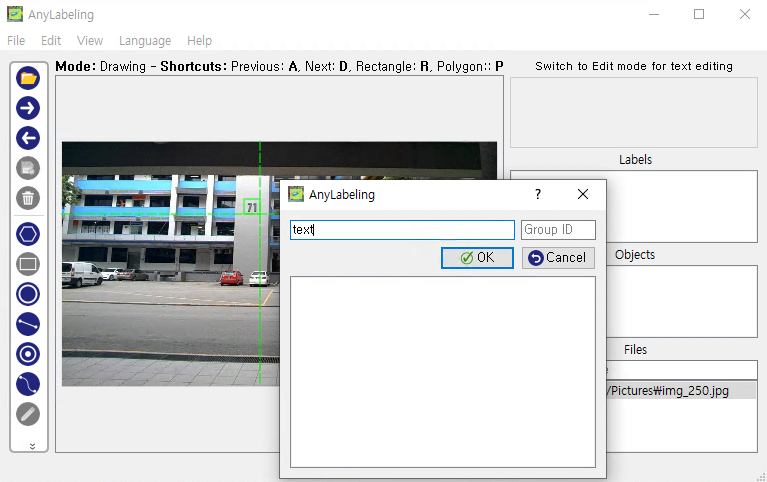
71에 대해 박스 표시가 완료되면, 해당 박스의 Label 정보를 무엇으로 할 지 설정하는 창이 뜰 것입니다. 이 단계에서는 해당 Label의 속성을 설정하는 단계로서, 여기서는 Label의 이름을 'text'로 설정해줍니다. 선택 완료시 labels 목록에 'text'가 추가되었으며, Objects 목록에서도 방금 만든 Box의 객체 정보가 추가된 것을 확인하실 수 있습니다.

다음으로, 방금전에 만든 Object에 Text 정보를 추가해보겠습니다. 좌측 하단에 연필 모양의 아이콘을 클릭하시면 수정모드에 진입하게 됩니다. 그와 동시에 우측 상단에 Text를 입력하는 칸이 활성화 됩니다. 여기서 주의할 것은 해당 칸이 활성화 되자마자 텍스트 정보 입력을 하게 되면, 해당 이미지 자체의 text 정보가 저장이 되버립니다. 방금 만든 '71'에 대한 Label 객체에 대해 text 정보를 추가하기 위해서는, 우측 정보란에 Objects 칸에서 '71'에 해당하는 Object를 목록에서 선택해줍니다.
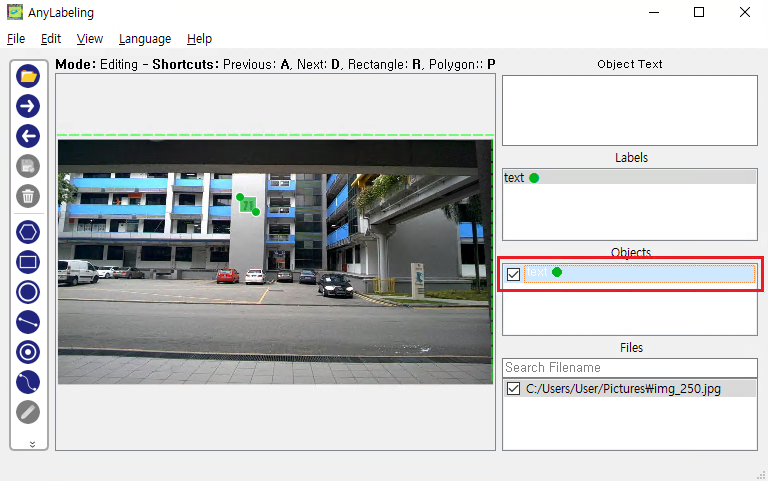
위의 화면에서 빨간색으로 표시한 부분을 클릭하면 '71'에 대한 Label 객체가 선택된 것을 확인하실 수 있으며, Text 정보 입력 칸 윗부분 표시가 'Object Text'로 변경되면서 Text를 입력할 수 있게 되었음을 확인하실 수 있습니다. 여기서 text 정보인 71을 입력해주시면
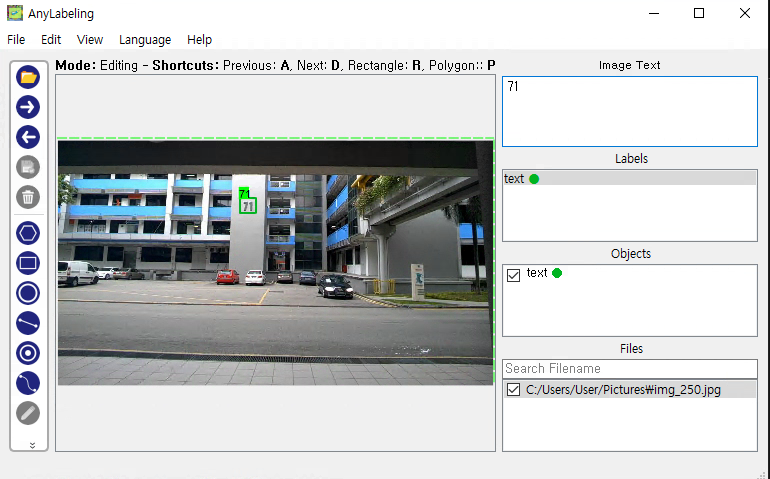
위의 화면과 같이 '71'이라는 text가 해당 Label 객체에 적용된 것을 확인하실 수 있습니다. 위의 과정으로 만든 Label 정보는 아래와 같이 json 양식으로 저장된 것을 확인하실 수 있습니다.

4. OCR 데이터셋으로 변환하기
지금까지 Anylabeling으로 이미지에 Text Labeling을 수행하는 방법에 대해 설명드렸습니다. 위의 과정으로 만든 json 파일을 MMOCR에서 학습할 수 있는 양식으로 변환하는 과정에 대해 설명드리도록 하겠습니다.
먼저, 이미지에서 Text를 찾아내는 과정인 TextDetection 데이터셋으로 변환해보도록 하겠습니다.
Anylabeling2textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import json
import random
import glob
import os
# Anylabeling으로 생성된 Label 데이터
input_path = 'Anylabeling'
# TextDetection 데이터셋으로 변환된 json 파일 저장경로
output_path = 'TextDet'
def extract_instance(shape):
instance = dict()
# 각 Instance별 Bounding Box 좌표값 추출
x1 = int(shape['points'][0][0])
y1 = int(shape['points'][0][1])
x2 = int(shape['points'][1][0])
y2 = int(shape['points'][1][1])
instance['polygon'] = [x1, y1, x2, y1, x2, y2, x1, y2]
instance['bbox'] = [x1, y1, x2, y2]
instance['bbox_label'] = 0
instance['text'] = shape['text']
instance['ignore'] = False
return instance
def create_json(json_list):
metainfo = dict()
# Text Detection 데이터셋
metainfo['dataset_type'] = 'TextDetDataset'
metainfo['task_name'] = 'textdet'
metainfo['category'] = [{'id': 0, 'name': 'text'}]
data_list = []
for file in json_list:
file_path = os.path.join(file)
file_name = os.path.splitext(os.path.basename(file))[0]
# Anylabeling에서 생성된 JSON파일 Load
with open(file_path) as f:
data = json.load(f)
img_info = dict()
# 이미지 파일 경로. 자신의 환경에 맞게 수정.
img_info['img_path'] = os.path.join(input_path, file_name + '.jpg')
img_info['height'] = int(data['imageHeight'])
img_info['width'] = int(data['imageWidth'])
img_info['instances'] = []
shapes = data['shapes']
for shape in shapes:
img_info['instances'].append(extract_instance(shape))
data_list.append(img_info)
json_text = dict()
json_text["metainfo"] = metainfo
json_text['data_list'] = data_list
return json_text
#Input 폴더내 모든 json파일을 불러옴
json_paths = glob.glob(os.path.join(input_path, "*.json"))
#Train-Test셋 데이터 생성(10:1)
random_files = random.sample(json_paths, 11)
remaining_files = [file for file in json_paths if file not in random_files]
trainset = create_json(remaining_files)
testset = create_json(random_files)
with open('textdet_test.json', 'w') as f:
json.dump(testset, f, indent=4)
with open('textdet_train.json', 'w') as f:
json.dump(trainset, f, indent=4)
|
cs |
위 소스코드를 샐행하면 아래와 같이 Text Detection Label 정보가 포함된 json 파일이 생성된 것을 확인하실 수 있습니다.
textdet_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
"metainfo":
{
"dataset_type": "TextDetDataset",
"task_name": "textdet",
"category": [{"id":0, "name": "text"}]
},
"data_list":
[
{
"img_path": "img_250.jpg",
"height": 720,
"width": 1280,
"instances":
[
"ploygon": [536, 169, 583, 169, 583, 213, 536, 213],
"bbox": [536, 169, 583, 213],
"bbox_label": 0,
"text": "71",
"ignore": false
]
}
]
}
|
cs |
다음으로 Text Detection 데이터셋 정보를 설정해줍니다. 아래의 예제는 Text Detection 데이터셋에 대한 설정 파일입니다.
textdet.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
textdet_data_root = 'data/textdet' #Text Detection Label JSON 폴더 위치
textdet_train = dict(
type='OCRDataset',
data_root=textdet_data_root,
ann_file='textdet_train.json',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=None)
textdet_test = dict(
type='OCRDataset'
data_root=textdet_data_root,
ann_file='textdet_test.json',
test_mode=True,
pipeline=None)
|
cs |
Text Detection 모델 중 하나인 TextSnake를 사용하여 위에서 작성한 Data Detection 데이터셋을 적용해보겠습니다.
textsnake.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
_base_ = [
'configs/text/textsnake/_base_textsnake_resnet50_fpn-unet.py',
# Text Detection 데이터셋 추가
'textdet.py',
'configs/textdet/_base_/default_runtime.py',
'configs/textdet/_base_/schedules/schedule_sgd_1200e.py',
]
# dataset settings
train_list = _base_.textdet_train
test_list = _base_.textdet_test
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_list)
val_dataloader = dict(
batch_size=1,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_list)
test_dataloader = val_dataloader
auto_scale_lr = dict(base_batch_size=4)
|
cs |
아래와 같이 한 줄의 명령어를 입력하시면 드디어 Text Detection 데이터셋이 학습되는 것을 확인하실 수 있습니다.
$ python tools/train.py textsnake.py
축하합니다! 여러분들을 드디어 Text Detection 데이터셋을 모델 학습에 적용하실 수 있게 되었습니다. Text Recognition 과정도 거의 비슷하게 진행되니, 잠시 숨을 고른 다음 Text Recognition 데이터셋 학습도 진행해보도록 합시다.
아래의 소스코드를 실행하여 Text Recognition 학습을 위한 json 파일을 생성합니다.
Anylabeling2textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import os
import copy
from PIL import Image
# Anylabeling이 생성한 json 폴더 경로
folder_path = 'Anylabeling'
# Label 저장 경로
save_path = 'output'
# folder_path 내부에 있는 json파일 모두 불러오기
json_files = [file for file in os.listdir(folder_path) if file.endswith('.json')]
# Text Recognition 양식의 JSON 파일 설정
data = {
"metainfo": {
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list": []
}
# Train Set
train = copy.deepcopy(data)
# Test Set
test = copy.deepcopy(data)
# Train-Test Set 분배를 위한 카운터
count = 0
for json_file in json_files:
# .json 확장자 제거
file_name = os.path.splitext(json_file)[0]
with open(os.path.join(folder_path, json_file), 'r', encoding='utf-8') as file:
json_data = json.load(file)
image = Image.open(os.path.join(folder_path, file_name + '.jpg'))
# 이미지에 Label이 있는지 확인
if len(json_data['shapes'] > 0:
shapes = json_data['shapes']
# 이미지 내에 각 Label을 꺼내옴
for i in range(len(shapes)):
# 원본 이미지에서 Text 정보 부분 추출
cropped_image = image.crop((shapes[i]['points'][0][0],shapes[i]['points'][0][1],shapes[i]['points'][1][0],shapes[i]['points'][1][1]))
# 추출된 Text 이미지를 별도의 폴더에 저장
cropped_image.save(os.path.join(save_path, file_name + '_' + str(i) + '.jpg'))
count+=1
# Text 정보를 TextRecognition Dataset 양식으로 저장
new_data = {
"instances": [{"text": shapes[i]['text']}],
"img_path": os.path.join(os.path.join(os.getcwd(), save_path, file_name + '_' + str(i) + '.jpg'))
}
# Train-Test Set 비율을 10:1로 저장
if count % 11 == 0:
test['data_list'].append(new_data)
else:
train['data_list'].append(new_data)
with open("textrecog_train.json", "w") as outfile:
json.dump(train, outfile, indent=4)
with open("textrecog_test.json", "w") as outfile:
json.dump(test, outfile, indent=4)
|
cs |
위 소스코드를 실행하면 Text Recognition Label 양식의 데이터가 적용된 json 파일이 생성된 것을 확인하실 수 있습니다.
textrecog_train.json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"metainfo":
{
"dataset_type": "TextRecogDataset",
"task_name": "textrecog"
},
"data_list":
[
{
"img_path": "output/word_1.png",
"instances":
[
{
"text": "71"
}
]
},
]
}
|
cs |
바로 Text Recognition 데이터셋 설정 파일을 만들어줍니다.
textrecog.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
textrecog_data_root = 'data/textrecog' #Text Recognition Label JSON 폴더 위치
textrecog_train = dict(
type='OCRDataset',
data_root=textrecog_data_root,
ann_file='textrecog_train.json',
pipeline=None)
textrecog_test = dict(
type='OCRDataset'
data_root=textrecog_data_root,
ann_file='textrecog_test.json',
test_mode=True,
pipeline=None)
|
cs |
거의 다 오셨습니다! SATRN 데이터셋에 방금 만든 Text Recognition 데이터셋을 적용해줍니다.
satrn.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
_base_ = [
'textrecog.py',
'configs/textrecog/_base_/default_runtime.py',
'configs/textrecog/_base_/schedules/schedule_adam_step_5e.py',
'configs/textrecog/satrn/_base_satrn_shallow.py',
]
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=20, val_interval=1)
# dataset settings
train_list = [_base_.textrecog_train]
test_list = [_base_.textrecog_test]
train_dataset = dict(
type='ConcatDataset', datasets=train_list, pipeline=_base_.train_pipeline)
test_dataset = dict(
type='ConcatDataset', datasets=test_list, pipeline=_base_.test_pipeline)
# optimizer
optim_wrapper = dict(type='OptimWrapper', optimizer=dict(type='Adam', lr=3e-4))
train_dataloader = dict(
batch_size=128,
num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
test_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=test_dataset)
val_dataloader = test_dataloader
#dataset_prefixes는 임의로 설정
val_evaluator = dict(dataset_prefixes=['IC15'])
test_evaluator = val_evaluator
auto_scale_lr = dict(base_batch_size=64 * 8)
|
cs |
아래의 명령어를 통하여 SATRN 모델을 학습합니다.
$ python tools/train.py satrn.py
이제 여러분께서는 MMOCR을 사용하여 Text Detection과 Text Recognition 데이터셋을 만들고 모델을 학습시키는 방법을 터득하였습니다!
'공대생의 팁' 카테고리의 다른 글
| [mmcv] AssertionError: only one of size and size_divisor should be valid (0) | 2024.03.31 |
|---|---|
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
설정
트랙백
댓글
글
P2P 투자 법인 설립 후기(2) - 1년반만에 폐업합니다
불과 작년에는 P2P 투자를 위해 법인을 설립하고 운영하는 방안에 대해 설명을 드렸습니다만 바로 다음으로 말씀드릴 이야기가 폐업소식이 될 줄을 제 자신도 몰랐습니다. 다행히도 적자 없이 작은 수익을 낼 수 있었으나, 굳이 법인을 유지하면서까지 관리를 해야 하는지에 대한 의문을 갖게 되었고, 가장 결정적으로 현재 자신이 하고 있는 일들에 조금 더 집중하고자 P2P 투자 법인을 폐업하는 것으로 결론을 내렸습니다.
혹여나 P2P 투자를 권하지 않기 위해 이 글을 쓰느냐 하면, 그렇지는 않습니다. 비록 거대한 사업을 꾸리지는 않았지만, 일개 회사 직원으로서는 알수 없었던 실제 회사 경영에 대해 직접 경험할 수 있었고, 법인을 소흘히 관리했다가는 큰 코 다칠 수 있음을 몸소 깨달았기에, 차후 다른 사업으로 법인을 설립하여 대표가 되었을 때, 이 경험을 반면교사로 삼고자 이렇게 글을 남기는 것입니다. 제가 이전에 작성하였던 글도 참고하시어 여러분들의 투자 방향에 참고해 주셨으면 합니다.

P2P투자법인 운영을 중단한 이유는?
법인을 설립하였던 2022년 초반, 넘쳐나는 자산 유동성만 보고 저는 단지 P2P 투자 한도를 늘리고자 하는 목적으로 투자 법인을 설립하게 되었습니다. 처음엔 법인 투자가 어려울 것이라 생각했지만, 법인 설립을 도와주겠다는 법률사무소들의 광고만 보았을 때는 누구나 쉽게 법인으로 원하는 사업을 할 수 있을 것 으로 착각하여 법인을 만들었습니다. 그러나, 폐업 및 법인 청산은 설립 과정보다 더 힘들다는 것을 의심하지 못했습니다. 저 또한 P2P 사업회사로 수익 창출만 생각하고 법인을 설립하였지만, 법인 관리 자체만 해도 많은 난관에 부딪치는 상황이 펼쳐졌습니다. 제게 P2P 투자 법인 설립이 매리트가 없었던 3가지 이유를 설명드리고자 합니다.
1. 너무나 어려운 법인통장 개설

법인통장 개설 전 은행에 전화하여 구비 서류를 다 가지고 갔지만, 사업장 실사 방문, 사업자등록 1년 이상, 대표의 거주지와 법인의 사무실 위치 등 추가적으로 요구하는 사항들이 너무나 많았고, 간신히 모 저축은행에서 계좌를 개설할 수 있었지만, 해당 은행에서 OTP를 제공하지 않아 타 은행 OTP를 등록해야 인터넷 뱅킹을 사용할 수 있는 상황이어서 한동안은 지점에 직접 방문해서 은행 업무를 수행해야 했습니다.
이토록 은행들이 계좌 취급을 까다롭게 하는 이유는 다름아닌 보이스피싱 예방 차원이라 하지만, 악의적인 목적을 갖고 있지 않은 법인사업자가 통장 없이 어떻게 사업을 운영하라는 건지 참으로 답답한 상황이었습니다. 운 좋게도 1년동안 법인 운영을 열심해 한 덕에 간신히 케이뱅크 법인계좌를 만들 수 있었습니다만, 애초에 이렇게 은행 계좌 하나 만드는게 이토록 어려운 일이었다면 저는 아마도 법인 설립 자체를 시도도 하지 않았을 것입니다.
무엇보다도 보이스피싱이 의심된다고 무턱대고 계좌 개설을 방어하게 만든 문제로 인해 사업을 시작하는 사람들의 꿈이 좌절되는 상황이 한시바삐 해결되었으면 합니다.
2. 설립은 쉬우나 해산은 어려운 법인 관리

법인 설립은 생각보다 쉽습니다. 업종 선택을 하고 사무실을 구한 다음 자본금과 각종 수수료(법률사무소 대행 수수료, 각종 증빙서류 발급수수료 등)만 지출하면 법인 설립이 완료됩니다.
그러나 법인의 해산은 절차가 훨씬 어렵습니다. 자본금이 잠식되어 적자 상태인 법인은 채무 청산을 하지 않으면 법인 해산이 불가능하며, 설령 빚이 없는 법인이더라도 법인 혼자서 해산을 진행하기엔 절차가 상당히 복잡하여 법률사무소에 대행을 요청해야 하는데 전체 비용이 2023년 기준 200만원에 육박합니다. 법인 자산 관리를 제대로 하지 못할 경우 금전적인 면에서도 시간적인 면에서도 손해일 수 있습니다. 소액 투자 법인의 경우 법인 등기 신청 후 8년동안 아무것도 하지 않고 기다리면 해산간주하여 자본금을 회수할 수 있지만, 5년동안 그 어떤 영리활동을 할 수 없어 8년간 발생하게 되는 법인 관리 비용이 골치아플 수 있습니다.
물론 저는 이러한 법인 관리의 어려움을 감당할 자신이 있습니다. 그러나 제가 P2P 투자법인을 청산하기로 결정한 계기는 미래의 불확실성이었습니다.
3. 예측 불가한 투자 환경의 변화

어떤 자산에 투자하든 위험요소를 관리해야 한다는 것은 자명한 이야기입니다. 2023년 현재 대한민국의 경제 상황을 보았을 때, 부동산 투자 상품이 주를 이루는 P2P투자에 위험요소가 커졌다고 저는 중대한 판단을 하게 되었습니다. 2020년 코로나19바이러스 전염으로 전 세계가 경제 침체를 겪고 있는 상황에서 각국은 금리 인하로 경제 부양을 하게 되었고 그 결과 시장에는 엄청난 양의 돈이 쏟아지게 되었습니다. 주식 시장은 V자 반등으로 다시 상승할 수 있었고, 부동산으로도 풀린 자금들이 유입되면서 전국적으로 집값이 2배 이상 상승하는 곳이 대다수였을 정도였습니다.
그러나 시장에 엄청난 돈이 풀리면서 돈의 가치 하락으로 인해 인플레이션 증가율이 상승시켰고, 이 와중에 러시아가 우크라이나를 침공이 촉발한 원자재 가격 상승으로 인플레이션이 가속화되자 당국은 물가 안정을 위해 기준금리를 올렸고, 자금 경색으로 인해 부동산 기반 프로젝트 파이낸싱(PF)으로 대출을 받던 건설사들이 불어난 이자를 감당하지 못해 최근 T건설이 워크아웃을 신청하는 상황에 이르렀습니다.
지난 2008년 리먼브라더스 사태로 촉발된 경제 위기로 자산 가치가 폭락하였던 비교적 가까운 과거의 상황과 비교하였을 때, 지금 상황이 그렇게 녹록치 않다는 생각을 하였습니다. 차후 P2P 투자상품이 PF로 촉발된 건설업의 침체르 인해 상품의 리스크가 커질것으로 보아 적어도 지금 내가 가지고 있는 자산을 지켜야 하는 방향으로 관리를 해야 겠다 판단을 하였고, P2P 투자 법인을 정리하기로 하였습니다. 투자금이 회수되지 않으면 P2P 투자 법인을 정리하는 것이 더 어려워지기 때문에, 이번달 모든 투자 원금 및 이자를 회수하였고, 며칠전 법인 폐업 신고를 하였습니다. 차후 8년간 P2P 법인 활동을 할 계획이 없으므로 8년 후 자본금과 이자를 회수할 수 있을 것입니다. 하지만, 그 기간 동안 인플레이션으로 인한 돈의 가치를 고려한다면, 안타깝게도 저에게 P2P 법인투자는 큰 이익이 되지 못할 것입니다.

투자를 함에 있어 가장 중요한 것은 리스크를 어떻게 관리할 것인지를 잊지 말아야 할 것입니다. 설령 시중은행에 예금을 하더라도 5천만원까지만 보호받을 수 있음을 유념하여 자신의 투자 방향에 부합하는지 곰곰히 생각한 후 투자를 결정하셨으면 합니다.
비록 지금은 이렇게 투자 실패기를 작성하지만, 차후에는 좀더 현명한 판단으로 재산도 지키고 자산을 불릴 수 있는 좋은 결과를 소개해드리겠습니다.
'흔치않은일상' 카테고리의 다른 글
| 게임큐브 컨트롤러를 PC에 연결해 Dolphin 에뮬레이터에서 사용해보기 (0) | 2024.04.07 |
|---|---|
| P2P 투자 법인 설립 후기(1) - 설립 준비 전 고려할 사항들 (1) | 2022.09.20 |
| 누적방문객수 100만명 돌파했습니다! (0) | 2022.05.30 |
| 코로나19와의 사투(3) - 5일만에 퇴원하다 (0) | 2022.03.19 |
| 코로나19와의 사투(2) - 퇴소 그리고 입원 (0) | 2022.03.13 |
설정
트랙백
댓글
글
MMCV에서 사용되는 pretrained model 주소 알아내는 방법
mmsegmenataion으로 모델을 학습하는 과정에서 가끔씩 난처한 상황을 맞이하는 경우가 있습니다. 아래와 같이 소스코드 내부를 살펴보았을 때 Pretrained 모델이 경로로 설정되어 있는데 만약 pretrained=None로 설정을 할 경우 모델 학습이 전혀 진행되지 않는 경우가 발생합니다.
|
1
2
3
4
5
|
model = dict(
data_preprocessor=data_preprocessor,
pretrained='pretrain/vit_base_patch16_224.pth',
text_encoder=dict(dataset_name='voc'),
decode_head=dict(num_classes=20))
|
cs |
이 문제를 근본적으로 해결할 수 있는 방법은 해당 Pretrained 모델을 다운로드 받아 사용하는 것인데 mmsegmentation 공식 사이트에서는 해당 내용을 찾기가 어려웠습니다. 혹시나 싶어 구글에 'openmmlab vit_base_patch16_224.pth'와 같이 mmsegmenatation에 국한하지 않고 openmmlab 전체에서 해당 사전학습 모델을 찾을 수 있는지 검색해 보았습니다.
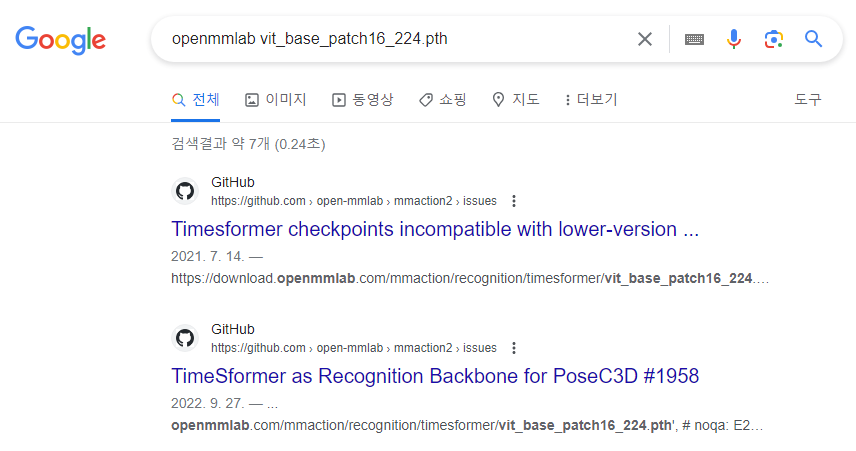
검색 결과 뭔가 힌트가 될 만한 주소가 얼핏 보이는 것이 확인되어 아래와 같이 검색을 시도해보았고...
https://download.openmmlab.com/mmaction/recognition/timesformer/vit_base_patch16_224.pth
다행히도 해당 Weight 모델이 다운로드 되는 것을 확인하였습니다.
'공대생의 팁' 카테고리의 다른 글
| LabelMe로 Coco 데이터셋 변환후 MMDetection에서 학습이 안될 때 해결 방법 (0) | 2024.03.26 |
|---|---|
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
설정
트랙백
댓글
글
Windows 환경에서 MMDeploy로 TensorRT 구동(Python, C++)
대다수의 AI 개발은 Linux 환경에서 이루어지다 보니 Linux환경에서 개발된 오픈소스 라이브러리를 Windows에서 사용하기 위해서는 Windows의 환경에 맞추어 설정을 해야하는 번거로움이 발생하곤 합니다. 사내 자체 개발이 목적이라면 Linux를 사용하는 것이 큰 문제가 되지 않을 수 있으나 고객사에서 Windows 환경에서의 사용을 원한다면 사실상 소스코드를 처음부터 설계한다는 각오를 해야 하기 때문에 개발에 많은 시간이 소요되는 안타까운 사례들이 있습니다.
OpenMMLab에서 공개된 오픈소스 라이브러리인 MMCV는 Linux 환경은 물론, Windows에서도 프로그램이 구동될 수 있도록 지원을 해주고 있습니다. 덕분에 Linux 천하의 Vision AI 개발 환경에서 Windows 운영체제 환경에 맞추어 사용할 수 있는 AI 모델을 개발할 수 있어 개발자의 입장에서 보았을 때 막대한 개발 시간이 소요되는 경우를 막을 수 있습니다.
이번 포스팅에서는 MMCV로 개발된 딥러닝 모델을 MMDeploy로 경량화한 다음, 개발한 딥러닝 모델이 Windows 환경에서 보다 빠르게 구동될 수 있도록 만드는 과정에 대해 다루어보도록 하겠습니다.
※MMDeploy는 OpenMMLab에서 공개한 라이브러리(MMDetection, MMSegmentation 등)를 실제 동작환경에서 경량화 및 가속화를 도와주는 라이브러리입니다. MMDeploy에 대해 자세한 내용은 아래의 포스팅을 참조 바랍니다.
인공지능 모델 최적화 배포 라이브러리 - MMDeploy
연구 단계에서의 인공지능 모델 설계는 일반적인 환경 내에서 개발하고 성능을 분석할 때는 별 문제가 없다가도 막상 실제 특정 환경에서 적용을 시도해보려 하면 모델 구동 시간이 상당히 오
elecs.tistory.com
1. 버전 맞추기
2023년 4월 6일 OpenMMLab 2.0 방식의 최신 소스코드 구조가 적용된 MMDeploy 1.0 버전이 공개었습니다. 자신이 개발한 버전에 따라 해당 버전의 MMDeploy를 설정합니다. 본 예제에서는 MMSegmentation 0.30.0, MMDeploy 0.14.0 버전을 기준으로 작성하였습니다.

git clone https://github.com/open-mmlab/mmdeploy.git
git fetch --all --tags
git checkout tags/v0.14.0
2. MMDeploy 설치
Github를 통해 MMDeploy 소스코드 다운로드를 수행한 다음 MMDeploy을 사용하기 위해 필요한 pip 패키지들을 설치합니다.
pip install mmdeploy==0.14.0 mmdeploy-runtime==0.14.0 mmdeploy-runtime-gpu==0.14.0
3. MMPretrain(구 MMClassification) 설치
설치하시는 MMDeploy 버전이 1.x일 경우 MMPretrain을 설치합니다.
pip install mmpratrain
설치하시는 MMDeploy 버전이 0x.일 경우 MMClassification을 설치해주세요
pip install mmcls
4. ONNX 설치
MMDeploy는 MMCV로 개발된 딥러닝 모델을 ONNX로 변환한 다음 TensorRT로 변환하는 방식으로 2단계 변환을 수행합니다. 다음과 같이 ONNX를 설치합니다. 먼저 pip로 ONNX 패키지를 설치한 다음
pip install onnxruntime==1.8.1
다음으로 아래의 Github 사이트를 통해 onnxruntime 소스코드를 다운로드 받습니다.
https://github.com/microsoft/onnxruntime/releases/
Releases · microsoft/onnxruntime
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator - microsoft/onnxruntime
github.com
5. Nvidia 라이브러리 설치(CUDA, cuDNN, TensorRT)
자신의 환경에 맞는 버전의 CUDA, cuDNN, TensorRT를 설치합니다. cuDNN과 TensorRT 설치를 위해 Nvidia 계정이 필요합니다.
CUDA Toolkit >= 11.1
https://developer.nvidia.com/cuda-toolkit-archive/
CUDA Toolkit Archive
Previous releases of the CUDA Toolkit, GPU Computing SDK, documentation and developer drivers can be found using the links below. Please select the release you want from the list below, and be sure to check www.nvidia.com/drivers for more recent production
developer.nvidia.com
cuDNN >= 8.2.1.0
https://developer.nvidia.com/cudnn/
CUDA Deep Neural Network
cuDNN provides researchers and developers with high-performance GPU acceleration.
developer.nvidia.com
TensorRT >= 8.2.3.0
https://developer.nvidia.com/tensorrt-getting-started/
TensorRT - Get Started
Learn more about NVIDIA TensorRT and check out the latest codes and tutorials.
developer.nvidia.com
6. OpenCV 설치
Image Processing 과정에서 주로 사용되는 OpenCV 라이브러리를 설치합니다.
Python만 사용하실 예정이신 분은 pip를 통해 설치합니다.
pip install opencv-python
C++ 환경에서 TensorRT를 사용하고자 하시는 분은 OpenCV 공식 사이트에서 Runtime 라이브러리를 설치해줍니다. Windows 환경에서 설치하기 위해서는 아래의 사이트를 참조하여 설치해주시기 바랍니다.
https://hello-bryan.tistory.com/29
[OpenCV 설치] Windows OpenCv 설치
OpenCV 설치 Windows OpenCV OpenCV 공식 홈페이지로 갑니다. https://opencv.org 상단 메뉴의 RELEASES 를 클릭하고 원하는 버전의 Win Pack 을 클릭하여 다운로드 페이지로 이동합니다. 광고가 겁나많은 다운로드
hello-bryan.tistory.com
7. 환경변수 설정
위의 과정을 통해 설치하였던 onnxruntime, CUDA, cuDNN, TensorRT 라이브러리를 환경변수 Path에 등록합니다. 또한, CUDA_PATH의 환경변수 또한 다음과 같이 등록해주시기 바랍니다.
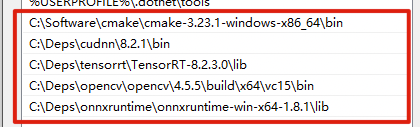
8. Pycuda 설치
Python에서 CUDA 병령 컴퓨팅 API를 수행할 수 있도록 해주는 pycuda를 설치합니다. 만약 설치 과정에서 실패하는 경우 위 6번 과정에서 설치한 라이브러리 환경변수 설정에서 잘못된 경우가 있을 수 있으므로 한 번 더 확인해보시기 바랍니다.
pip install pycuda
9. MMDeploy SDK 설치
Github에 공개된 MMDeploy의 release 라이브러리 탭에서 자신에게 맞는 버전을 선택 후 Assets에서 SDK를 다운로드 받습니다. 여기서는 "mmdeploy-0.14.0-windows-amd64-cuda11.3.zip"을 다운로드 합니다.
https://github.com/open-mmlab/mmdeploy/tags/
GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework
OpenMMLab Model Deployment Framework. Contribute to open-mmlab/mmdeploy development by creating an account on GitHub.
github.com
C++ 환경에서 사용하고자 하시는 경우 SDK를 폴더에 압축해제 하신 다음 Powershell을 실행하여 아래의 경로로 이동해주세요.
mmdeploy-0.14.0-windows-amd64-cuda11.3\example\cpp\build
위 경로로 이동한 다음 C++ SDK를 빌드합니다.
> cmake .. -DMMDeploy_DIR="mmdeploy-0.14.0-windows-amd64-cuda11.3\lib\cmake\mmdeploy" -DTENSORRT_DIR="TensorRT 설치 경로" -DONNXRUNTIME_DIR="onnxruntime 설치 경로" -DOpenCV_DIR="opencv\build\x64\vc15\lib"
> cmake --build . --config Release
10. Model 변환
지금까지 TensorRT를 사용하기 위해 구동 환경에서 MMDeploy를 적용하는 방법에 대해 설명드렸습니다. 이제 본격적으로 자신이 개발한 Model을 배포 환경에서 구동할 수 있도록 변환하는 단계를 진행해보도록 하겠습니다.
Python 소스코드를 아래와 같이 작성한 다음 실행합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from mmdeploy.apis import torch2onnx
from mmdeploy.apis .tensorrt import onnx2tensorrt
from mmdeploy.backend.sdk.expert_info import export2SDK
import os
img = '테스트하고자 하는 이미지 경로'
work_dir = 'TensorRT 변환 모델 저장 폴더 경로'
save_file = 'end2end.onnx'
deploy_cfg = 'mmdeploy/configs/mmseg/segmentation_tensorrt-fp16_static-512x512.py'
model_cfg = 'mmseg/자신이 학습한 모델의 설정.py'
model_checkpoint = '변환하고자 하는 모델.pth'
device = 'cuda'
# 1. convert model to IR(onnx)
torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg, model_checkpoint, device)
# 2. convert IR to tensorrt
onnx_model = os.path.join(work_dir, save_file)
save_file = 'end2end.engine'
model_id = 0
onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, onnx_model, device)
# 3. extract pipeline info for sdk use (dump-info)
export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint, device=device)
|
cs |
위의 소스코드를 실행하시면 work_dir 폴더에 다음과 같은 파일들이 생성된 것을 확인하실 수 있습니다.
deploy.json
detail.json
end2end.engine
end2end.onnx
pipeline.json
11. Inference 코드 구현
이제 여러분들이 개발한 딥러닝 모델이 TensorRT로 변환된 것을 확인하였습니다. TensorRT 최적화 모델을 아래와 같이 실행할 수 있습니다.
- python
> python MMDEPLOY/mmdeploy/tools/deploy.py MMDEPLOY/mmdeploy/configs/mmseg/segmentation_tensorrt-int8_static-512x512.py MMSEGMENTATION/configs/모델 설정 파일.py 학습한 모델.engine "데모 이미지.jpg" --device cuda:0
> python MMDEPLOY/demo/python/image_segmentation.py cuda "work_dir 경로" "데모이미지 경로.jpg"
- C++
> MMDeployDIR/example/cpp/build/release/image_segmentation.exe cuda "work_dir 경로" "데모이미지 경로.jpg"
이제 여러분들도 MMDeploy를 통해 경량화돤 모델이 배포 환경에 맞추어 실행 속도가 굉장히 향상된 것을 확인하실 수 있습니다.
- 참고자료
https://mmdeploy.readthedocs.io/en/v0.14.0/get_started.html#installation
Get Started — mmdeploy 0.14.0 documentation
Get Started MMDeploy provides useful tools for deploying OpenMMLab models to various platforms and devices. With the help of them, you can not only do model deployment using our pre-defined pipelines but also customize your own deployment pipeline. Introdu
mmdeploy.readthedocs.io
https://mmdeploy.readthedocs.io/en/v0.14.0/02-how-to-run/prebuilt_package_windows.html
How to use prebuilt package on Windows10 — mmdeploy 0.14.0 documentation
Docs > How to use prebuilt package on Windows10 以中文阅读 Shortcuts
mmdeploy.readthedocs.io
'프로그래밍 팁' 카테고리의 다른 글
| 회전 이미지를 직사각형으로 Labeling하는 방법 - roLabelImg (0) | 2024.02.25 |
|---|---|
| 인공지능 모델 최적화 배포 라이브러리 - MMDeploy (0) | 2023.04.08 |
| MMCV에서 직접 만든 데이터셋 학습 시키기(COCO, Pascal VOC Custom Dataset 만들기) (0) | 2023.03.27 |
| 복합 이벤트 처리 라이브러리 Esper를 VScode에서 실행해보기 (1) | 2022.10.09 |
| VScode 확장 원격 설치가 진행되지 않을때 직접 설치하기 (0) | 2022.08.04 |
설정
트랙백
댓글
글
Android에서 Glib 사용하기(NDK)
최근 안드로이드 태블릿을 사용하게 되면서 일상에 많은 변화를 체험하고 있습니다. 휴대폰에 비해 압도적으로 큰 화면 덕분에 장거리 이동시 유튜브 영상 시청을 하거나, 블루투스 키보드를 연결하여 노트북 대용으로 업무를 수행할 수 있고, 통신사 USIM칩을 삽입하면 장소에 구애받지 않고 어디서든 인터넷을 사용할 수 있어 Wi-Fi를 찾아다니며 인터넷 연결을 해야 했던 노트북에 비해 상당한 편리함을 느끼고 있습니다.
최근에 영상 활용 프로그램을 개발하고 있어 노트북을 자주 들고 다니는데, 이참에 안드로이드 태블릿으로 업무를 수행하면 좀 더 편하게 다닐 수 있을 것이라 생각되어 안드로이드 앱으로 내가 필요한 기능을 구현해보기로 하였습니다.
처음엔 안드로이드도 Linux 기반이어서 Linux PC에서 개발하였던 프로그램을 쉽게 설계할 수 있을 것이라 생각하고 덤볐는데 예상치 못한 난관을 (예상대로) 겪고 있습니다. NDK를 처음 사용하다보니 생각보다 공부할게 많고...
언제나 그랬듯이 좌충우돌 하며 NDK에 대해 공부했던 내용들을 정리해보고자 합니다. Linux 환경에서 자주 사용되는 Glib를 Android NDK 환경에서 사용할 수 있도록 라이브러리를 컴파일 하는 방법에 대해 살펴보도록 하겠습니다.
※개발환경
운영체제: Ubuntu22.04(WSL2)
Android버전: API21
NDK버전: r25c
1. Android NDK 설치
안드로이드 공식 사이트에서 NDK를 다운로드 받습니다. 다음으로 폴더 압축을 푼 다음 .bashrc에 NDK폴더 경로를 PATH 환경변수에 추가해줍니다.
NDK 다운로드 | Android NDK | Android Developers
NDK 다운로드 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 개발 플랫폼에 맞는 NDK 패키지를 선택합니다. NDK 최신 버전의 변경사항 및 이전 버전에 관한 정
developer.android.com
export PATH=NDK경로:$PATH
2. 개발환경 구축
Android NDK 개발환경 구축을 위해 필요한 패키지들을 설치합니다.
$ sudo apt install meson ninja openjdk-19-jdk
3. Glib 사용을 위한 라이브러리 다운로드
Glib 라이브러리는 아래 사이트에서 다운로드 합니다. (glib-2.77.2 기준)
https://gitlab.gnome.org/GNOME/glib/-/releases/2.77.2
Glib 라이브러리를 사용하기 위해서는 아래의 패키지들이 먼저 준비되어 있어야 합니다.
Libiconv
http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.17.tar.gz
Gettext
http://ftp.gnu.org/pub/gnu/gettext/gettext-0.21.tar.gz
4. Configure 환경 구성 및 컴파일
다운로드한 라이브러리를 Android 기기에서 동작할 수 있도록 컴파일 하기 위해 Configure 환경에 맞게 설정을 해주어야 합니다. 아래의 스크립트를 자신의 환경에 맞추어 작성합니다.
# env.sh
#컴파일된 패키지가 설치될 경로
export PREFIX=/home/user/Android
#라이브러리 경로
export LIBDIR=$PREFIX/lib
#include 경로
export INCLUDEDIR=$PREFIX/include
#pkg-config 경로
export PKG_CONFIG_PATH=$PREFIX/lib/pkgconfig
#Build가 진행되는 HOST기기 정보
export BUILD_SYS=x86_64-linux-gnu
#적용하고자 하는 최소 안드로이드 버전. 21부터 aarch64(ARMv8) 지원
export ANDROID_API=21
#NDK 내부에 위치한 sysroot 경로
export SYSROOT=NDK설치경로/toolchains/llvm/prebuilt/linux-x86_64/sysroot/
export TOOLCHAIN=NDK설치경로/toolchains/llvm/prebuilt/linux-x86_64/
#안드로이드 기기의 아키텍처
export TARGET=aarch64-linux-android #ARMv8
#export TARGET=armv7a-linux-androideabi #ARMv7
#export TARGET=i686-linux-android #32비트
#export TARGET=x86_64-linux-android #64비트
export AR=$TOOLCHAIN/bin/llvm-ar
export CC=$TOOLCHAIN/bin/$TARGET$ANDROID_API-clang
export AS=$TOOLCHAIN/bin/llvm-as
export CXX=$TOOLCHAIN/bin/$TARGET$ANDROID_API-clang++
export LD=$TOOLCHAIN/bin/ld
export RANLIB=$TOOLCHAIN/bin/llvm-ranlib
export STRIP=$TOOLCHAIN/bin/llvm-strip
export LD_LIBRARY_PATH=$LIBDIR
export CFLAGS="-fPIC -I$INCLUDEDIR"
export CXXFLAGS="-fPIC -I$INCLUDEDIR"
export LDFLAGS="-fPIC -pie -L$LD_LIBRARY_PATH"
export LIBS="-L$LD_LIBRARY_PATH"
export PKG_CONFIG=/usr/bin/pkg-config
export PKG_CONFIG_PATH=$LIBDIR/pkgconfig환경 구성 스크립트 작성이 완료되었다면 이제 본격적으로 라이브러리를 크로스컴파일 해보겠습니다. 먼저 libiconv 라이브러리를 크로스컴파일합니다.
. ./env.sh
cd libiconv-1.17/
./configure --host=$TARGET \
--prefix=$PREFIX \
--enable-static
make -j8
make install다음으로 Gettext 라이브러리를 크로스컴파일 합니다.
. ./env.sh
cd gettext-0.21/
./configure --host=$TARGET \
--prefix=$PREFIX \
--enable-static
make -j8
make install5. Glib 크로스컴파일을 위한 meson 환경 구성 및 컴파일
Glib을 사용하기 위해 필요한 라이브러리 설치가 완료되었다면 Glib를 크로스컴파일 합니다. Glib는 meson 컴파일 환경을 제공하고 있어 아래와 같이 cross_file.txt 파일을 작성하여 적용하실 수 있습니다.
[constants]
arch = 'aarch64-linux-android'
android_ndk = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/'
outdir = '라이브러리 설치 경로/'
[binaries]
ar = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-ar'
c = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android21-clang'
as = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-ar'
cpp = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android21-clang++'
ranlib = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-ranlib'
strip = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-strip'
ld = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/ld'
objcopy = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-objcopy'
pkgconfig = '/usr/bin/pkg-config'
[properties]
sys_root = 'NDK 경로/toolchains/llvm/prebuilt/linux-x86_64/sysroot'
pkg_config_lib_dir = '라이브러리 설치 경로/lib/pkgconfig'
[host_machine]
system = 'android'
cpu_family = 'aarch64'
cpu = 'aarch64'
endian = 'little'
[built-in options]
prefix = '라이브러리 설치 경로/'
c_args = ['-fPIC','-I/라이브러리 설치 경로/include']
cpp_args = ['-fPIC','-I/라이브러리 설치 경로/include']
c_link_args = ['-fPIE','-L/안드로이드 설치 경로/lib']
pkg_config_path = '/안드로이드 설치 경로/lib/pkgconfig'
default_library = 'static'
cross_file.txt 파일이 준비되었다면 컴파일 및 설치를 진행합니다.
# . ./env.sh
cd glib-2.77.2
meson build --cross-file cross_file.txt
cd build
ninja
ninja install6. 안드로이드 프로젝트에 적용하기
라이브러리 설치 경로에 Glib 라이브러리 파일이 만들어진 것을 확인하실 수 있습니다. 만들어진 Glib 라이브러리 파일을 자신의 NDK 프로젝트에 삽입하시면 안드로이드 앱으로 Glib를 실행할 수 있습니다.
참고자료
GitHub - edaplayer/android-ndk-harfbuzz
Contribute to edaplayer/android-ndk-harfbuzz development by creating an account on GitHub.
github.com
Cross-compile GLib for Android — MobileInsight Official Website
First get the source code for gettext 0.18.3 $ wget http://ftp.gnu.org/pub/gnu/gettext/gettext-0.18.3.tar.gz $ tar zxvf gettext-0.18.3.tar.gz To compile gettext-0.18.3, a patch must be applied. In gettext-tools/src/msginit.c, change line 1088 from fullname
mobileinsight.net
Cross-compile GLib for Android · Nosce Te Ipsum
Cross-compile GLib for Android 17 Jul 2016 Prepare cross-compile environment Update: You may now use Android NDK r15c and beyond. I have made an all-in-one script repo at my GitHub repo First, you need to have Android NDK r10e installed, which can be downl
zwyuan.github.io
설정
트랙백
댓글
글
PowerShell에서 Visual Studio x64 환경으로 개발하기
최근 Windows 환경에서 개발을 진행하다보니 자연스레 MSVC 환경에서 동작하는 프로그램을 설계하는 일을 하게 되었습니다. 기존에 Linux 환경에서 개발하던 소스코드를 관리하다보니 Visual Studio에서 보다 Terminal 환경에서 개발을 하다보니 골때리는 경우가 한두가지가 아닙니다..
Windows 11에서 부터는 공식적으로 32비트 환경에서의 개발이 중단되면서 64비트 환경의 개발환경이 필요했습니다. 물론 Visual Studio에서는 여전히 32비트 환경 개발을 지원합니다.
문제는 Visual Studio를 설치하였을 때 제공하는 Developer Command 환경이 PowerShell에서는 32비트만 기본으로 실행됩니다. Cmd 환경에서는 32비트와 64비트 모두 제공하는데 말이죠.
물론 Cmd 환경에서 64비트 환경을 개발하는 방법이 있으나 제가 PowerShell이 더 익숙하다보니 Visual Studio에서 기본 제공하는 환경에서는 개발이 어려운 상황입니다.
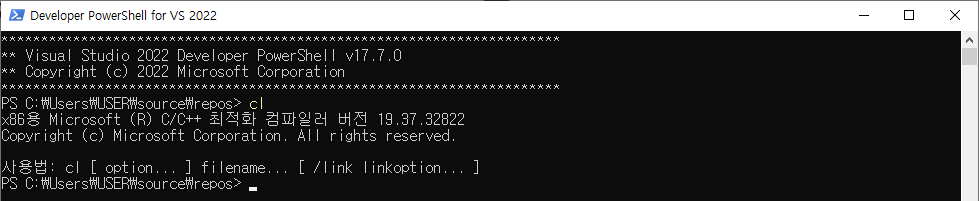
PowerShell에서 64비트 환경을 구현하려면 직접 PowerShell에서 명령어를 구현해야 합니다. 다행히도 Microsoft에서 Command 개발 환경 설정 방법에 대해 설명한 자료가 있었습니다.
명령줄에서 Microsoft C++ 도구 집합 사용
Visual Studio IDE 외부의 명령줄에서 Microsoft C++ 컴파일러 도구 집합(MSVC)을 사용합니다.
learn.microsoft.com
개발자용 명령줄 셸 및 프롬프트 - Visual Studio (Windows)
도구 > 명령줄 메뉴에서 시작합니다. .NET 및 C++ 도구를 더 쉽게 사용하려면 Visual Studio 개발자 명령 프롬프트나 개발자 PowerShell 또는 터미널을 선택합니다.
learn.microsoft.com
자신의 컴퓨터 환경에 맞추어 Visual Studio에서 제공하는 'Launch-VsDevShell.ps1'을 실행하면서 64비트의 환경을 설정해주면 PowerShell에서도 64비트 환경의 프로그램 수행을 하실 수 있습니다.
powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'C:\Program` `Files\Microsoft` `Visual` `Studio\2022\Community\Common7\Tools\Launch-VsDevShell.ps1' -Arch amd64 -HostArch amd64;"
'공대생의 팁' 카테고리의 다른 글
| MMOCR로 OCR 이해하기(2) - OCR 데이터셋 만들기 (0) | 2024.01.31 |
|---|---|
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
설정
트랙백
댓글
글
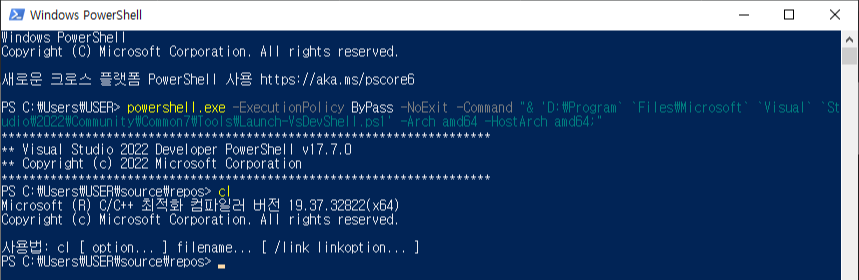
Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법
Visual Studio 에서 제공하는 MSVC를 Powershell에서 실행하기 위해 'Developer Powershell for VS 2022'를 실행하려 하는데 분명 바로가기 설정대로 명령어를 입력했음에도 실행이 되지 않는 문제가 발생하였다.
원인을 확인해보니 Powershell에서 경로명 사이에 스페이스 공백이 있을 때, 별개의 Command로 취급하는 바람에 발생하는 문제였다. 전체 경로명에 작은 따옴표 (')로 감싸줬더니 실행이 잘 되는 것을 확인하였다.
powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& Import-Module 'C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\Tools\Microsoft.VisualStudio.DevShell.dll'; Enter-VsDevShell cecdefe2;"
'공대생의 팁' 카테고리의 다른 글
| MMCV에서 사용되는 pretrained model 주소 알아내는 방법 (0) | 2023.11.05 |
|---|---|
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
| MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해 (0) | 2023.06.24 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
설정
트랙백
댓글
글
MMOCR로 OCR 이해하기(1) - OCR(STR)의 개념 이해
2023년은 생성 AI의 극적인 발전으로 실제 사람과 대화를 하는 듯이 답변을 하는 ChatGPT와 같은 생성형 인공지능이 등장하는 시대를 살아가고 있습니다. 심지어 GPT3.5를 뛰어넘은 GPT4가 ChatGPT에 적용되면서 생성형 인공지능의 성능은 더 빠르게 발전하는 양상을 보이는 가운데 지식 업무를 수행하는 화이트칼라 사무직들 조차 AI시대에 일자리를 뺏길 위기를 걱정을 하게 되는 세상이 도래하려나 싶은 생각이 드는 요즈음입니다.
다행히도(?) 사람처럼 현실세계에서 길거리의 간판을 쉽게 읽고 이해하는 로봇은 보이지 않는 듯 합니다. 분명 인공지능은 오직 사람만이 구현하리라 믿었던 상상력을 발휘하는 듯 함에도 현실 세계에서 이러한 기능을 실제 로봇에 구현하기에는 시간이 더 필요할 것으로 보입니다.

이번 포스팅에서는 인공지능이 현실세계에서 접할 수 있는 글씨들을 감지하고 이를 해석하는 장면 글자 인식(Scene Text Recognition, 혹은 광학 글자 인식 - Optical Text recognition)에 대해 이해하고 지금까지 공개된 글자 인식 알고리즘들을 총망라한 MMOCR에 대해 소개드리도록 하겠습니다.
사람의 도움 없이 스스로 글자를 읽는 기계?
OCR(Optical Character Recognition) 기술은 이름 그대로 광학 문자 인식 기술을 의미하며, 마치 사람이 글자를 이해하듯이 컴퓨터가 글씨를 사람처럼 읽을 수 있는 기술을 일컫는 말입니다.
딥러닝 기반 인공지능 기술이 활발하게 사용되고 있는 오늘날 관점에서 보면 놀랍게도 OCR 기술은 생각보다 오래전부터 연구된 분야입니다. 초창기의 OCR 기술은 글을 볼 수 없는 시각장애인들을 위해 종이에 적혀있는 글씨를 인식하는 기기에서 에서 시작되었습니다. 1913년, 아일랜드의 물리학자이자 화학자였던 에드먼드 에드워드 푸르니에 달베(Edmund Edward Fournier d'Albe, 1868년 – 1933년 6월 29일)가 발명한 옵토폰(Optophone)의해 OCR 기술이 처음으로 세상에 등장하였습니다.

옵토폰은 이름 그대로 빛을 소리로 바꾸어주는 기기로서 광학 센서에 의해 글자의 세로 두께에 해당되는 주파수를 내면 이를 사람이 듣고 어떤 글자인지 알 수 있는 방법으로 발명되었습니다.
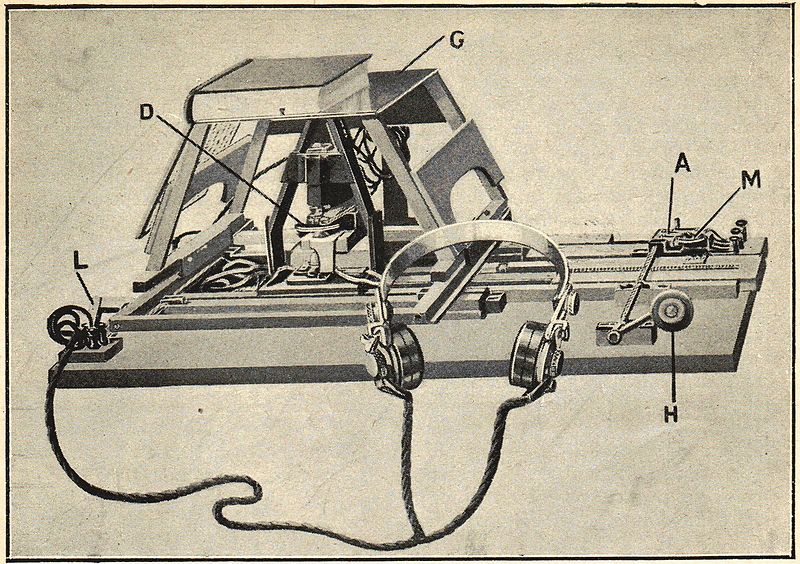
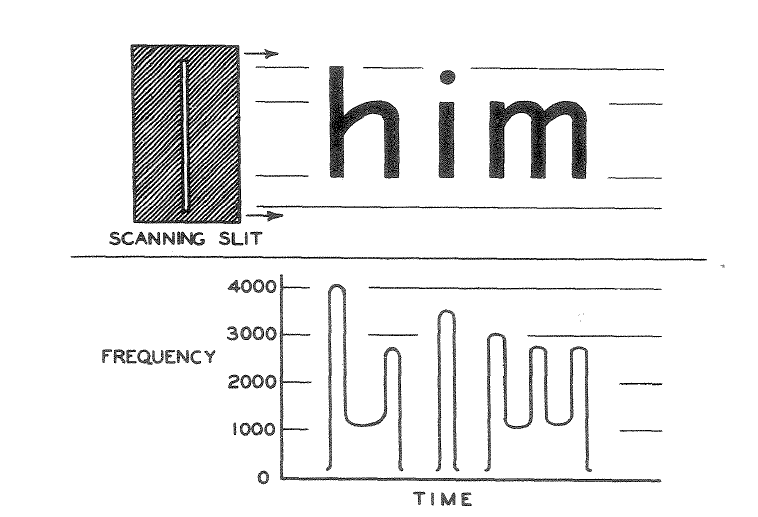
이후에도 인쇄물의 글자를 인식하는 기능들이 지속적으로 발전해왔으며, 오늘날 주로 사용되는 광학 문자 인식기는 로버트 노이스(Robert Norton Noyce, 1927년 12월 12일 - 1990년 6월 3일)가 1977년 발명한 OCR 리더기로서 그 모습을 갖추었습니다. 종이에 적힌 글자를 OCR 리더기로 스캔하면 컴퓨터에 해석된 글자를 전송하는 방식으로 동작하며, 손쉽게 책의 내용을 컴퓨터가 읽을 수 있는 시스템을 갖출 수 있게 되었습니다.

2023년 기준 최근에는 OCR Reader에 인공지능 번역 기능까지 갖춘 상품이 등장하였습니다. 책의 사진을 찍으면 인공지능 번역기로 번역을 해주던 기능은 기존에도 존재했지만 책을 촬영할때 빛과 손떨림 등으로 인해 초점이 맞지 않아 글자가 제대로 보이지 않는 문제점이 있지요. 이러한 단점을 OCR Reader를 사용하여 정확도를 높였고, OCR리더기를 사용하여 글자를 직접 스캔한 다음 이를 번역기에 넣어 돌린다는 아이디어는 상당히 참신해 보입니다.
MMOCR

MMOCR은 OpenMMLab에서 제작한 MM시리즈 중 하나로 공개된 OCR 알고리즘들을 통합한 프로젝트입니다. mmcv, mmdet 라이브러리와 mmocr 소스코드에 맞추어진 모델을 다운로드하여 명령어 단 한줄만으로 손쉽게 ocr을 경험해보실 수 있습니다.
MMOCR은 OCR 모델의 주요한 알고리즘인 Text Detection, Text Recognition을 제공합니다. Text Detection 과정을 통해 이미지에서 글자가 위치한 부분을 Segmentation 방식으로 표시하고, Recognition 단계에서는 Detection 과정에서 찾아낸 글자를 인식하는 과정을 거칩니다.

MMOCR에서 제공하는 예제를 실행하여 OCR의 원리를 빠르게 이해해봅니다. Github에서 MMOCR 소스코드를 다운로드합니다.
$ git clone https://github.com/open-mmlab/mmocr
MMOCR 소스코드를 다운로드한 다음 아래의 명령어를 입력하면 MMOCR에서 기본 설정한 OCR 모델이 자동으로 다운로드 되며 바로 실행되는 것을 확인하실 수 있습니다.
$ python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result
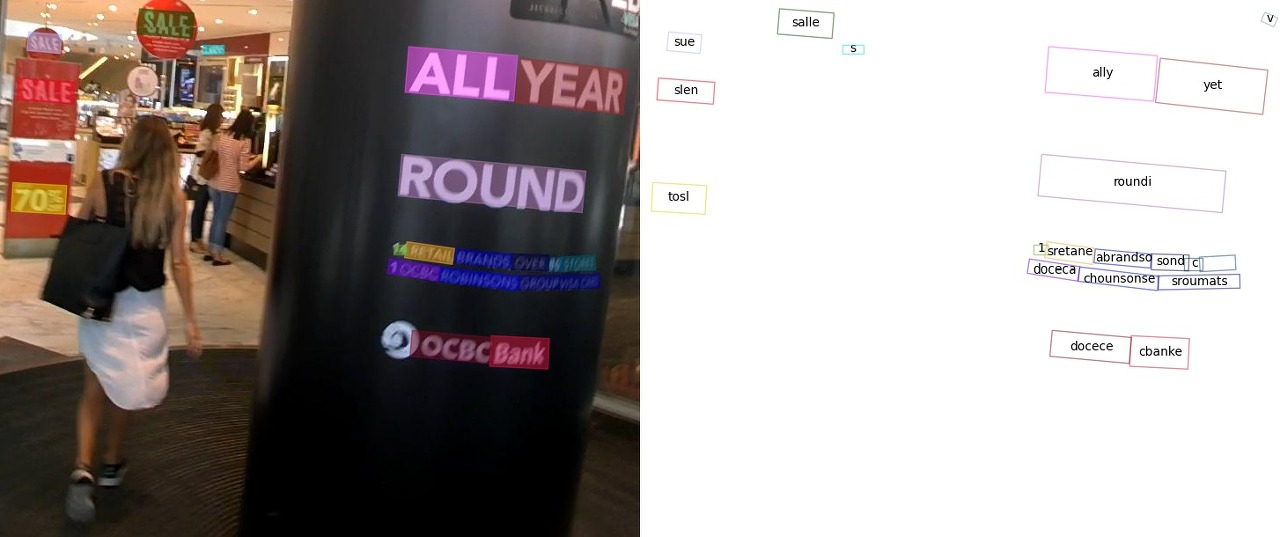
왼쪽의 사진은 이미지에서 글자의 위치를 찾아 표시하는 Text Detection, 오른쪽의 사진은 Text Detection 과정에서 찾은 Text의 글자를 해석하는 Text Recognition 과정을 나타내고 있습니다. 아래는 Text Recognition 결과를 Text로 출력되는 것을 보실 수 있습니다.
# Inference result
{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year',
'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores':
[...]}]}
'공대생의 팁' 카테고리의 다른 글
| PowerShell에서 Visual Studio x64 환경으로 개발하기 (0) | 2023.08.12 |
|---|---|
| Powershell 실행시 경로에 스페이스 공백이 있을 때 실행 방법 (0) | 2023.07.29 |
| AI로 Labeling을 자동으로 더 편하게 - AnyLabeling (0) | 2023.05.20 |
| Lableme로 Coco Dataset과 VOC Dataset 만들기 (0) | 2023.02.18 |
| 영상 및 이미지 인공지능 비전 알고리즘 오픈소스 - MMCV (0) | 2023.01.27 |
